
Deploy a Vultr Server with Cloud-Init User-Data

What is cloud-init?
Cloud-init is a service that customizes Linux-based cloud servers. It's supported by most Linux distributions and public cloud vendors, and it's the industry standard to initialize cloud virtual machines. Canonical created cloud-init more than a decade ago for Ubuntu, and since then, all major public clouds and most Linux distributions have added support for cloud-init.
Why did Vultr switch to cloud-init?
Before 2022, Vultr used proprietary scripts called imageboot to deploy server instances. These scripts set the IP address, hostname, root password, and other requirements when you deploy a server.
Vultr's BSD and Windows images still use imageboot scripts. If you use those operating systems, please see our startup script quickstart guide.
Although these scripts were powerful, they weren't compatible with other public cloud providers and didn't meet the needs of our new products like Marketplace, VKE, Managed Databases and Vultr Cloud GPU.
To solve this, we worked with Canonical to add the Vultr datasource to cloud-init, and after extensive in-house testing, we added cloud-init support to our Linux images.
This guide explains the benefits of cloud-init and how to use it, with examples for common tasks. This isn't a comprehensive guide to all cloud-init features. Please see the official documentation to learn about cloud-init's full capabilities.
Advantages of cloud-init
You'll discover several advantages when you start using cloud-init. First, it's portable. If you developed scripts at another public cloud, you could deploy those at Vultr without changes. You can also do many things with cloud-init that aren't easy to do with imageboot scripts, like:
- You can override Vultr's vendor-data with your user-data.
- You can inject shell scripts that run once per boot or once per instance.
- You have advanced logging and debugging tools with
cloud-init analyze. - It's easy to reset an instance and run cloud-init again without a full reinstall.
How cloud-init works
On systemd-based Linux systems like Arch, Debian, Fedora, RHEL, and Ubuntu, cloud-init.service runs as a oneshot service as soon as possible after boot, before the networking, SSH, and other services start. To deploy a custom instance, it modifies a generic operating system image with Vultr's vendor-data and your user-data.
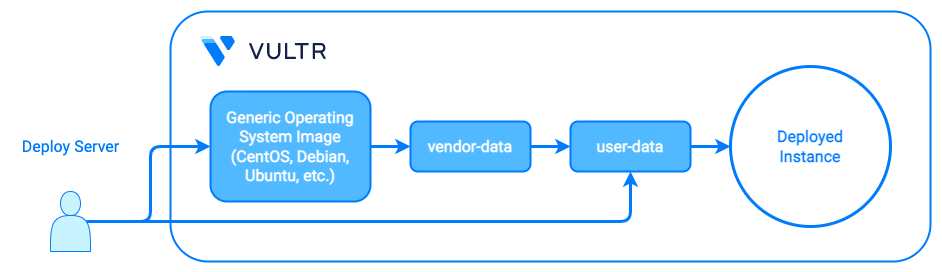
You are not required to supply user-data when you deploy an instance because Vultr's vendor-data has enough information to create a bootable system. However, you'll find that user-data is a powerful tool. In fact, it can even override Vultr's vendor-data because cloud-init merges both sets before applying them, and user-data has priority.
You can create user-data in multiple formats. The most common formats are user-data scripts and cloud-config.
What is a user-data script?
A user-data script always begins with a valid shebang). For example, here is a bash user-data script.
#!/usr/bin/env bash
echo "Hello World at $(date +%Y-%m-%d:%H:%M:%S)" > /user-data-ran-at-boot.txtThe script runs as root and only on the first boot. It will not run on subsequent boots. To test this, deploy a server with this user-data script and reboot it multiple times. You'll see that cloud-init creates the file on the first boot but does not update it on later boots.
Disadvantages of user-data scripts
User-data scripts have several disadvantages. First, writing a bash script to handle all possible error conditions is difficult. So is making the script portable between Linux distributions. Also, not all systems use the same version of bash. You could attempt to solve this by using a different interpreter such as Python:
#!/usr/bin/env python3
import time
fd = open("python-user-data-ran-at-boot.txt", "w")
fd.write("Hello Python at %f" % time.time())
fd.close()But this example has other problems. It works on Ubuntu with Python 3, but it's not portable for Python 2 systems or if Python is installed differently.
Also, portable startup scripts need to detect which distribution they are running on and use the correct package manager, such as apt, yum, dnf, or dpkg.
How is cloud-config different than user-data scripts?
