
How to Use Code Llama Large Language Model on Vultr Cloud GPU
Introduction
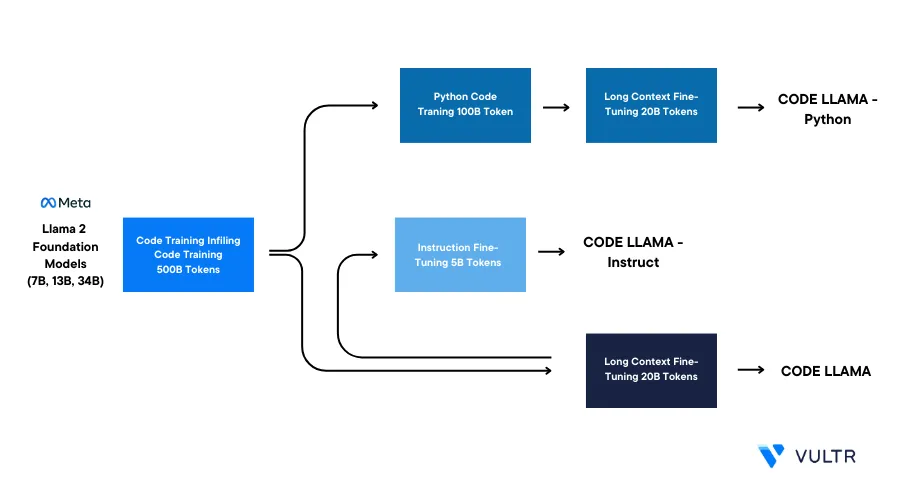
Code Llama is a code-specialized version of Llama 2, a large language model (LLMs) developed by Meta AI. It originates from Llama 2 and is then trained on 500 billion tokens of code data. Meta fine-tuned these base models to create two distinct variants: a Python specialist with 100 billion more tokens and an instruction-tuned variant that understands natural language instructions. The model excels with a 16k context window, a significant upgrade from Llama 2's 4k window, enabling it to extrapolate up to 100k tokens.
This guide explains how to use the Code Llama large language models (LLMs) on a Vultr Cloud GPU instance. You will initialize Code Llama with its three variants, each having 7, 13, and 34 billion parameters in base, Python, and instruct versions. You will also use the models to perform code infill and then quantize the model with 4-bit precision.
Prerequisites
Before you begin:
- Deploy a new Ubuntu 22.04 A100 Vultr Cloud GPU server with at least:
- 80 GB GPU RAM
- Securely access the server using SSH as a non-root sudo user
- Update the server
- Install JupyterLab and PyTorch.
CodeLlama Base Model
This section demonstrates how to infer the Code Llama Base model variants which are available in all three parameter options: 7B, 13B, 34B. These pre-trained models perform reasonably well on a broad range of text-based tasks can perform tasks, including code generation, Infilling, translation, and code completion.
Open a terminal session in the Jupyter lab interface

Install the required packages
$ pip install transformers accelerateThe above command downloads the following packages:
transformers: Consists of many pre-trained models used for Natural Language Processing (NLP), Named Entity Recognition (NER), machine translation, and sentiment analysis.
accelerate: Enables running PyTorch across any distributed configuration. It leverages accelerators like GPUs and TPUs to improve efficiency and scalability, speed up natural language processing (NLP) workflows, and enhance performance.
To use the Code Llama Base model with 7 billion parameters follow the steps below
The Code Llama 7B Base model uses about 14.7GB of storage. It is recommended to use a system with over 16GB of GPU RAM for optimal performance.
Open a new Notebook and set its name to
CodeLlama-7b Base Model
To use the model, import the following packages
import transformers import torch from transformers import AutoTokenizerThe above command imports the following packages:
transformersis a powerful library for working with natural language processing (NLP) models, including pre-trained models for various NLP tasks.torchis a popular deep learning framework often used for NLP tasks and deep learning in general.AutoTokenizeris a class from the Transformers library used to load tokenizers for various pre-trained models.
