
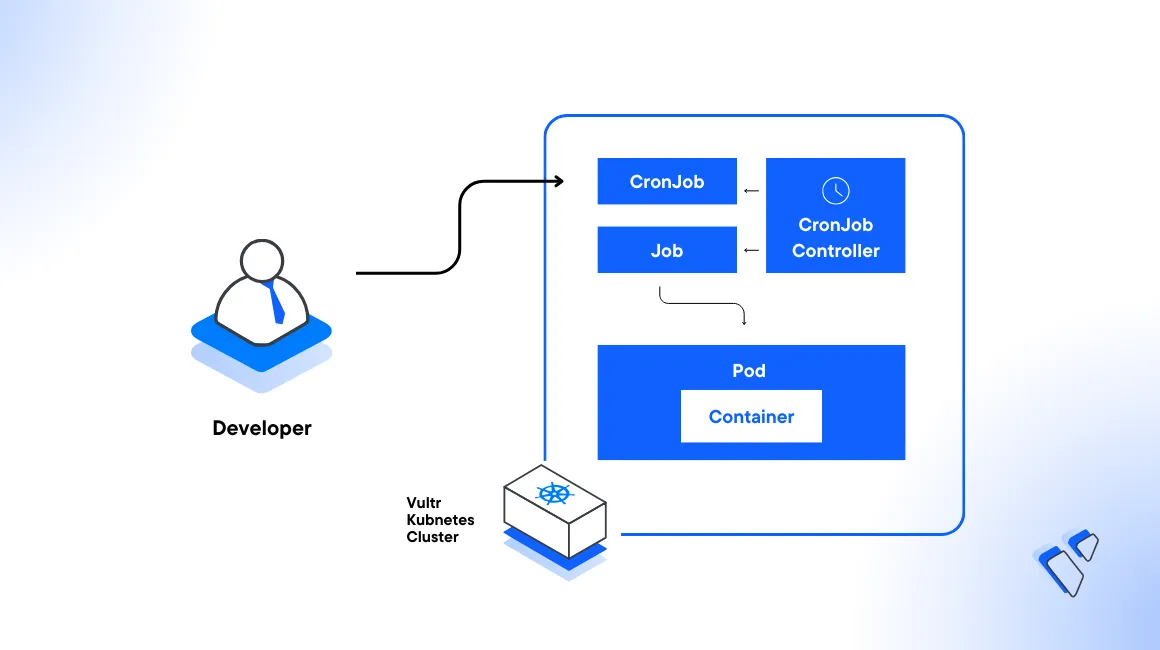
Introduction
Kubernetes CronJobs allow you to execute commands at specified times, dates, or intervals. A CronJob creates Jobs on a repeated schedule, and these Jobs are Kubernetes objects that represent one or multiple containerized tasks that run to completion. A typical use case may include backup operations, sending emails, or running cleanup scripts. With CronJobs, you can automate multiple tasks directly within your cluster to ensure consistent configurations and improve scalability.
This article explains how to create and manage Kubernetes CronJobs in a Vultr Kubernetes Engine (VKE) cluster. You are to set up multiple CronJobs and perform different tasks to use the available control policies.
Prerequisites
Before you begin:
- Deploy a Vultr Kubernetes Engine (VKE) cluster.
- Deploy a Vultr Ubuntu server to use as the management workstation.
- Access the server using SSH as a non-root sudo user.
- Install and Configure Kubectl to access the cluster.