Cloud-config formatted user-data begins with #cloud-config, instead of a shebang, to distinguish it from shell scripts. It's portable, reliable, and has better error handling than shell scripts. Instead of writing a brittle script, you declare modules and instructions in YAML format. Cloud-init processes your cloud-config and runs the appropriate modules to deliver the configuration you declared. Many cloud-config modules are portable across Linux distributions and automatically use the correct command for the situation, such as apt versus yum. With minimal code and no shell-scripting headaches, you can run modules to set up users and SSH keys, install software, write arbitrary files, run external commands, and perform more than 50 other actions.
How to use cloud-config
In this section are several real-world examples you can use in your cloud-config files. These have been tested on at least one distribution, but you may need to modify them for your purposes. If you copy and paste from these, only include the #cloud-config header once in the file.
How to install packages
Here's a cloud-config file that installs a database package. Notice that it doesn't define which package manager to use, so it's portable across distributions.
#cloud-config
packages:
- mysql-serverHow to install Docker
This example is for apt-based distributions like Debian and Ubuntu; it won't work for yum-based ones like CentOS or RHEL.
Assume you want to install Docker on a new Ubuntu cloud server. Typically, to install Docker, you need to:
- Add Docker's repository to apt's sources
- Validate the keys
- Update the packages
- Install Docker
- Reboot
You could write a shell script to do those five steps. But, that also needs error-checking, wait loops, and retry logic. It's not difficult for an expert, but this is a task better performed with cloud-config. Instead of writing procedural code, describe the desired result and let cloud-init handle it for you. Here's a cloud-config that installs Docker, following the same five steps. Note that you'll need to
#cloud-config
package_update: true # Update the apt database
package_upgrade: true # Upgrade the instance's packages
apt:
sources:
docker.list:
source: "deb [arch=amd64] https://download.docker.com/linux/ubuntu $RELEASE stable"
keyid: FFFF0000 # Example GPG key ID
packages:
- docker-ce
power_state:
delay: "now"
mode: reboot
message: Reboot after installing Docker
condition: TrueWhen cloud-init processes this cloud-config, it will perform these steps in order:
- Update the installed packages
- Add the Docker repository to apt's sources
- Install Docker CE
- Reboot the server
How to overwrite the default user
You can use cloud-init to change the default user configuration. The following example creates a default user named steve instead of the distribution's default user, such as root or ubuntu, and removes the password prompt when using sudo.
#cloud-config
system_info:
default_user:
name: steve
gecos: "Steve Smith"
primary-group: steve
shell: /bin/bash
lock_passwd: true
sudo: ['ALL=(ALL) NOPASSWD:ALL']The default_user module supports other options, like installing SSH keys, setting an expiration date, and defining password policies for the user.
How to write arbitrary files
You can write arbitrary files with cloud-config. The content can be encoded in base64 or gzip, and will be decoded before it's written to the file. Content can be plain text or binary. If you use binary data, make sure to use the !!!binary YAML option. Here's an example of several different formats.
#cloud-config
# This is the configuration syntax that the write_files module
# will know how to understand. Encoding can be given b64 or gzip or (gz+b64).
# The content will be decoded accordingly and then written to the path that is
# provided.
# Note: Content strings here are truncated for example purposes.
write_files:
- encoding: b64
content: CiMgVGhpcyBmaWxlIGNvbnRyb2xzIHRoZSBzdGF0ZSBvZiBTRUxpbnV4...
owner: root:root
path: /etc/sysconfig/selinux
permissions: '0644'
- content: |
# My new /etc/sysconfig/samba file
SMBDOPTIONS="-D"
path: /etc/sysconfig/samba
- content: !!binary |
f0VMRgIBAQAAAAAAAAAAAAIAPgABAAAAwARAAAAAAABAAAAAAAAAAJAVAAAAAAAAAAAAAEAAOAAI
AEAAHgAdAAYAAAAFAAAAQAAAAAAAAABAAEAAAAAAAEAAQAAAAAAAwAEAAAAAAADAAQAAAAAAAAgA
AAAAAAAAAwAAAAQAAAAAAgAAAAAAAAACQAAAAAAAAAJAAAAAAAAcAAAAAAAAABwAAAAAAAAAAQAA
....
path: /bin/arch
permissions: '0555'
- encoding: gzip
content: !!binary |
H4sIAIDb/U8C/1NW1E/KzNMvzuBKTc7IV8hIzcnJVyjPL8pJ4QIA6N+MVxsAAAA=
path: /usr/bin/hello
permissions: '0755'See the write-files documentation for more infomation.
How to add a new repository
Adding the Extra Packages for Enterprise Linux to yum-based distributions is a popular task. Use this cloud-config to automatically add the EPEL 8 repository to /etc/yum.repos.d/epel_example.repo.
