
Distributed Training on AMD Instinct™ MI325X Clusters with dstack
dstack is an open-source orchestrator purpose-built for AI as a streamlined alternative to Kubernetes and Slurm. It simplifies the orchestration of AI workloads across both VM and bare metal AMD clusters, so teams can focus on model development, not infrastructure.
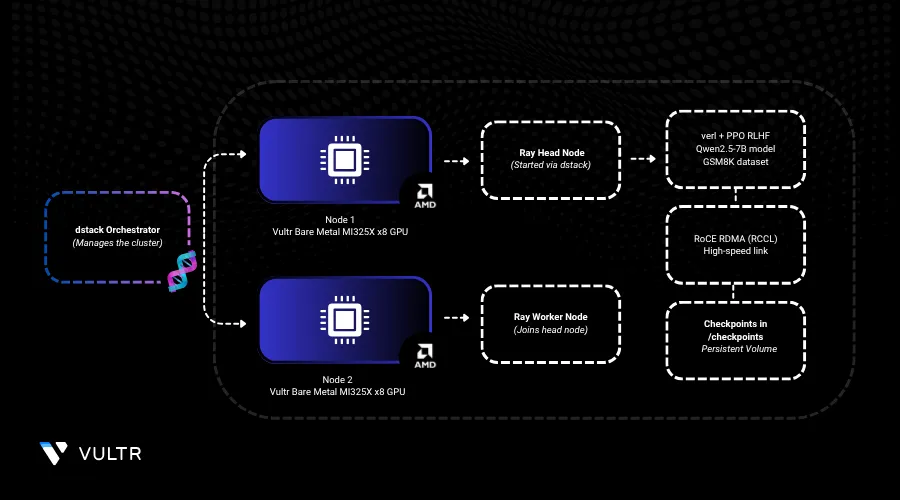
This guide demonstrates how to use dstack to orchestrate distributed training on a cluster of Vultr’s Bare Metal instances with AMD GPUs. While dstack allows using any distributed framework, this guide uses verl, an open-source framework for reinforcement learning training. The purpose is to train Qwen2.5-7B-Instruct to solve grade school math word problems using the GSM8K dataset, which features 8.5K problems requiring 2–8 reasoning steps.
Prerequisites
To begin, install dstack by following the installation instructions. Once dstack server is up you can initialize your workspace.
console$ mkdir dstack-verl-example && cd dstack-verl-example $ dstack init
Create a Fleet for Your AMD GPU Cluster
Create a
mi325x-fleet.dstack.ymlfile.console$ nano mi325x-fleet.dstack.yml
Copy and paste the below configuration.
yamltype: fleet name: mi325x-fleet.dstack.yml ssh_config: user: root identity_file: ~/.ssh/id_rsa hosts: - 144.202.58.28 - 137.220.58.52
Under
hosts, hostnames of the cluster nodes are listed.Save and close the file.
Apply the fleet configuration.
console$ dstack apply -f mi325x-fleet.dstack.yml
While creating a fleet, dstack automatically detects AMD GPUs and checks drivers on each node. Once the fleet is created, it's marked as idle and can be used for running dev environments, tasks, and services.
Validate Interconnect with RCCL tests
Before training, it’s important to validate multi-GPU and inter-node communication. dstack makes it convenient to launch RCCL tests across your cluster using a task.
Create
rccl-tests.dstack.ymlfile for distributed task configuration.console$ nano rccl-tests.dstack.yml
Copy and paste the below configuration.
yamltype: task name: rccl-tests nodes: 2 startup_order: workers-first stop_criteria: master-done volumes: - /usr/local/lib:/mnt/lib image: rocm/dev-ubuntu-22.04:6.4-complete env: - NCCL_DEBUG=INFO - OPEN_MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi commands: - export LD_PRELOAD=/mnt/lib/libbnxt_re-rdmav34.so - apt-get install -y git libopenmpi-dev openmpi-bin - git clone https://github.com/ROCm/rccl-tests.git - cd rccl-tests - make MPI=1 MPI_HOME=$OPEN_MPI_HOME - | if [ $DSTACK_NODE_RANK -eq 0 ]; then mpirun --allow-run-as-root \ --hostfile $DSTACK_MPI_HOSTFILE \ -n $DSTACK_GPUS_NUM \ -N $DSTACK_GPUS_PER_NODE \ --mca btl_tcp_if_include ens41np0 \ -x LD_PRELOAD \ -x NCCL_IB_HCA=bnxt_re0,... \ -x NCCL_IB_GID_INDEX=3 \ -x NCCL_IB_DISABLE=0 \ ./build/all_reduce_perf -b 8M -e 8G -f 2 -g 1 -w 5 --iters 20 -c 0; else sleep infinity fi resources: gpu: MI325X:8
- This YAML file defines a dstack task to run RCCL performance tests on a 2-node AMD MI325X GPU cluster.
- It installs MPI and builds the RCCL test suite on the master node.
- The master node then launches an mpirun command to run all_reduce_perf across all GPUs.
- RDMA libraries are preloaded to enable high-speed interconnects.
- Worker nodes simply sleep to stay active while the test runs.
Save and close the file.
