
How to Deploy Kubeflow as an AWS SageMaker Alternative
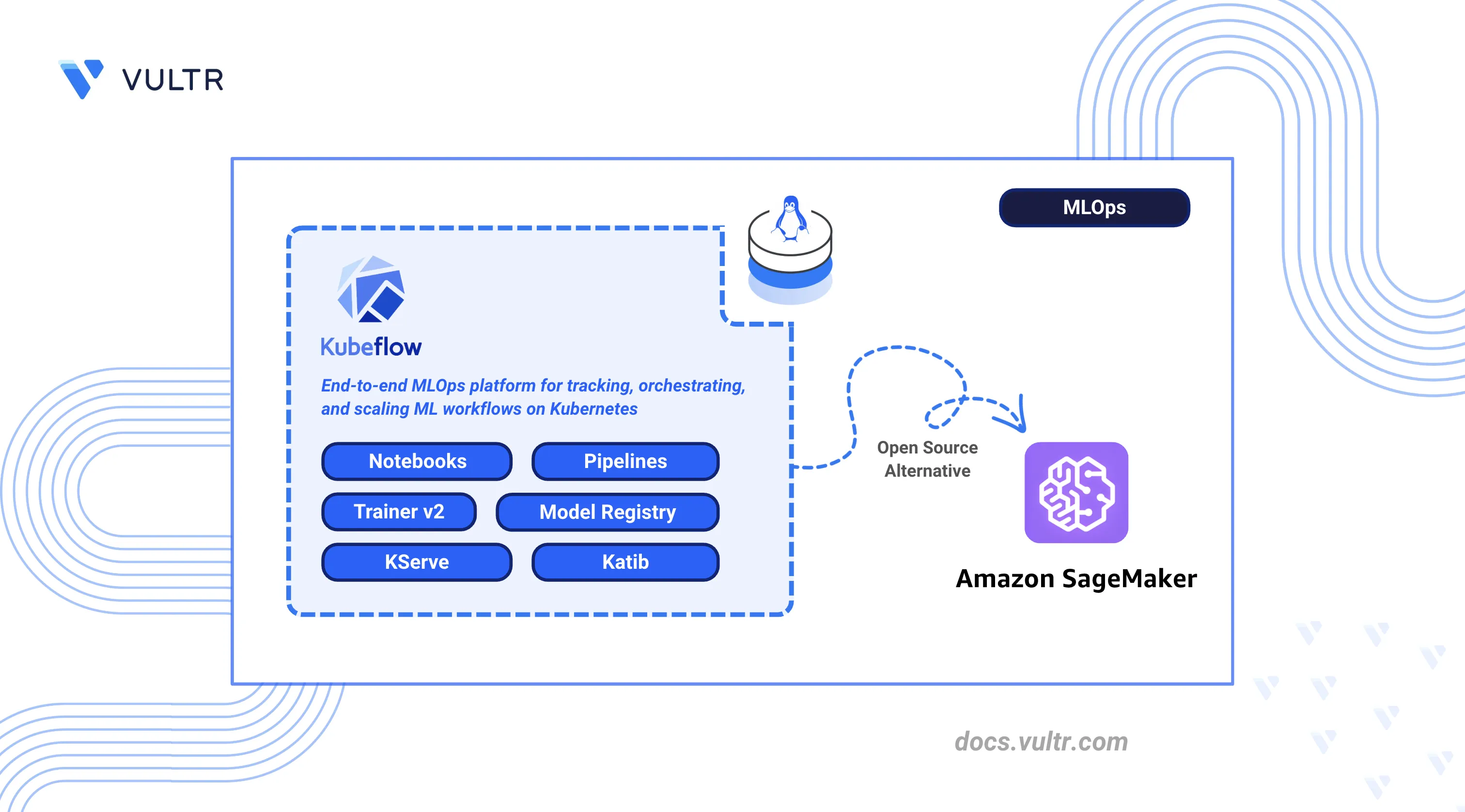
AWS SageMaker is a fully managed Machine Learning (ML) platform that provides notebooks, training jobs, pipelines, model serving, and hyperparameter tuning as hosted services within the AWS ecosystem. It abstracts infrastructure management but ties teams to AWS-specific APIs, regional data boundaries, and usage-based pricing that scales with compute time.
