Exploring Vultr GPU Stack | Generative AI Series

Introduction
Llama 2 is an open-source large language model from Hugging Face. You can use the model in your application to perform natural language processing (NLP) tasks.
The Vultr GPU Stack is a preconfigured compute instance with all the essential components for developing and deploying AI and ML applications. In this tutorial, you'll explore the Vultr GPU Stack environment and run a Llama 2 model in a Docker container.
Prerequisites
Before you begin:
Deploy a new Ubuntu 22.04 A100 Vultr Cloud GPU Server with at least:
- 80 GB GPU RAM
- 12 vCPUs
- 120 GB Memory
Create a non-root user with
sudorights and switch to the account.
Explore the Vultr GPU Stack environment
The Vultr GPU stack has many packages that simplify AI model development. Follow the steps below to ensure your environment is up and running:
Check the configuration of the NVIDIA GPU server by running the
nvidia-smicommand.console$ nvidia-smiConfirm the following output.
output+-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.125.06 Driver Version: 525.125.06 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 GRID A100D-4C On | 00000000:06:00.0 Off | 0 | | N/A N/A P0 N/A / N/A | 0MiB / 4096MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
The above output confirms that the NVIDIA driver is up and running and the GPU is accessible from the OS. The output also shows that the instance has an
A100 GPUattached.Inspect the docker runtime environment by running the following commands:
Check the Docker version.
console$ sudo docker version
Output.
Client: Docker Engine - Community Version: 24.0.7 API version: 1.43 Go version: go1.20.10 Git commit: afdd53b Built: Thu Oct 26 09:07:41 2023 OS/Arch: linux/amd64 Context: default Server: Docker Engine - Community Engine: Version: 24.0.7 API version: 1.43 (minimum version 1.12) Go version: go1.20.10 Git commit: 311b9ff Built: Thu Oct 26 09:07:41 2023 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.6.24 GitCommit: 61f9fd88f79f081d64d6fa3bb1a0dc71ec870523 runc: Version: 1.1.9 GitCommit: v1.1.9-0-gccaecfc docker-init: Version: 0.19.0 GitCommit: de40ad0Display the Docker system information.
console$ sudo docker info
Output.
Client: Docker Engine - Community Version: 24.0.7 Context: default Debug Mode: false Plugins: buildx: Docker Buildx (Docker Inc.) Version: v0.11.2 Path: /usr/libexec/docker/cli-plugins/docker-buildx compose: Docker Compose (Docker Inc.) Version: v2.21.0 Path: /usr/libexec/docker/cli-plugins/docker-compose Server: ... Runtimes: runc io.containerd.runc.v2 nvidia Default Runtime: runc ... Docker Root Dir: /var/lib/docker Debug Mode: false Experimental: false Insecure Registries: 127.0.0.0/8 Live Restore Enabled: false
The above output omits some settings for brevity. However, the critical aspect is the availability of the NVIDIA container runtime, which enables Docker containers to access the underlying GPU.
Run an Ubuntu image and execute the
nvidia-smicommand within the container.console$ sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Output.
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.125.06 Driver Version: 525.125.06 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 GRID A100D-4C On | 00000000:06:00.0 Off | 0 | | N/A N/A P0 N/A / N/A | 0MiB / 4096MiB | 0% Default | | | | Disabled | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+The above output confirms that Docker containers have access to the GPU. In the next step, you'll run
LLama2through a container.
Run Llama2 Model on a Vultr GPU Stack
In this step, you'll launch the Hugging Face Text Generation Inference container to expose the Llama-2-7b-chat-hf parameter model through an API. Follow the steps below:
Fill out the Llama 2 model request form.
Use the same email address to sign up for a Hugging Face account and create an access token.
