
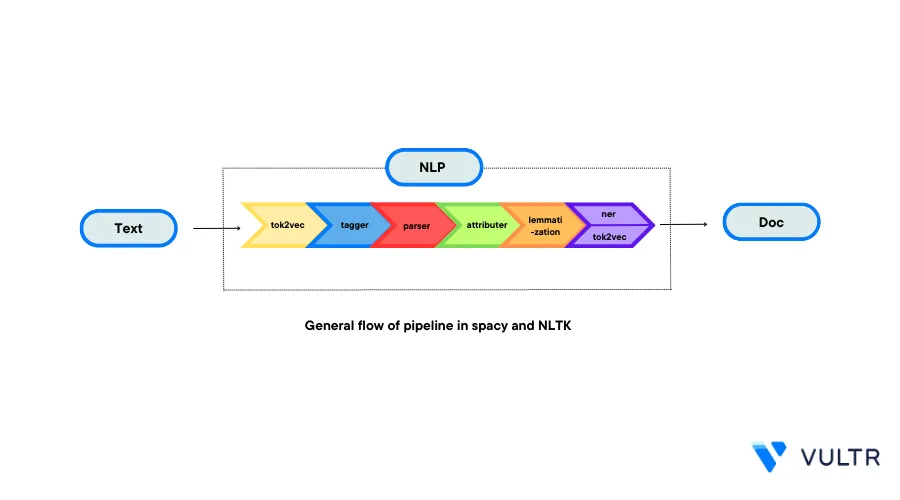
Introduction
Natural Language Processing (NLP) is a field of Artificial Intelligence that aims at enabling computers understand and process human languages. NLP gets computers closer to a human-level understanding of languages, mostly computers don't have the same intuitive understanding of natural language like humans. A computer can’t read between the lines, and can’t understand what the language is trying to say.
Applications of NLP techniques include Voice Assistants such as Alexa and Siri that perform functions like Machine Translation and text-filtering. This article explains how to perform NLP tasks with Python's NLTK (Natural Language Toolkit), spaCy and Gensim on a computer running the Python interpreter.
Prerequisites
Before you begin, make sure:
The Python interpreter is available on your computer. Run the following command to verify the installed version
$ python3 --versionOutput:
Python 3.10.6Have basic Python programming and Machine Learning skills
Install Python Libraries
To use NLTK, prepare a project directory to store Python scripts. Then, use the pip package manager to install the necessary Python libraries required to work with spaCy and Gensim as described in the following steps.
Create a new project directory to store Python scripts
$ mkdir py_projectsUpgrade the Python
pippackage manager$ pip install --upgrade pipUsing
pip, install the NLTK Library$ pip install nltkThe above command installs the NLTK library and related dependencies. The library provides various datasets and resources for natural language processing.
Install spaCy
$ pip install spacyInstall Gensim
$ pip install -U gensimLaunch the Python shell
>>> pythonImport the NLTK library
>>> import nltkInstall the NLTK
punktdataset>>> nltk.download('punkt')The above code downloads the
punktdataset used for NLTK tokenization functions.Exit the Python shell
>>> exit()Download the spaCy English language model that lets you perform a variety of NLP tasks
$ python -m spacy download en_core_web_smThe above command searches the most compatible model for your spaCy version, downloads and installs it for usage with the model.
When all libraries install correctly, import and use them as described in the following sections.
Introduction to NLTK (Natural Language Toolkit)
The Python NLTK package applies many standard NLP data structures, algorithms for text processing. In this section, pre-process text data using nltk and other built-in Python functions.
Perform Tokenization in NLTK
Launch the Python Shell
$ pythonAdd the following code to perform Tokenization
sentence = "You not only need technical skills to become a good writer but also need good writing skills." tokens = nltk.word_tokenize(sentence) print(tokens)Output:
['You', 'not', 'only', 'need', 'technical', 'skills', 'to', 'become', 'a', 'good', 'writer', 'but', 'also', 'need', 'good', 'writing', 'skills', '.']
Part-of-Speech Tagging in NLTK
Part-of-speech (POS) tagging is the process of assigning grammatical labels to each word in a sentence. The NLTK (Natural Language Toolkit) library provides various methods and resources for performing POS tagging. It offers pre-trained taggers for different languages and allows for training custom taggers on annotated corpora. In this section, perform POS tagging in NLTK as described below.