Kubeflow is an open-source alternative built on Kubernetes that replicates each SageMaker capability as a portable, self-hosted component, giving teams control over infrastructure, data residency, and resource allocation.
This article explains how to deploy Kubeflow on a Kubernetes cluster as a self-hosted replacement for AWS SageMaker. It covers installation via Kustomize manifests, notebook configuration, pipeline orchestration, distributed training with the Trainer v2 API, model serving with KServe, hyperparameter tuning with Katib, access control, object storage integration, and migration steps from SageMaker.
Understanding AWS SageMaker vs Kubeflow
AWS SageMaker and Kubeflow provide comparable ML platform capabilities, but they differ in deployment and operational models. SageMaker delivers these as fully managed services within the AWS ecosystem, while Kubeflow provides equivalent open-source components that run on any Kubernetes cluster. The following table maps each SageMaker feature to its Kubeflow counterpart.
| AWS SageMaker Feature | Kubeflow Equivalent | Description |
|---|---|---|
| SageMaker Studio | Kubeflow Notebooks | Interactive development environments with JupyterLab, VS Code, and RStudio |
| SageMaker Training Jobs | Kubeflow Trainer | Distributed training for PyTorch, DeepSpeed, MLX, JAX, and XGBoost workloads |
| SageMaker Pipelines | Kubeflow Pipelines (KFP) | Directed Acyclic Graph (DAG) based ML workflow orchestration |
| SageMaker Model Registry | Kubeflow Model Registry | Versioned model artifact management with metadata tracking |
| SageMaker Endpoints | KServe | Serverless model serving with autoscaling and canary deployments |
| SageMaker Experiments | Katib | Automated hyperparameter tuning with multiple search algorithms |
Self-hosting with Kubeflow eliminates per-minute compute charges, keeps all data within your own cluster, runs on any cloud provider or on-premises hardware, and allows complete customization of every component.
Prerequisites
Before you begin, you need to:
- Have access to a multi-node Kubernetes cluster that runs Kubernetes 1.31 or later with at least 4 CPU cores and 16 GB of RAM per node (minimum 3 nodes recommended).
- Install kubectl and configure it to connect to your cluster.
- Install Kustomize version 5.4.3 or later.
- Have a default
StorageClassthat is configured in your cluster for provisioning persistent volumes.
Install Kubeflow
Kubeflow uses Kustomize to deploy its components as Kubernetes resources. The official kubeflow/manifests repository contains all component manifests that are organized under common/ for shared infrastructure services such as Istio, cert-manager, and Dex, and under applications/ for Kubeflow-specific applications such as Pipelines, Notebooks, and KServe.
Deploy Kubeflow via Manifests
The following steps clone the Kubeflow manifests repository and deploy all components to the cluster.
Verify the Kubernetes cluster connection.
console$ kubectl cluster-info
Check the Kubernetes server version.
console$ kubectl version
Verify that the
Server Versionfield shows version 1.31 or later.Clone the official Kubeflow manifests repository.
console$ git clone https://github.com/kubeflow/manifests.git
Switch to the manifests directory.
console$ cd manifests
Check out the latest stable release tag.
console$ git checkout 26.03
Deploy all Kubeflow components. The command uses a bounded retry loop that attempts the installation up to 5 times, which accommodates the time that Kubernetes CRDs and webhooks need to register before dependent resources apply. The loop exits automatically after a successful apply or after reaching the retry limit.
console$ for i in 1 2 3 4 5; do kustomize build example | kubectl apply --server-side --force-conflicts -f - && break || { echo "Attempt $i failed, retrying in 30s..."; sleep 30; }; done
The first one or two attempts may output errors about CRDs or webhooks not being established. These errors are expected and resolve on subsequent attempts after the CRDs register. The loop exits automatically when the apply succeeds, usually on the second or third attempt after CRDs register. The full installation takes approximately 10 to 15 minutes after the final successful apply for all pods to reach a
Runningstate. The--server-side --force-conflictsflags are required because some Kubeflow CRDs exceed the annotation size limit that standardkubectl applysupports.The default installation uses the emailNoteuser@example.comand password12341234. Change these credentials before exposing Kubeflow to any network. See the Set Up Access Control section later in this article for instructions.