Cron Syntax
Kubernetes CronJobs use schedule expressions based on the standard Cron format that represents time intervals at which a Job is executed. Expressions are divided into five fields that are separated by spaces. Each field represents a different part of the schedule and a valid expression must include the following values:
Minute when the task runs (
0 to 59)Hour (
0 to 23)Day of the month when the task runs (
1 to 31)Month (
1 to 12)Day of the week (
0 to 6, orSUN,MON,TUE, and so on)# ┌───────────── minute (0 - 59) # │ ┌───────────── hour (0 - 23) # │ │ ┌───────────── day of the month (1 - 31) # │ │ │ ┌───────────── month (1 - 12) # │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday, OR sun, mon, tue, wed, thu, fri, sat) # │ │ │ │ │ # │ │ │ │ │ # │ │ │ │ │ # * * * * *
Below are examples of valid Cron expressions that run a task depending on the set value:
* * * * *: Every minute30 6 * * *: Every day at 6:30 AM*/10 * * * *: Every 10 minutes45 16 1 * *: Runs the task at4:45PM on the first day of every month0 0 * * 0: Runs the task at midnight every Sunday*/5 * * * 1-5: Every 5 minutes on weekdays (Monday to Friday)0 0 1 1 *: Runs the task at midnight on January 1st
Create a Kubernetes CronJob
To implement Kubernetes CronJobs, create a sample CronJob that runs a container creation task that follows a specific schedule as described in the steps below.
Create a new Cronjob YAML file
cron-job.yamlusing a text editor such as Nano.console$ nano cron-job.yaml
Add the following contents to the file.
yamlapiVersion: batch/v1 kind: CronJob metadata: name: example-cronjob spec: schedule: "*/2 * * * *" jobTemplate: spec: template: spec: containers: - name: busybox image: busybox:latest command: - /bin/sh - -c - echo 'Hello World '; date restartPolicy: OnFailure
Save and close the file.
The above configuration creates a new CronJob that runs a
busyboxcontainer which prints aHello Worldprompt to the console. The task runs every2minutes as declared by the*/2 * * * *Cron expression:Apply the CronJob to your cluster.
console$ kubectl apply -f cron-job.yaml
Manage Kubernetes CronJobs
View all cluster CronJobs.
console$ kubectl get cronjobs
Output:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE example-cronjob */2 * * * * False 0 26s 49sView all jobs created from CronJob tasks.
console$ kubectl get jobs
Output:
NAME COMPLETIONS DURATION AGE example-cronjob-28398856 1/1 4s 81sView jobs created by a specific CronJob. For example,
example-cronjob.console$ kubectl get jobs -l cron-job-name=example-cronjob
To manually create a new job using your existing CronJob, for example,
example-job, run the following command:console$ kubectl create job --from=cronjob/example-cronjob example-job
View the job container logs to verify the ongoing processes. For example, view the
example-joblogs.console$ kubectl logs job/example-job
Output:
Hello World Sat Dec 30 10:18:50 UTC 2023
Pause a Kubernetes CronJob
To pause the execution process of a Kubernetes CronJob, set the spec.suspend field to true. When paused, future CronJobs won't execute unless started again. However, existing jobs are not affected by the main Cron execution changes. In this section, pause the example-cronjob resource you created earlier as described in the steps below.
Patch your target CronJob using Kubectl and set the
spec.suspendvalue totrue.console$ kubectl patch cronjob/example-cronjob -p '{"spec": {"suspend": true}}'
Output:
cronjob.batch/example-cronjob patchedView available CronJobs and verify the SUSPEND value attached to your target resource.
console$ kubectl get cronjobs
Output:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE example-cronjob */2 * * * * True 0 92s 7m55sAs displayed in the above output, the
example-cronjobexecution process is paused. When the SUSPEND value is set toFalse, the CronJob runs normally.To start the CronJob again, modify the specification value back to
false.console$ kubectl patch cronjob/example-cronjob -p '{"spec": {"suspend": false}}'
Set Up CronJob Policies
CronJob policies allow you to modify the behavior of CronJobs within your cluster. This allows you to control multiple jobs, set up execution deadlines, and the restart procedure depending on your set policies which include the following:
Concurrency Policy: Manages active Jobs simultaneously attached to the same CronJob. It's controlled using the
.spec.concurrencyPolicyfield and accepts the following values:Allow: Enables multiple Jobs to run at the same timeForbid: Disables concurrently running jobs. If a specific job fails to complete, the next Job does not startReplace: Ensures that before starting the next scheduled job, any existing running job stops and replaces it with the new job
Starting Deadline Mechanism: Specifies the amount of time in seconds that acts as a deadline to start the CronJob.