In your Python projects directory, use a text editor such as
nanoto create a new application filepos_tag.py$ nano pos_tag.pyAdd the following code to the file
import nltk from nltk.tokenize import word_tokenize from nltk.tag import pos_tag nltk.download('averaged_perceptron_tagger') sentence = "The dog is barking at the visitor." tokens = word_tokenize(sentence) pos_tags = pos_tag(tokens) for token, pos_tag in pos_tags: print(f"{token}: {pos_tag}")Save and close the file
In the above example code, you apply the
word_tokenizefunction from NLTK to tokenize the input text into individual words. Then, the pos_tag function to assign POS tags to each token. The outcome is a list of tuples, where each tuple comprises a word and its corresponding POS tag.Run the Python application file
$ python pos_tag.pyYour output should look like the one below:
The: DT dog: NN is: VBZ barking: VBG at: IN the: DT visitor: NNThe above output represents the outcome of applying part-of-speech (POS) tagging to the sentence. The
The dog is barking at the visitorPOS tagging serves the purpose of assigning grammatical labels to individual words within a sentence.Theandtheare determiners (DT) signifying specificity.dogandvisitorare common nouns (NN),isacts as a third person singular present tense verb (VBZ),barkingis a verb in gerund or present participle form (VBG), andatis a preposition (IN) denoting a relationship.POS tagging plays a vital role in comprehending the syntactic structure and word roles in a sentence. It facilitates later analysis and processing of the text for diverse natural language processing tasks.
Stemming in NLTK
Stemming is an NLP process that reduces words to their base form, known as a stem. The purpose of stemming is to normalize words by removing suffixes and prefixes. This allows treating variations of a word as the same word. NLTK provides various stemmers for different languages and Porter stemmer is one of the most used variants. In this section, perform stemming using the Porter stemmer in NLTK as described below.
Create a new application file
stemm_app.py$ nano stemm_app.pyAdd the following code to the file
import nltk from nltk.stem import PorterStemmer stemmer = PorterStemmer() words = ["talking", "ate", "play", "played", "playing", "home"] word_stem = [stemmer.stem(word) for word in words] for word, stemmed_word in zip(words, word_stem): print(f"{word} -:: {stemmed_word}")Save and close the file
In the above code, the Porter stemmer stems a list of words: "talking", "ate", "play", "played", "playing", and "home". You can call the stem method of the stemmer on each word to get its stemmed form.
Run the application
$ python stemm_app.pyOutput:
talking -:: talk ate -:: ate play -:: play played -:: play playing -:: play home -:: homeAs displayed in the output, the program prints stemmed versions of the words, demonstrating their base forms. It stems
talkingtotalk, keepsateunchanged because it's already in its base form. Stemsplay,playedandplayingtoplay, then retainshomeashome.Stemming proves useful in various text analysis tasks as it simplifies analysis and allows capturing of common patterns across word variations. It's important to note that stemming algorithms, such as the Porter stemmer, rely on heuristic rules and may not yield accurate or correct stems.
Introduction to spaCy
spaCy is an open source Python library for modern work such as industrial-strength NLP. Unlike its more academic predecessors, spaCy focuses on production and shipping of code. It has the capability of providing backward compatibility. In this section implement spaCy with NLTK as described below.
Tokenization
The initial action carried by any NLP application on a text is parsing that text into tokens. The text can exist in the form of words, numbers, or punctuation marks. Tokenization is the first operation because all the other operations require existing tokens in place. Implement spaCy tokenization as described in the steps below.
Create a new
tokenize_spacy.pyfile$ nano tokenize_spacy.pyAdd the following code to the file
import spacy nlp = spacy.load('en_core_web_sm') file = nlp(u'Python is one of the easy programming languages to learn.') print([w.text for w in file])Save and close the file.
In the above code, you import the spaCy library to gain access to its functionality. Then, you load a model package using the
en_core_web_smlink to create an instance of the spaCy language class. You call the language objectnlpand apply the object createdwto a sample sentence, creating a file object instance. A file object is a container with a sequence of Token objects generated by spaCy based on the provided text.Run the application
$ python tokenize_spacy.pyOutput:
[' Python', 'is', 'one', 'of', 'the', 'easy', 'programming', 'languages', 'to', 'learn', '.']
Lemmatization
A lemma serves as the fundamental form of a token. It represents how the token would appear if included in a dictionary. Lemmatization is the procedure of converting word forms to their respective lemmas. Perform lemmatization using spaCy as described in the following steps.