Verify Installation
After the deployment completes, verify that all Kubeflow components are running and the CRDs are registered.
Check that all pods in the
kubeflownamespace reach aRunningstate.console$ kubectl get pods -n kubeflow --field-selector=status.phase!=Succeeded
Verify that all listed pods display a
Runningstatus with all containers ready. If any pods showCrashLoopBackOfforPending, check their logs withkubectl logs -n kubeflow POD-NAMEand verify that the cluster meets the minimum resource requirements.Check that the Istio ingress gateway service is running.
console$ kubectl get svc istio-ingressgateway -n istio-system
Verify that the service appears in the output.
Check that Kubeflow and its component CRDs are registered.
console$ kubectl get crd | grep -E "kubeflow|kserve|katib|istio|knative|trainer" | wc -l
The output displays the count of registered CRDs across Kubeflow and its components. Verify that the count matches the expected number for your Kubeflow version.
Create Default User Profile
Kubeflow uses profiles to provide namespace-level isolation for each user. The default installation does not provision a user namespace automatically. Create one before proceeding.
Create a new file called
user-profile.yaml.console$ nano user-profile.yaml
Add the following configuration:
yamlapiVersion: kubeflow.org/v1 kind: Profile metadata: name: kubeflow-user-example-com spec: owner: kind: User name: user@example.com
Save and close the file.
Apply the profile manifest.
console$ kubectl apply -f user-profile.yaml
This command creates an isolated namespace called
kubeflow-user-example-comwith default Role-Based Access Control (RBAC) policies and a service account for the default user.Verify that the namespace exists.
console$ kubectl get namespace kubeflow-user-example-com
Verify that the default service account exists. The service account takes a few seconds to provision after the profile is created. Wait 10 seconds before running this command.
console$ kubectl get serviceaccount default-editor -n kubeflow-user-example-com
Configure Storage
Kubeflow components such as Notebooks, Pipelines, and the Model Registry require persistent storage. The cluster needs a default StorageClass to dynamically provision Persistent Volume Claims (PVCs).
Verify that a default
StorageClassexists.console$ kubectl get storageclass
The default
StorageClassshows(default)next to its name. If no default exists, set one by annotating an existingStorageClass. ReplaceSTORAGE-CLASS-NAMEwith the name of an existingStorageClassfrom the output above.console$ kubectl patch storageclass STORAGE-CLASS-NAME -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'
Configure Kubeflow Notebooks
Kubeflow Notebooks provides managed JupyterLab, VS Code, and RStudio environments that run as Kubernetes pods with direct access to cluster resources, GPUs, and persistent storage. This component replaces SageMaker Studio notebooks with a self-hosted alternative.
Access Dashboard
Set up port forwarding and log in to the Kubeflow Central Dashboard.
Set up port forwarding to access the Kubeflow Central Dashboard.
console$ kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80
Open
http://localhost:8080in a web browser. The Kubeflow login screen appears. Click Sign in with Dex.
Enter the default credentials on the Dex login form and click Login.
- Email:
user@example.com - Password:
12341234
- Email:
The Kubeflow Central Dashboard loads with links to Notebooks, Pipelines, Katib Experiments, KServe Endpoints, and other components. Select
kubeflow-user-example-comfrom the namespace dropdown at the top.
Create Notebook Server
Launch a new notebook server from the Kubeflow dashboard.
Navigate to Notebooks in the left sidebar and click New Notebook.
Enter
ml-workspacein the Name field.Select the notebook environment from the image cards. Choose JupyterLab for a general-purpose data science environment. Select VisualStudio Code for a code editor interface, or RStudio for R-based statistical computing. To use a specific image version, select Custom Notebook from the dropdown below the cards.