Job History Limits: Sets the CronJob execution history with the following values:
spec.successfulJobsHistoryLimit: Sets the number of completed jobs to keep in memory.spec.failedJobsHistoryLimit: Sets the number of failed Jobs to keep in memory.
Backoff Limit: Sets the number of times a failed Job should restart. By default, it's set to 6. If a Job fails after 6 restarts, it's marked as failed.
Active Deadline Seconds: Sets the maximum duration a Job can run. When the time limit expires, the job terminates. For example, if you set the execution deadline to
3600, the Job can run for up to1hour (3600 seconds). After1hour, Kubernetes stops the job. This is important when a job is stuck or takes long to complete.
To implement CronJob policies, modify your target rules within the resource definition file. For example, create a new jobpolicy.yaml file.
$ nano jobpolicy.yaml
Add the following contents to the file.
apiVersion: batch/v1
kind: CronJob
metadata:
name: example-cronjob-2
spec:
schedule: "*/5 * * * *"
concurrencyPolicy: Forbid
startingDeadlineSeconds: 300
jobTemplate:
spec:
backoffLimit: 3
activeDeadlineSeconds: 1800
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: busybox
image: busybox:latest
command:
- /bin/sh
- -c
- date
restartPolicy: OnFailure
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 3
Save and close the file.
The code above uses the following policies:
concurrencyPolicy: Set toForbidto avoid concurrent executionsstartingDeadlineSeconds: Sets300seconds as the maximum time allowed for a Job to startbackoffLimit: Limits the maximum number of times,3, to retry failed JobsactiveDeadlineSeconds: Limits the maximum runtime for a single Job to1800secondssuccessfulJobsHistoryLimit: Sets the maximum number of completed job instances to preserve to5failedJobsHistoryLimit: Sets the number of failed Job instances to preserve to3
Example: Create a MySQL Database Backup CronJob
Encode a new strong MySQL access password using base64.
console$ echo -n 'strong-password' | base64
Copy the generated password string to your clipboard.
Create a new Secret resource file
mysql-secret.yamlto store the MySQL root user password.console$ nano mysql-secret.yaml
Add the following contents to the file. Replace
hashed-passwordwith your actual base64 encoded password value.yamlapiVersion: v1 kind: Secret metadata: name: mysql-db-credentials type: Opaque data: MYSQL_ROOT_PASSWORD: hashed-password
Save and close the file.
Apply the Secret to your cluster.
console$ kubectl apply -f mysql-secret.yaml
Create a new PVC resource file
pvc.yamlto set Vultr Block Storage as the MySQL data storage method.console$ nano pvc.yaml
Add the following contents to the file.
yamlapiVersion: v1 kind: PersistentVolumeClaim metadata: name: mysql-backup-pv-claim spec: accessModes: - ReadWriteOnce resources: requests: storage: 40Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mysql-pv-claim spec: accessModes: - ReadWriteOnce resources: requests: storage: 40Gi
Save and close the file.
The above configuration creates two Kubernetes PersistentVolumeClaims (PVCs)
mysql-backup-pv-claimandmysql-pv-claimusing Vultr Block Storage. Both volumes consist of40 GBwith aReadWriteOnceaccess mode that allows the volume to be mounted as read-write by a single node.Apply the resource to your cluster.
console$ kubectl apply -f pvc.yaml
View the cluster PVCs to verify that the new resources are available.
console$ kubectl get pvc
Output:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mysql-backup-pv-claim Bound pvc-5095c0a035754f1e 40Gi RWO vultr-block-storage 10s mysql-pv-claim Bound pvc-48284eae3adf445b 40Gi RWO vultr-block-storage 10sCreate a new MySQL resource file
mysql.yaml.console$ nano mysql.yaml
Add the following contents to the file.