Create a new application file
spacy-lemmatization.py$ nano spacy-lemmatization.pyAdd the following code to the file
import spacy nlp = spacy.load("en_core_web_sm") phrase1 = "John Doe coded for 5 hours without taking a break" phrase2 = "Taking takes take took adjustable ability meeting better" doc1 = nlp(phrase1) doc2 = nlp(phrase2) for token in doc1: print(token.text, " | ", token.lemma_) for token in doc2: print(token.text, " | ", token.lemma_)Save and close the file.
The above code snippet utilizes the spaCy library to process two phrases. It loads the English language model and tokenizes the phrases using the
nlpfunction. Then, the code iterates through each token in the processed phrases and prints the token's text and corresponding lemma. In short, the code performs text processing and displays the text and lemmas of the tokens in the provided phrases.Run the application
$ python spacy-lemmatization.pyOutput:
John Doe | John Doe coded | code for | for 5 | 5 hours | hour without | without taking | take a | a break | break Taking | take takes | take take | take took | take adjustable | adjustable ability | ability meeting | meeting better | good In the left column are the listed tokens, while in the right column are their corresponding lemmas.
Part-of-Speech Tagging
A tag offers information about the part-of-speech (such as noun or verb) of a specific word within a given sentence. It's important to note that a word can have multiple parts of speech depending on its context. In spaCy, part-of-speech tags offer detailed information about a token.
For instance, in verbs, they state various features like tense (past, present, or future), aspect (progressive or perfect), person (1st, 2nd, or 3rd), and number (singular or plural). Extracting these verb part-of-speech tags is useful in determining a user's intent when tokenization and lemmatization alone are insufficient. Apply tagging as described in the steps below.
Create a new application file
pos_spacy.py$ nano pos_spacy.pyAdd the following code to the file
import spacy nlp = spacy.load("en_core_web_sm") doc = nlp(u'I have finished coding. Now I am taking a nature walk.') for token in doc: print(token.text, token.pos_, token.dep_)Save and close the file.
The above code utilizes the spaCy library for natural language processing. It initializes a document with specific text and iterates over each token in the document. For each token, it prints the token's text, part of speech, and syntactic dependency relation. The code performs a linguistic analysis of the provided sentence.
Run the application
$ python pos_spacy.pyOutput:
I PRON nsubj have AUX aux finished VERB ROOT coding NOUN dobj . PUNCT punct Now ADV advmod I PRON nsubj am AUX aux taking VERB ROOT a DET det nature NOUN compound walk NOUN dobj . PUNCT punctIn the above output, each line represents a token in the input sentence along with its corresponding part-of-speech tag and syntactic dependency.
Named Entity Recognition
A named entity refers to a specific object you identify by its proper name. They encompass individuals, organizations, locations, and other relevant entities. Recognizing named entities holds significance in the field of Natural Language Processing (NLP) as they unveil the specific place or organization of the user. In this section, build an application to detect named entities within the provided sample discourse as described below.
Create a new file
entity_spacy.py$ nano entity_spacy.pyAdd the following code to the file
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp(u'I have flown to India. Now I am flying to Canada.') for token in doc: if token.ent_type != 0: print(token.text, token.ent_type_)Save and close the file
If the
ent_typeattribute of a token has a value other than0, it shows that the token is a named entity. In such cases, you can retrieve theent_type_attribute of the token, which holds the type of the named entity in Unicode format.Run the application
$ python entity_spacy.pyOutput:
India GPE Canada GPEThe country India and Canada are both classified as GPE, which stands for
geopolitical entity, encompassing countries, cities, states, and various other place names.
Word Vectors
In spaCy, word vectors represent words as dense numerical vectors. These vectors capture the semantic meaning of words based on their contextual usage. spaCy provides pre-trained word vectors for different languages, including English. In this section, use the vector attribute of a token object to access word vectors in spaCy as described below.
Create a new application
words_spacy.py$ nano words_spacy.pyAdd the following code to the file
import spacy nlp = spacy.load('en_core_web_sm') doc = nlp("I love coding") for token in doc: print(token.text, token.vector)Save and close the file
In the above code, the English model loads to handle processing of the input text
I love codingand iterate over each token in thedoc. For each token, you print its text and the corresponding word vector usingtoken.vector. The code output is a 300-dimensional vector for each token, representing its word vector. The specific value depends on the pre-trained word vectors used by the loaded model. in this caseen_core_web_sm.Run the application
$ python words_spacy.pyOutput:
I [ 0.31498 -0.11288 0.68746 0.30924 ...] love [ 0.04896 0.30181 -0.039086 0.28047 ...] coding [ 0.054043 0.36952 0.108363 0.080072 ...]The above output shows the word vector for each token in the input sentence. Each word vector represents a numerical array or vector where each element corresponds to a dimension of the vector.