Set Minimum CPU to
0.5and Minimum Memory Gi to1.Leave the Workspace Volume at the default
5Gi. This volume persists data across notebook restarts.Click Launch and wait for the notebook pod to reach a
Runningstate. The status indicator turns green when the notebook is ready.
Connect to Notebook
Open the JupyterLab interface and verify that ML libraries are accessible.
Click Connect next to the notebook server name. A new tab opens with the JupyterLab interface.
Click Python 3 (ipykernel) under the Notebook section in the launcher to create a new notebook. Paste the following code into a cell and press Shift + Enter to run it.
pythonimport numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split X = np.random.randn(1000, 10) y = (X[:, 0] + X[:, 1] > 0).astype(int) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model = RandomForestClassifier(n_estimators=100) model.fit(X_train, y_train) print(f"Accuracy: {model.score(X_test, y_test):.4f}")
The cell outputs an accuracy score such as
Accuracy: 0.9750.
Set Up Kubeflow Pipelines
Kubeflow Pipelines (KFP) is an orchestration platform that enables building and deploying ML workflows as Directed Acyclic Graphs (DAGs). Each pipeline step runs in its own container, which enables reproducibility and version tracking. KFP replaces SageMaker Pipelines with an open-source alternative.
Deploy Sample Pipeline
Install the KFP SDK, define a three-step pipeline, compile it, and submit a run through the internal API. The following steps use both the notebook terminal and the cluster management terminal where specified.
Inside JupyterLab, click File > New > Terminal to open a terminal tab.
Create the pipeline definition file.
console$ nano sample_pipeline.py
Add the following configuration:
pythonfrom kfp import dsl, compiler @dsl.component(base_image="python:3.11-slim") def preprocess() -> str: import json data = {"samples": 1000, "features": 10, "status": "preprocessed"} return json.dumps(data) @dsl.component(base_image="python:3.11-slim") def train(input_data: str) -> str: import json data = json.loads(input_data) result = {"model": "random_forest", "accuracy": 0.95, "input": data} return json.dumps(result) @dsl.component(base_image="python:3.11-slim") def evaluate(input_data: str): import json result = json.loads(input_data) print(f"Model: {result['model']}, Accuracy: {result['accuracy']}") @dsl.pipeline(name="sample-ml-pipeline") def ml_pipeline(): preprocess_task = preprocess() train_task = train(input_data=preprocess_task.output) evaluate(input_data=train_task.output) compiler.Compiler().compile(ml_pipeline, "pipeline.yaml") print("Pipeline compiled successfully")
Save and close the file.
Compile the pipeline to generate the YAML definition.
console$ python3 sample_pipeline.py
Switch to the cluster management terminal and create the authorization policy manifest. This policy allows the notebook namespace to call the Kubeflow Pipelines API through the Istio service mesh.
console$ nano allow-pipeline-access.yaml
Add the following configuration:
yamlapiVersion: security.istio.io/v1beta1 kind: AuthorizationPolicy metadata: name: allow-notebook-to-pipeline namespace: kubeflow spec: selector: matchLabels: app: ml-pipeline rules: - from: - source: namespaces: ["kubeflow-user-example-com"]
Save and close the file.
Apply the authorization policy.
console$ kubectl apply -f allow-pipeline-access.yaml
Switch to the notebook terminal and upload the compiled pipeline to Kubeflow Pipelines through the internal API.
console$ curl -s -F "uploadfile=@pipeline.yaml" -H "kubeflow-userid: user@example.com" http://ml-pipeline.kubeflow.svc.cluster.local:8888/apis/v2beta1/pipelines/upload
The command returns a JSON response that contains the
pipeline_id. Note this value for the next step.Create an experiment to organize pipeline runs. Kubeflow Pipelines automatically creates a system experiment named
Default, so use a different name to avoid a conflict.console$ curl -s -X POST -H "Content-Type: application/json" -H "kubeflow-userid: user@example.com" http://ml-pipeline.kubeflow.svc.cluster.local:8888/apis/v2beta1/experiments -d '{"display_name":"sample-experiment","namespace":"kubeflow-user-example-com"}'
The command returns a JSON response that contains the
experiment_id. Note this value for the next step.Start a pipeline run. Replace
PIPELINE-IDandEXPERIMENT-IDwith the values from the previous steps.console$ curl -s -X POST -H "Content-Type: application/json" -H "kubeflow-userid: user@example.com" http://ml-pipeline.kubeflow.svc.cluster.local:8888/apis/v2beta1/runs -d '{"display_name":"test-run","experiment_id":"EXPERIMENT-ID","pipeline_version_reference":{"pipeline_id":"PIPELINE-ID"},"runtime_config":{}}'
Monitor Execution
The pipeline run status is visible from the command line and from the Kubeflow dashboard. The dashboard provides a graph view that shows each step's completion state.