yamlapiVersion: apps/v1 kind: Deployment metadata: name: mysql-deployment spec: replicas: 1 selector: matchLabels: app: mysql template: metadata: labels: app: mysql spec: containers: - name: mysql image: mysql:5.7 env: - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-db-credentials key: MYSQL_ROOT_PASSWORD - name: MYSQL_DATABASE value: "mydatabase" ports: - containerPort: 3306 volumeMounts: - name: mysql-persistent-storage mountPath: /var/lib/mysql volumes: - name: mysql-persistent-storage persistentVolumeClaim: claimName: mysql-pv-claim --- apiVersion: v1 kind: Service metadata: name: mysql-service spec: selector: app: mysql ports: - protocol: TCP port: 3306 targetPort: 3306
Save and close the file.
The above configuration consists of a MySQL database Deployment and a Service to run in your cluster on the default port
3306. TheMYSQL_ROOT_PASSWORDvariable uses the base64 password available in your cluster Secret resource. Together, the configuration creates a MySQL deployment with a persistent storage volume and a service that provides a stable endpoint for accessing the database within the cluster.Apply the MySQL resources to your cluster.
console$ kubectl apply -f mysql.yaml
View the cluster deployments and verify that your MySQL resource is available.
console$ kubectl get deployments
Output:
NAME READY UP-TO-DATE AVAILABLE AGE mysql-deployment 1/1 1 1 2mCreate a new CronJob resource file
mysql-cronjob.yaml.console$ nano mysql-cronjob.yaml
Add the following contents to the file.
yamlapiVersion: batch/v1 kind: CronJob metadata: name: db-backup-cronjob spec: schedule: "0 2 * * *" concurrencyPolicy: Replace startingDeadlineSeconds: 100 jobTemplate: spec: template: spec: containers: - name: db-backup image: mysql:5.7 env: - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-db-credentials key: MYSQL_ROOT_PASSWORD - name: MYSQL_HOST value: "mysql-service" args: - "/bin/bash" - "-c" - "mysqldump -h ${MYSQL_HOST} -u root -p${MYSQL_ROOT_PASSWORD} --all-databases | gzip > /backup/all-databases-$(date +%Y-%m-%d_%H%M%S).sql.gz" volumeMounts: - name: backup-volume mountPath: /backup restartPolicy: OnFailure volumes: - name: backup-volume persistentVolumeClaim: claimName: mysql-backup-pv-claim
The above configuration creates a new Kubernetes CronJob
db-backup-cronjobthat runs every day at2:00 AMas set with the expression0 2 * * *and the following policies:concurrencyPolicy: Replace: Specifies that when an existing backup job is running, the new job replaces the active jobstartingDeadlineSeconds: 100: Terminates the job if the starting time exceeds100seconds- Within the
jobTemplate:- The container creates a dump of all databases using
mysqldump, compresses the output withgzip, and saves it to the/backupdirectory with a filename that includes the cluster date and time restartPolicy: OnFailure: Specifies that the Job should restart the container on-failurebackup-volumeis mounted to the/backupdirectory within the container which usesmysql-backup-pv-claimfor storage to persistently back up files.
- The container creates a dump of all databases using
Apply the new CronJob to your cluster.
console$ kubectl apply -f mysql-cronjob.yaml
View the cluster Cronjobs and verify that the new resource is available
console$ kubectl get cronjobs
Output:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE db-backup-cronjob 0 2 * * * False 0 <none> 16sCreate a new MySQL data file
example-data.sql.console$ nano example-data.sql
Add the following contents to the file.
sqlUSE mydatabase; CREATE TABLE people ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) NOT NULL, age INT NOT NULL ); INSERT INTO people (name, age) VALUES ('Alice', 30); INSERT INTO people (name, age) VALUES ('Bob', 25); INSERT INTO people (name, age) VALUES ('Carol', 27);
Save and close the file.