Perform Sentiment Analysis Using NLTK and spaCy
To perform sentiment analysis, combine NLTK and spaCy to leverage the strengths of both libraries as described below.
Create a new application file
sentanlysis.py$ nano sentanlysis.pyAdd the following code to the file
import spacy from nltk.sentiment import SentimentIntensityAnalyzer nlp = spacy.load("en_core_web_sm") sia = SentimentIntensityAnalyzer() def analyze_sentiment(text): doc = nlp(text) sentiment_scores = sia.polarity_scores(text) combined_score = sentiment_scores["compound"] if combined_score >= 0.05: return "positive feedback" elif combined_score <= -0.05: return "negative feedback" else: return "neutral feedback" review = "Did you watch this movie?" """ Try also these two sentences to see difference in the output: I love this movie. It's stunning. I hated the movie. """ sentiment = analyze_sentiment(review) print("Your review is a", sentiment)Save and close the file
Run the application
$ python sentanlysis.py
When the application runs, it performs sentiment analysis using both NLTK and spaCy. It uses spaCy for tokenization and NLTK's SentimentIntensityAnalyzer for sentiment analysis.
When the review Did you watch this movie? is the input, the sentiment analysis function returns neutral feedback because the compound score of the sentiment analysis is likely to be close to zero for this sentence. The compound score shows the sentiment polarity of the text where positive values show positive feedback, negative values show negative feedback, and values close to zero show neutral feedback.
On trying the other two sentences, I love this movie. It's stunning. and I hated the movie., the sentiment analysis function returns a positive feedback and a negative feedback, based on the sentiment conveyed in the sentences.
Test it the application with different sentences to test its capabilities. Commonly, sentiment analysis applies in social media monitoring and analyzing of customer feedback in businesses
Introduction to Gensim
Gensim is a Python library used for topic modeling, document similarity analysis, and other Natural Language Processing (NLP) tasks. It offers efficient algorithms and data structures to process large textual corpora and extract meaningful information from them. In this section apply Gensim in your application as described if the following steps.
Topic modeling with Latent Dirichlet Allocation (LDA)
LDA is a common technique for extracting topics from a collection of documents. Gensim offers an efficient implementation of LDA. In this section, perform topic modeling with LDA using Gensim as described below/
Create a new python file
lda_gensim.py$ nano lda_gensim.pyAdd the following code to the file
import gensim from gensim import corpora from gensim.models import LdaModel sentences = [ "AI is the power of the future.", "NLP being its sub field its great equipping yourself with it", "Allows for communication and interaction between human and computer.", "Having a vast field of application" ] documents_list = [doc.split() for doc in sentences] dictionary = corpora.Dictionary(documents_list) corpus = [dictionary.doc2bow(doc) for doc in documents_list] lda_model = LdaModel(corpus, num_topics=10, id2word=dictionary) index = 0 topic = lda_model.print_topics(num_topics=10, num_words=10)[index] words = topic[1].split(' + ') topic_words = [word.split('*')[1].strip().strip('"') for word in words] document = ' '.join(topic_words) print("Topic:", document)Save and close the file
The above code performs topic modeling using the LDA algorithm from the Gensim library. It takes a list of sentences, splits them into individual words, creates a dictionary of unique words, and converts the sentences into a bag-of-words representation. The LDA model is then trained on the corpus, and printing of specific extracted topic based on the given index. The code allows for topic modeling analysis on the given documents.
Run the application
$ python lda_gensim.py
Word Embeddings with Word2Vec
Word2Vec is an algorithm used for learning word embeddings from large text datasets. Gensim includes an implementation of Word2Vec that allows you to train your own word embeddings or load pre-trained models. Implement Word2Vec with Gensim as described below.