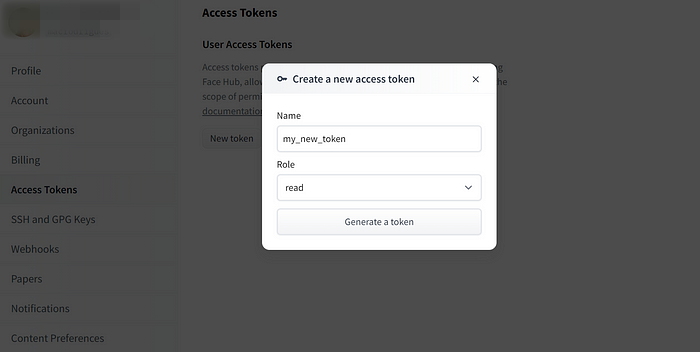
Run the following command on your
SSHinterface to initialize some environment variables. ReplaceYOUR_HF_TOKENwith the correct Hugging Face token.consolemodel=meta-llama/Llama-2-7b-chat-hf volume=$PWD/data token=YOUR_HF_TOKEN
Create a
datadirectory to store the model's artifacts in your home directory.console$ mkdir data
Run the command below to launch the
ghcr.io/huggingface/text-generation-inference:1.1.0Docker container and initialize the Llama 2 model.console$ sudo docker run -d \ --name hf-tgi \ --runtime=nvidia \ --gpus all \ -e HUGGING_FACE_HUB_TOKEN=$token \ -p 8080:80 \ -v $volume:/data \ ghcr.io/huggingface/text-generation-inference:1.1.0 --model-id $model
Output.
Digest: sha256:55...45871608f903f7f71d7d Status: Downloaded newer image for ghcr.io/huggingface/text-generation-inference:1.1.0 78a39...f3e1dca928e00f859Wait for the container to start and check the logs.
console$ sudo docker logs -f hf-tgi
The last few lines below indicate the host is now listening to incoming HTTP connections, and the API is ready.
... ...Connected ...Invalid hostname, defaulting to 0.0.0.0Run the following
curlcommand to query the API.console$ curl 127.0.0.1:8080/generate \ -X POST \ -d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":128}}' \ -H 'Content-Type: application/json'
Output.
json{"generated_text":"\n\nDeep learning (also known as deep structured learning) is part of a broader family of machine learning techniques based on artificial neural networks—specifically, on the representation and processing of data using multiple layers of neural networks. Learning can be supervised, semi-supervised, or unsupervised.\n\nDeep-learning architectures such as Deep Neural Networks, Deep Belief Networks, and Deep Reinforcement Learning have been applied to fields including visual recognition, natural language processing, speech recognition, and expert system.\n\nDeep learning has been described as a \"paradigm shift\""}
The output confirms that the LLM is running.
Query the Llama2 Model Using Jupyter Notebook
Use the Python client to invoke the model from a Jupyter Notebook by following the steps below:
Install the HF Text Generation client by running the command below.
console$ pip install text-generation
Run the Jupyter Lab and retrieve the access
token.$ jupyter lab --ip 0.0.0.0 --port 8890Output.
http://YOUR_SERVER_HOST_NAME:8890/lab?token=b7ab2bdscb366edsddssfsff0faeb5fa68b6b0cfAllow port
8890through the firewall.console$ sudo ufw allow 8890 $ sudo ufw reload
Access the Jupyter Lab on a browser and replace
YOUR_SERVER_IPwith the public IP address of the GPU instance.https://YOUR_SERVER_IP:8888/lab?token=YOUR_JUPYTER_LAB_TOKENClick Python 3 ipykernel under Notebook and paste the following Python code.
pythonfrom text_generation import Client URI='http://localhost:8080' tgi_client = Client(URI) prompt='What is the most important tourist attraction in Paris?' print(tgi_client.generate(prompt, max_new_tokens=100).generated_text.strip())
Run the above code. The LLM responds to your query and displays the following response.
Paris, the City of Light, is known for its iconic landmarks, cultural institutions, and historical significance. As one of the most popular tourist destinations in the world, Paris has a plethora of attractions that draw visitors from all over the globe. While opinions may vary, some of the most important tourist attractions in Paris include: 1. The Eiffel Tower: The most iconic symbol of Paris, the Eiffel Tower
Conclusion
This tutorial walked you through running the LLama 2 model in a container on the Vultr GPU Stack. In the next section, you'll explore other advanced LLM models.
- Generative AI for Developers | Generative AI Series
- Understanding Foundation Models | Generative AI Series
- Exploring Vultr GPU Stack | Generative AI Series
- A Deeper Dive Into Large Language Models | Generative AI Series
- Interacting with Llama 2 | Generative AI Series
- Implementing RAG with Chroma and Llama 2 | Generative AI Series
- Using LangChain with Llama 2 | Generative AI Series
- Fine-Tuning Llama 2 | Generative AI Series
- Generating Images with Stable Diffusion | Generative AI Series
- Transcribing and Translating Audio | Generative AI Series