Verify that the workflow completed.
console$ kubectl get workflows -n kubeflow-user-example-com
Verify that the
STATUScolumn showsSucceeded.Navigate to Pipelines in the left sidebar of the Kubeflow dashboard, then click Experiments. Click sample-experiment, then click the test-run entry. The graph view shows the
preprocess,train, andevaluatesteps each marked with a green checkmark when the run completes successfully.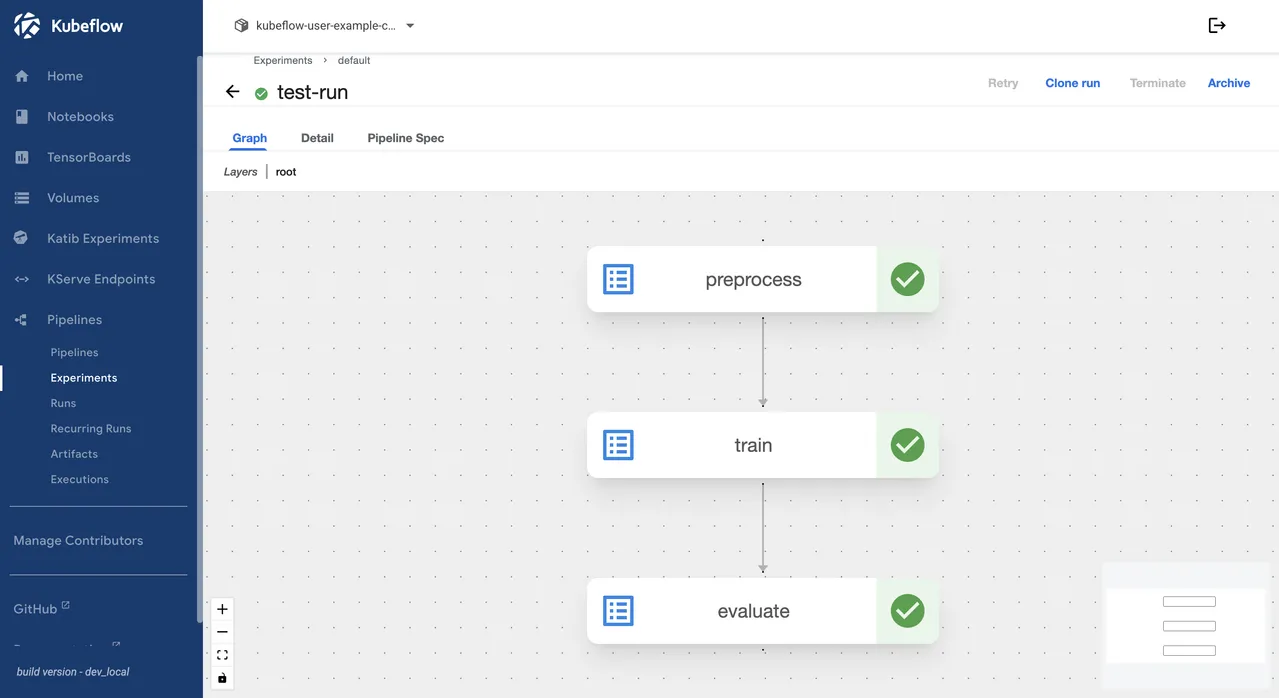
Configure Distributed Training
Kubeflow Trainer v2 provides a unified TrainJob API for running distributed training jobs across frameworks including PyTorch, DeepSpeed, MLX, JAX, and XGBoost. The Trainer uses ClusterTrainingRuntime resources that define pre-configured runtime environments, which separates infrastructure configuration from training logic. Kubeflow Trainer replaces SageMaker Training Jobs with native Kubernetes-based distributed training.