The above script uses the database
mydatabaseto creates a new MySQL tablepeople. Then, the table is populated with sample data values in 3 columns.View the cluster Pods and keep note of the MySQL database pod name.
console$ kubectl get pods
Your output should look like the one below:
NAME READY STATUS RESTARTS AGE mysql-deployment-cc487f97b-4k9n2 1/1 Running 0 26mCopy your MySQL Pod name to your clipboard to use when testing the script. For example,
mysql-deployment-cc487f97b-4k9n2.Copy the MySQL data file to the
/tmp/directory within your MySQL Pod. Replacemysql-deployment-cc487f97b-4k9n2with your actual Pod name.console$ kubectl cp example-data.sql mysql-deployment-cc487f97b-4k9n2:/tmp/example-data.sql
When successful, enter the MySQL Pod shell.
console$ kubectl exec -it mysql-deployment-cc487f97b-4k9n2 -- /bin/bash
Import the MySQL data file from the
/tmpdirectory to populate your target databasemydatabasewith the sample data.console# mysql -u root -p$MYSQL_ROOT_PASSWORD mydatabase < /tmp/example-data.sql
When successful, exit the shell.
console# exit
Manually create a new job using the main
db-backup-cronjob.console$ kubectl create job --from=cronjob/db-backup-cronjob manual-job
Wait at least
1minute to create the new job, then, view the cluster jobs.console$ kubectl get jobs/manual-job
Output:
NAME COMPLETIONS DURATION AGE job 1/1 3s 57sVerify that the COMPLETIONS includes a
1/1value to confirm that the new job is ready.Create a new MySQL backup query Pod file
backup-check-pod.yaml.console$ nano backup-check-pod.yaml
Add the following contents to the file.
yamlapiVersion: v1 kind: Pod metadata: name: backup-check-pod spec: volumes: - name: backup-volume persistentVolumeClaim: claimName: mysql-backup-pv-claim containers: - name: busybox image: busybox command: ['sh', '-c', 'echo "Backup Check Pod Running"; sleep 3600'] volumeMounts: - name: backup-volume mountPath: /backup
Save and close the file.
The above configuration creates a new Pod that runs the
busyboxcontainer which expires after3600seconds.Apply the Pod to your cluster.
console$ kubectl apply -f backup-check-pod.yaml
Wait at least
1minute for the pod to finish creating, then, access the Pod shell.console$ kubectl exec -it backup-check-pod -- /bin/sh
Switch to the
backupdirectory.console# cd /backup
List files in the directory and keep note of your MySQL backup archive name.
console# ls -l
Output:
total 776 -rw-r--r-- 1 root root 791801 Dec 30 19:55 all-databases-2023-12-30_195511.sql.gzCopy the MySQL backup filename. For example
all-databases-2023-12-30_195511.sql.gzto extract contents from the file.Extract all files from the compressed archive to a new file
extracted_backup.sqlusing the Gzip utility.console# gzip -d -c database-backup-2023-11-25_200928.sql.gz > extracted_backup.sql
View the contents of the extracted file.
console# cat extracted_backup.sql
When your MySQL CronJob is successful, your output should look like the one below:
-- -- Current Database: `mydatabase` -- CREATE DATABASE /*!32312 IF NOT EXISTS*/ `mydatabase` /*!40100 DEFAULT CHARACTER SET latin1 */; USE `mydatabase`; -- -- Table structure for table `people` -- -- Dumping data for table `people` -- LOCK TABLES `people` WRITE; /*!40000 ALTER TABLE `people` DISABLE KEYS */; INSERT INTO `people` VALUES (1,'Alice',30),(2,'Bob',25),(3,'Carol',27); /*!40000 ALTER TABLE `people` ENABLE KEYS */; UNLOCK TABLES; /*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */; /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */; -- Dump completed on 2023-12-30 19:55:12Exit the shell.
console# exit
Conclusion
You have created and managed Kubernetes CronJobs to automatically schedule tasks within your cluster. You can set up various CronJob policies to further customize your CronJobs behavior and functionalities. For more information, visit the Kubernetes CronJobs documentation.
No comments yet.