#cloud-config
yum_repo_dir: /etc/yum.repos.d
yum_repos:
epel-example:
baseurl: http://download.fedoraproject.org/pub/epel/8/$basearch
enabled: true
failovermethod: priority
gpgcheck: true
gpgkey: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL
name: Extra Packages for Enterprise Linux 8See the yum-add-repo documentation for more details.
How to set the hostname
You can use the hostname module to set the system hostname and fully qualified domain name (FQDN).
#cloud-config
preserve_hostname: false
hostname: testhost
fqdn: testhost.example.com
prefer_fqdn_over_hostname: trueSee the set-hostname documentation to learn more about this module.
How to reboot the instance
Sometimes it's handy to reboot the instance after deployment. If you put this at the end of your cloud-config, the instance will reboot ten minutes after cloud-init completes.
#cloud-config
power_state:
timeout: 120
delay: "+10"
message: The server will reboot in ten minutes.
mode: rebootHow to override Vultr's vendor-data
When you deploy a new instance, cloud-init updates all the system packages before it enables SSH. This takes several minutes. The directive is in Vultr's vendor-data, but you might want to skip that and SSH to the instance as quickly as possible. Fortunately, you can override those vendor-data directives in cloud-config. To disable updates, set two values false in your cloud-config.
#cloud-config
package_update: false
package_upgrade: falseWe do not recommend doing this, but it's possible. If you disable the initial updates like this, please run them some other way soon after deployment.
That was one example, but you can override any vendor-data value. If you are curious about what values exist, log in to an instance as root and query cloud-init. This command dumps all instance metadata, including the vendor-data it used.
# cloud-init query -aBe cautious. Overriding many of these values will break your instance, and some might prevent it from booting at all.
More cloud-config examples
Canonical publishes several useful cloud-config examples on GitHub, where you'll find working examples such as:
- Run arbitrary commands
- Add alternate repositories
- How to work with Chef and Ansible
- Perform custom disk partitioning
- Set up mount points
- Configure NTP
- Configure user groups
- Set up Wireguard VPN
You'll find more examples in the cloud-init documentation.
Other useful cloud-init commands
You can use cloud-init after the instance is deployed for many useful tasks. Use one of these subcommands with the --help parameter for more details.
init initializes cloud-init and performs initial modules
modules activates modules using a given configuration key
single run a single module
query Query standardized instance metadata from the command line.
dhclient-hook Run the dhclient hook to record network info.
features list defined features
analyze Devel tool: Analyze cloud-init logs and data
devel Run development tools
collect-logs Collect and tar all cloud-init debug info
clean Remove logs and artifacts so cloud-init can re-run.
status Report cloud-init status or wait on completion.For example, to discover what cloud the instance is deployed on, use:
$ sudo cloud-init query cloud_name
vultrTo clean cloud-init, forcing it to run again at the next boot, use cloud-init clean.
# sudo cloud-init clean --help
usage: /usr/local/bin/cloud-init clean [-h] [-l] [-r] [-s]
options:
-h, --help show this help message and exit
-l, --logs Remove cloud-init logs.
-r, --reboot Reboot system after logs are cleaned so cloud-init re-runs.
-s, --seed Remove cloud-init seed directory /var/lib/cloud/seed.How to supply user-data when deploying an instance
You can supply user-data through the Vultr Console, with Vultr API, or vultr-cli. To demonstrate each method, let's assume you want to deploy a Rocky Linux 8 server in New Jersey.
This user-data installs MySQL using cloud-config format.
#cloud-config
packages:
- mysql-serverYou'll use this user-data in each example that follows.
How to use the Vultr Console
To add user-data to your server instance, navigate to the deployment page in the Vultr Console. When you make your selections, check the Enable Cloud-Init User-Data box in the Additional Features section. This reveals the text entry field where you paste the user-data in plain text.
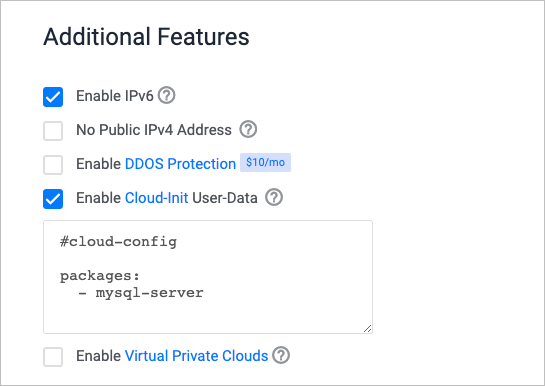
Finish the rest of your selections, then click Deploy Now.
How to use vultr-cli
When you deploy a server with vultr-cli, you must supply a location, plan, and operating system. Here is a minimal example for Rocky Linux 8 with 1GB RAM in New Jersey, without any user-data.