Create Training Job
Create and deploy a distributed PyTorch training job that uses the torch-distributed runtime. Run the following commands from the cluster management terminal.
Create the TrainJob manifest.
console$ nano trainjob.yaml
Add the following configuration:
yamlapiVersion: trainer.kubeflow.org/v1alpha1 kind: TrainJob metadata: name: pytorch-training namespace: kubeflow-user-example-com spec: runtimeRef: name: torch-distributed trainer: image: ghcr.io/kubeflow/katib/pytorch-mnist-cpu:v0.19.0 numNodes: 2 resourcesPerNode: requests: cpu: "500m" memory: "1Gi" limits: cpu: "1" memory: "2Gi"
Save and close the file. The
runtimeReffield references thetorch-distributedClusterTrainingRuntime, which configures the PyTorch distributed training environment. ThenumNodesfield specifies the number of training nodes that Kubeflow provisions for the job.Apply the training manifest.
console$ kubectl apply -f trainjob.yaml
Monitor Training
Check the training job status from the cluster management terminal.
Verify the TrainJob status.
console$ kubectl get trainjob -n kubeflow-user-example-com
The
STATEcolumn showsCompletewhen training finishes successfully.
Deploy Model Serving with KServe
KServe provides a Kubernetes CRD called InferenceService for deploying, scaling, and managing ML model endpoints. It supports serverless inference with autoscaling from zero, canary rollouts, and multi-model serving across frameworks including TensorFlow, PyTorch, scikit-learn, XGBoost, and ONNX. KServe also supports deploying models directly from Hugging Face Hub using the hf:// URI schema and from the Kubeflow Model Registry using the model-registry:// protocol. KServe is included in the Kubeflow installation and replaces SageMaker Endpoints.
Create InferenceService
Deploy a pre-trained scikit-learn model and expose it as a serving endpoint. Run the following commands from the cluster management terminal.
Create the model serving manifest.
console$ nano sklearn-iris.yaml
Add the following configuration:
yamlapiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: name: sklearn-iris namespace: kubeflow-user-example-com annotations: sidecar.istio.io/inject: "false" spec: predictor: model: modelFormat: name: sklearn storageUri: "gs://kfserving-examples/models/sklearn/1.0/model" resources: requests: cpu: 100m memory: 256Mi limits: cpu: "1" memory: 1Gi
Save and close the file.
Apply the InferenceService manifest.
console$ kubectl apply -f sklearn-iris.yaml
Monitor the InferenceService status. The
-wflag watches for status changes and updates the output in place.console$ kubectl get inferenceservice sklearn-iris -n kubeflow-user-example-com -w
The
READYcolumn changes toTruewhen the model is loaded and serving. Press Ctrl + C to stop watching. Navigate to KServe Endpoints in the Kubeflow dashboard sidebar to view the deployed model.
Test Model Endpoint
Send a test inference request to verify that the model is serving predictions.
Run the following command from the Kubeflow notebook terminal, which has direct access to the cluster-internal service endpoint.
console$ curl -s --max-time 30 -H "Content-Type: application/json" http://sklearn-iris-predictor-00001-private.kubeflow-user-example-com.svc.cluster.local/v1/models/sklearn-iris:predict -d '{"instances": [[6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6]]}'
The response returns predicted class labels.
{"predictions": [1, 1]}
Configure Hyperparameter Tuning
Katib is the Kubeflow component that provides automated hyperparameter tuning and neural architecture search. It supports multiple search algorithms including random search, grid search, Bayesian optimization, Tree-structured Parzen Estimator (TPE), and CMA Evolution Strategy. Katib replaces SageMaker Experiments and Automatic Model Tuning with a Kubernetes-native solution.