Run the task using the
dstack applycommand.console$ dstack apply -f rccl-tests.dstack.yml
As the task runs, you’ll see the output of RCCL tests showing the bandwidth between the GPU and nodes.
Launch a Ray Cluster for Training
dstack tasks allow you to run any distributed workload directly using torch run, accelerate, or other distributed frameworks. However, because verl requires Ray, we need to launch a Ray cluster as a task before submitting Ray jobs.
Create a
ray-cluster.dstack.ymlto launch Ray cluster on the fleet.console$ nano ray-cluster.dstack.yml
Copy and paste the below configuration.
yamltype: task name: ray-cluster-ppo nodes: 2 env: - NCCL_DEBUG=TRACE - GPU_MAX_HW_QUEUES=2 - TORCH_NCCL_HIGH_PRIORITY=1 - NCCL_CHECKS_DISABLE=1 - NCCL_IB_HCA=bnxt_re0,... - NCCL_IB_GID_INDEX=3 - NCCL_CROSS_NIC=0 - CUDA_DEVICE_MAX_CONNECTIONS=1 - NCCL_PROTO=Simple - RCCL_MSCCL_ENABLE=0 - TOKENIZERS_PARALLELISM=false - HSA_NO_SCRATCH_RECLAIM=1 - HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 - ROCR_VISIBLE_DEVICES=$HIP_VISIBLE_DEVICES - CUDA_VISIBLE_DEVICES=$HIP_VISIBLE_DEVICES - MODEL_PATH=Qwen/Qwen2.5-7B-Instruct - train_files=../data/gsm8k/train.parquet - test_files=../data/gsm8k/test.parquet image: verl-rocm commands: - export LD_PRELOAD=/mnt/lib/libbnxt_re-rdmav34.so - pip install hf_transfer hf_xet - | if [ $DSTACK_NODE_RANK = 0 ]; then python3 examples/data_preprocess/gsm8k.py --local_dir ~/data/gsm8k python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-7B-Instruct')" ray start --head --port=6379; else ray start --address=$DSTACK_MASTER_NODE_IP:6379 fi ports: - 8265 resources: gpu: MI325X:8 shm_size: 24GB volumes: - /checkpoints:/checkpoints - /usr/local/lib:/mnt/lib
You will need to build the verl-rocm Docker image as described in AMD’s ROCm blog.NoteSave and close the file.
Run the task using the
dstack applycommand.console$ dstack apply -f ray-cluster.dstack.yml
When the task exposes ports, the
dstack applycommand automatically forwards these ports to the current machine. In our case, this makes the Ray's dashboard available locally atlocalhost:8265.
Submit the Training Job via Ray
Install Ray locally.
console$ pip install ray
Submit the traning job.
RAY_ADDRESS=http://localhost:8265 python3 -m verl.trainer.main_ppo \ data.train_files=$train_files \ data.val_files=$test_files \ data.train_batch_size=1024 \ data.max_prompt_length=1024 \ data.max_response_length=1024 \ actor_rollout_ref.model.path=$MODEL_PATH \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.actor.ppo_mini_batch_size=256 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=8 \ actor_rollout_ref.actor.fsdp_config.param_offload=False \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=16 \ actor_rollout_ref.rollout.tensor_model_parallel_size=2 \ actor_rollout_ref.rollout.name=vllm \ actor_rollout_ref.rollout.gpu_memory_utilization=0.9 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=16 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ critic.optim.lr=1e-5 \ critic.model.use_remove_padding=True \ critic.model.path=Qwen/Qwen2.5-7B-Instruct \ critic.model.enable_gradient_checkpointing=False \ critic.ppo_micro_batch_size_per_gpu=8 \ critic.model.fsdp_config.param_offload=False \ critic.model.fsdp_config.optimizer_offload=False \ algorithm.kl_ctrl.kl_coef=0.0001 \ trainer.critic_warmup=0 \ trainer.logger=[console] \ trainer.project_name='verl_example' \ trainer.experiment_name='Qwen2.5-7B-PPO' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=2 \ trainer.default_local_dir=/checkpoints \ trainer.val_before_train=False \ trainer.save_freq=10 \ trainer.test_freq=10 \ trainer.total_epochs=15Monitor GPU metrics.
console$ dstack metrics -w ray-cluster-ppo
Monitoring GPU utilization and cluster health is crucial during training. dstack provides real-time metrics through both CLI and dashboard. Additionally, monitoring metrics is possible also via dstack server’s UI dashboard.
RoCE Compatibility and Checkpoint Recovery
Broadcom RoCE drivers require the libbnxt_re userspace library inside the container to be compatible with the host’s Broadcom kernel driver bnxt_re. To ensure this compatibility, we mount libbnxt_re-rdmav34.so from the host and preload it using LD_PRELOAD when running MPI.
All training checkpoints are saved to an instance volume, enabling seamless recovery in case of interruptions or node failures.
Conclusion
Leveraging AMD Instinct™ MI325X GPUs, ROCm, and dstack enables seamless, scalable, and high-performance distributed LLM training across your fleet. With dstack, you can avoid the operational complexity of managing infrastructure with Kubernetes or Slurm.
For more information:
- dstack Distributed tasks
- datack SSH fleets
- dstack’s Clusters guide
- Verl on ROCm blog