Create a new application file
word2vec_gensim.py$ nano word2vec_gensim.pyAdd the following code to the file
from gensim.models import Word2Vec sentences = [ "AI is the power of the future.", "NLP being its AI sub field its great equipping yourself with it", "Allows for AI communication and interaction between human and computer.", "Having a vast AI field of application?" ] model = Word2Vec(sentences, window=5, min_count=1) vector = model.wv['AI']Save and close the file
The above code trains a Word2Vec model using Gensim on a list of preprocessed sentences. It sets the parameters for vector size, window size, and minimum word frequency. After training the model, it allows you to access word vectors using the trained model's
wvattribute. The code retrieves the word vector for the wordAI. The application's goal is to create word embeddings that capture the semantic relationships and contextual meaning of words within the given sentences.Run the application
$ python word2vec_gensim.py
Document Similarity and Indexing
Gensim offers document similarity and build document indexes for efficient retrieval. Create an application that computes document similarity using Gensim as described in the steps below.
Create a new application file
docsim_gensim.py$ nano docsim_gensim.pyAdd the following code to the file
from gensim import corpora, similarities from gensim.utils import simple_preprocess documents = [ "AI is the power of the future.", "NLP being its sub field its great equipping yourself with it", "Allows for communication and interaction between human and computer.", "Having a vast field of application?" ] tok_docs = [simple_preprocess(doc) for doc in documents] dictionary = corpora.Dictionary(tok_docs) corpus = [dictionary.doc2bow(doc) for doc in tok_docs] id = similarities.MatrixSimilarity(corpus) query = [ "AI is the power of the future.", "NLP being its sub field its great equipping yourself with it", "I love you so much" "This is the best of NLP", ] query_bow = dictionary.doc2bow(simple_preprocess(' '.join(query))) familiar_docs = id[query_bow] print(familiar_docs)Save and close the file
The above script tokenizes a list of documents, creates a bag-of-words corpus, and initializes a similarity index. It also defines query documents, tokenizes them, and retrieves similar documents based on the query. By applying tokenization, bag-of-words representation, and the similarity index, the application finds similar documents to a given query.
Run the application
$ python docsim_gensim.pyOutput:
[0.7222222 0.6471503 0. 0.2236068]
Text Classification
Using Gensim, you can train models to classify documents into predefined categories with machine learning algorithms such as Support Vector Machines (SVM) or Naive Bayes. In this section, perform text classification with Gensim as described below.
Create a new application file
text_class_gensim.py$ nano text_class_gensim.pyAdd the following code to the file
from gensim import corpora from gensim.models import TfidfModel from gensim.models import LsiModel from gensim.models import LdaModel from gensim import similarities from gensim.parsing.preprocessing import preprocess_string, remove_stopwords documents = [ "AI is the power of the future.", "NLP being its AI sub field its great equipping yourself with it", "Allows for AI communication and interaction between human and computer.", "Having a vast AI field of application?" ] labels = ["AI", "NLP"] p_docs = [preprocess_string(doc) for doc in documents] dictionary = corpora.Dictionary(p_docs) corpus = [dictionary.doc2bow(doc) for doc in p_docs] tfidf = TfidfModel(corpus) c_tfidf = tfidf[corpus] lsi = LsiModel(c_tfidf, id2word=dictionary, num_topics=10) id = similarities.MatrixSimilarity(lsi[corpus]) new_phrase = "I love all that comes with AI." preprocessed_new_phrase = preprocess_string(new_phrase) new_doc_bow = dictionary.doc2bow(preprocessed_new_phrase) new_doc_lsi = lsi[new_doc_bow] sims = id[new_doc_lsi] most_familiar_doc_index = sims.argmax() most_sim_label = labels[most_familiar_doc_index] print("Predicted label:", most_sim_label)Save and close the file
The above application pre-processes a set of documents, creates a dictionary and corpus, and applies TF-IDF and Latent Semantic Indexing (LSI) techniques. To measure the similarity between documents, create a similarity index using the LSI-transformed corpus. Then, pre-process and convert a new document into an LSI representation. Compute similarity scores between the new document and existing documents using the similarity index. Based on the highest similarity score, identify the most similar document and assign its label to the new document.
Run the application
$ python text_class_gensim.pyOutput:
Predicted label: AI
In summary, this application offers a basic approach to document classification using Gensim's TF-IDF, LSI, and similarity calculation capabilities. Automation of text analysis makes arranging all types of text data efficient and cost-effective as applied in emails, databases and other documents.
Conclusion
In this article, you explored various aspects of NLP, its applications and how to perform NLP tasks using Python's NLTK, spaCy, and Gensim libraries. For more information, visit the official documentation resources below:
No comments yet.