Create Tuning Experiment
Katib experiments are defined and submitted through the Katib Python SDK from a JupyterLab notebook cell. The SDK creates the experiment resource on the cluster and manages trial pod configuration and metrics collection automatically.
Open a terminal in JupyterLab by clicking File > New > Terminal and install the Katib Python SDK.
console$ pip install kubeflow-katib
Close the terminal tab and create a new Python notebook by clicking File > New > Notebook, then selecting Python 3 (ipykernel) as the kernel. Run the following code in a cell to define an objective function and launch a tuning experiment.
pythonimport kubeflow.katib as katib def objective(parameters): import time time.sleep(5) result = 4 * int(parameters["a"]) - float(parameters["b"]) ** 2 print(f"result={result}") parameters = { "a": katib.search.int(min=10, max=20), "b": katib.search.double(min=0.1, max=0.2) } katib_client = katib.KatibClient(namespace="kubeflow-user-example-com") name = "tune-experiment" katib_client.tune( name=name, objective=objective, parameters=parameters, objective_metric_name="result", objective_type="maximize", algorithm_name="random", max_trial_count=4, parallel_trial_count=2, resources_per_trial={"cpu": "1", "memory": "1Gi"}, )
The
tune()method creates a Katib experiment that runs 4 trials (2 in parallel) using random search. The cell output includes aKatib Experiment tune-experiment link hereline. Click here to monitor trial progress in the Katib Experiments tab. The experiment status turns green when all trials complete.Retrieve the optimal hyperparameters by running the following code in the next cell.
pythonkatib_client.wait_for_experiment_condition(name=name) print(katib_client.get_optimal_hyperparameters(name))
Set Up Access Control
Kubeflow uses Dex as its OpenID Connect (OIDC) identity provider and Istio for network-level authorization. Each user gets an isolated namespace, which is called a profile, with its own resources, secrets, and RBAC policies.
Configure Authentication
The Dex ConfigMap uses hashFromEnv: DEX_USER_PASSWORD to read the password hash from an environment variable rather than storing it directly in the ConfigMap. To change the default password, update the Secret that provides this environment variable to the Dex pod.
Install the
bcryptPython package to generate a password hash.console$ pip install bcrypt
Generate a bcrypt hash for the new password. Replace
YOUR-SECURE-PASSWORDwith the password you want to set.console$ python3 -c "import bcrypt; print(bcrypt.hashpw(b'YOUR-SECURE-PASSWORD', bcrypt.gensalt()).decode())"
Copy the output hash for use in the next step.
Update the
dex-passwordsSecret with the new hash. ReplaceGENERATED-BCRYPT-HASHwith the hash output from the previous step.console$ kubectl create secret generic dex-passwords -n auth \ --from-literal=DEX_USER_PASSWORD='GENERATED-BCRYPT-HASH' \ --dry-run=client -o yaml | kubectl apply -f -
The command outputs a warning about a missing annotation. This is expected becauseNotedex-passwordswas created by Kubeflow without--save-config. Verify that the output ends withsecret/dex-passwords configured.Restart the Dex deployment to apply the changes.
console$ kubectl rollout restart deployment dex -n auth
To add additional static users or configure external identity providers such as Lightweight Directory Access Protocol (LDAP), GitHub, or Google, add entries to the
staticPasswordslist or connector entries in the Dex ConfigMap. See the Dex documentation for details.
Implement RBAC
Each additional user needs a profile that follows the same manifest structure as the default user profile. Replace the metadata.name and owner.name fields with the new user's details, then apply the manifest with kubectl apply -f.
To give an existing user access to another user's namespace without creating a separate profile, navigate to the target namespace in the Kubeflow dashboard namespace dropdown. Click Manage Contributors in the left sidebar and enter the user's email address.
Integrate Object Storage
ML workflows generate large artifacts including trained models, pipeline outputs, datasets, and logs. Kubeflow uses SeaweedFS as its default S3-compatible object storage backend for artifact persistence. KServe also supports S3-compatible storage for loading model artifacts.
Configure Storage Backend
The default Kubeflow installation deploys SeaweedFS in the kubeflow namespace with pre-configured credentials. Verify that the storage deployment is running.