$ vultr-cli instance create --region="ewr" --plan="vc2-1c-1gb" --os=448To add user-data to that instance, follow these steps:
Create a user-data file named
myconfig.txt.#cloud-config packages: - mysql-serverAssign the contents of the file to a temporary variable.
$ MYCONFIG=$(< ./myconfig.txt)Pass that variable to vultr-cli with the
--userdataparameter.$ vultr-cli instance create --userdata $MYCONFIG --region="ewr" --plan="vc2-1c-1gb" --os=448After vultr-cli deploys the instance, it reports the instance's ID, which you can use to inspect the user-data.
$ vultr-cli instance user-data get EXAMPLE-INSTANCE-ID USERDATA #cloud-config packages: - mysql-server
The returned user-data is the same as the original file, demonstrating that your user-data was successfully assigned to the instance.
How to use Vultr API
Unlike the Vultr Console and vultr-cli, Vultr API requires base64-encoded user-data in the JSON payload of the request header. Here's how to do it from the command line with curl.
Encode the user-data
Use the same myconfig.txt from the previous example.
#cloud-config
packages:
- mysql-serverEncode the file with base64, and copy the output to your clipboard.
$ base64 ./myconfig.txt
I2Nsb3VkLWNvbmZpZwoKcGFja2FnZXM6CiAgLSBteXNxbC1zZXJ2ZXIKCreate a payload file for curl
Create a file named payload.txt with the base64-encoded user-data. Use the same region, plan, and os as in the previous example.
You'll pass this file to
curlin the next step. An external payload file is easier to maintain than supplying the JSON object on the command line, particularly for a real-world example with extensive attributes.
{
"region" : "ewr",
"plan" : "vc2-1c-1gb",
"os_id" : 448,
"user_data" : "I2Nsb3VkLWNvbmZpZwoKcGFja2FnZXM6CiAgLSBteXNxbC1zZXJ2ZXIK"
}Create a new instance by calling the create-instance endpoint with curl. The --data parameter reads the user-data payload file you created.
$ curl "https://api.vultr.com/v2/instances" \
-X POST \
-H "Authorization: Bearer ${VULTR_API_KEY}" \
-H "Content-Type: application/json" \
--data @payload.txtThis API call returns a JSON object with the instance ID. Use that ID like this to fetch the user-data:
$ curl "https://api.vultr.com/v2/instances/EXAMPLE-INSTANCE-ID/user-data" \
-X GET \
-H "Authorization: Bearer ${VULTR_API_KEY}"That call returns this JSON object, and the data matches the encoded user-data you supplied.
{"user_data":{"data":"I2Nsb3VkLWNvbmZpZwoKcGFja2FnZXM6CiAgLSBteXNxbC1zZXJ2ZXIK"}}How to troubleshoot cloud-init
If cloud-init isn't doing what you expect, then it's time to dig into cloud-init's logs.
Where to find the logs
The main logs are:
/var/log/cloud-init.log
/var/log/cloud-init-output.logYou'll find more internal cloud-init logs in /run/cloud-init.
In addition to viewing these logs directly, you can use cloud-init analyse to parse the logs.
# cloud-init analyze -h
usage: /usr/local/bin/cloud-init analyze [-h] {blame,show,dump,boot} ...
options:
-h, --help show this help message and exit
Subcommands:
{blame,show,dump,boot}
blame Print list of executed stages ordered by time to init
show Print list of in-order events during execution
dump Dump cloud-init events in JSON format
boot Print list of boot times for kernel and cloud-initAnother good information source is /var/lib/cloud/status.json, which records the stages run and the start and stop times for each.
Config files
The config files are located in:
/etc/cloud/cloud.cfg/etc/cloud/cloud.cfg.d/*.cfg
These define which modules run during instance initialization, the datasources to evaluate at boot, and other settings.
Data files
Inside /var/lib/cloud/, there are two important subdirectories:
/var/lib/cloud/instanceis a symbolic link that points to the most recently used instance-id directory, which contains:- The cloud-init vendor and user data, which can be helpful to review.
- The full information about what datasource was used to setup the system.
- The boot-finished file, which is the last thing that cloud-init does.
/var/lib/cloud/datacontains information related to the previous boot:instance-idis the instance id as discovered by cloud-init. Changing this file has no effect.result.jsonshows both the datasource used to setup the instance, and if any errors occurred.status.jsonshows the datasource used, a breakdown of all modules if any errors occurred, and the start and stop times.
More information
Cloud-init is powerful and frequently updated with new modules and vendor datasources. To stay up to date, you should periodically review these sources:
If you have questions about using cloud-init at Vultr, please open a support ticket and let us know how we can improve our documentation.