Check the SeaweedFS pod status.
console$ kubectl get pods -n kubeflow -l app=seaweedfs
For production deployments, replace SeaweedFS with an external S3-compatible object storage service. Create a Kubernetes secret with your external S3 credentials in the user namespace. Replace
YOUR-ACCESS-KEYandYOUR-SECRET-KEYwith the credentials from your storage service.console$ kubectl create secret generic s3-credentials -n kubeflow-user-example-com \ --from-literal=accesskey=YOUR-ACCESS-KEY \ --from-literal=secretkey=YOUR-SECRET-KEY
Update the
kfp-launcherConfigMap in the user namespace to route pipeline artifacts to the external S3 endpoint. ReplaceYOUR-BUCKET,YOUR-S3-ENDPOINT, andYOUR-REGIONwith values from your storage service.console$ kubectl patch configmap kfp-launcher -n kubeflow-user-example-com --patch ' data: defaultPipelineRoot: "s3://YOUR-BUCKET" providers: | s3: default: endpoint: YOUR-S3-ENDPOINT disableSSL: false region: YOUR-REGION forcePathStyle: true credentials: fromEnv: false secretRef: secretName: s3-credentials accessKeyKey: accesskey secretKeyKey: secretkey '
Restart the Kubeflow Pipelines API server to apply the changes.
console$ kubectl rollout restart deployment ml-pipeline -n kubeflow
Verify that the pod restarts successfully.
console$ kubectl get pods -n kubeflow -l app=ml-pipeline
Verify that all listed pods show a
Runningstatus.
Migration from AWS SageMaker
Migrating from SageMaker to Kubeflow involves exporting existing assets and mapping each SageMaker component to its Kubeflow equivalent. Notebooks transfer without format changes since both platforms use the standard Jupyter notebook format. Training scripts, pipelines, and experiments require rewriting to replace SageMaker SDK calls with Kubeflow and KFP SDK equivalents.
Export Notebooks: Download SageMaker Studio notebooks as
.ipynbfiles from the SageMaker console or the AWS CLI. Upload them directly to Kubeflow Notebook servers, since both platforms use standard Jupyter notebook format. Update any AWS SDK calls such assagemaker.Session()orboto3references that rely on SageMaker-specific APIs.Convert Training Scripts: SageMaker training scripts that use the SageMaker Python SDK estimator pattern (such as
sagemaker.pytorch.PyTorch()) need conversion to standard framework training scripts. Replace SageMaker-specific environment variables likeSM_MODEL_DIRandSM_CHANNEL_TRAININGwith Kubernetes volume mount paths. Package the training code into container images and reference them inTrainJobmanifests.Migrate Pipelines: SageMaker Pipelines that are defined using the SageMaker SDK need rewriting with the KFP SDK. Map each
sagemaker.workflow.stepsstep to a KFP@dsl.componentfunction. Replacesagemaker.processing.ProcessingStepwith KFP container components, and replacesagemaker.workflow.pipeline.Pipelinewith@dsl.pipelinedecorated functions.Export Models: Download trained model artifacts from SageMaker S3 buckets using the AWS CLI. Upload them to your Kubeflow-connected object storage. Update the
storageUriin KServeInferenceServicemanifests to point to the new storage location. KServe supports the same model formats that SageMaker uses (SavedModel, TorchScript, ONNX, scikit-learn pickle files) without conversion.Migrate Experiments: Export SageMaker experiment tracking data using the SageMaker SDK
list_trials()anddescribe_trial_component()API calls. For hyperparameter tuning, recreate tuning jobs as Katib experiments with equivalent search spaces and objective metrics using the Katib Python SDK.
Conclusion
You have successfully deployed Kubeflow on a Kubernetes cluster as a self-hosted alternative to AWS SageMaker. The deployment includes interactive notebooks for model development, Kubeflow Pipelines for workflow orchestration, the Trainer v2 API for distributed PyTorch training, KServe for model serving with serverless inference, and Katib for automated hyperparameter tuning. For more information on GPU scheduling, multi-tenancy, and production hardening, visit the official Kubeflow documentation.