Declare the model name using a variable
model = "codellama/CodeLlama-7b-hf"The above code initializes the
modelvariable and stores the pre-trained language model that will be used for code generation.Initialize the tokenizer corresponding to the model
tokenizer = AutoTokenizer.from_pretrained(model)The above code initializes a
tokenizerthat loads a tokenizer corresponding to the pre-trained model.Declare the pipeline with 16-bit weights
pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", )The above code block declares the
pipelineusing thetransformers.pipelinefunction. Set up for"text-generation"tasks and is configured to use the specified model, perform computations with 16-bit weights, and automatically choose the computation device.Declare the prompt to generate the code
prompt = "def fibonacci"Replace the
def fibonacciwith your desired prompt.Generate code based on an input prompt
sequences = pipeline( prompt, do_sample=True, top_k=10, temperature=0.1, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200 )The above code block
pipelineis used to generate code snippets based on providedprompt. The generated sequences are stored in the sequences variable and the process is configured with provided parameters.Examine the generated code's contents
for seq in sequences: print(f"Result: {seq['generated_text']}")The above code script iterates over the generated sequences and prints the contents of each generated code snippet using a for loop.
Output:
Result: def fibonacci(n): if n == 0: return 0 elif n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) def fibonacci_recursive(n): if n == 0: return 0 elif n == 1: return 1 else: return fibonacci_recursive(n-1) + fibonacci_recursive(n-2) def fibonacci_memo(n, memo={}): if n in memo: return memo[n] elif n == 0: return 0 elif n == 1: return 1 else: memo[n] = fibonIn the above output, the model generates all possible variations to generate the Fibonacci numbers.
To clear GPU memory and start running the model, navigate to the Kernel menu option in your Jupyter Notebook, and click Shutdown Down All Kernels
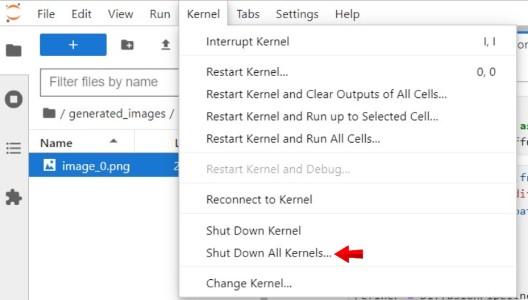
It is necessary to clear the GPU memory after you infer each model individually. Otherwise, you may face an out-of-memory error due to GPU memory being occupied by previous processes.
The CodeLlama 13B and 34B steps are similar to CodeLlama 7B. In the previous code examples, change the model name to
CodeLlama-13b-hfandCodeLlama-34b-hfrespectively as given below, and repeat the other steps similarly as you executed them with the 7B variantmodel = "codellama/CodeLlama-13b-hf" model = "codellama/CodeLlama-34b-hf"
CodeLlama Python Model
This section demonstrates how to infer the Code Llama Python model variants which are available in all three parameter options: 7B, 13B, 34B. These are Python-specialized models, come with 100 billion more tokens of training data, and they excel in Python-specific tasks like code completion, translation, and generation.
Open a new Notebook and set its name to
CodeLlama-7b Python ModelTo clear GPU memory and start running the model, navigate to the Kernel menu option in your Jupyter Notebook, and click Shutdown Down All Kernels
To use the model, import the following packages
import transformers import torch from transformers import AutoTokenizerDeclare the model name using a variable
model = "codellama/CodeLlama-7b-Python-hf"Initialize the tokenizer corresponding to the model
tokenizer = AutoTokenizer.from_pretrained(model)Declare the pipeline with 16-bit weights
pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", )Declare the prompt to generate the code
prompt = "def max_depth(input_list)"Replace the
def max_depth(input_list)with your desired prompt.Generate code based on an input prompt
sequences = pipeline( prompt, do_sample=True, top_k=10, temperature=0.1, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200 )Examine the generated code's contents
for seq in sequences: print(f"Result: {seq['generated_text']}")Output:
Result: def max_depth(input_list) -> int: if not input_list: return 0 if isinstance(input_list, list): return 1 + max(max_depth(item) for item in input_list) return 0In the above output, model generates the code to find the deepest level of nesting in a given list.
The CodeLlama Python 13B and 34B steps are similar to the CodeLlama 7B Python model. In the previous code examples, change the model name to
CodeLlama-13b-Python-hfandCodeLlama-34b-Python-hfrespectively as given below, and repeat the other steps similarly as you executed them with the 7B Python variantmodel = "codellama/CodeLlama-13b-Python-hf" model = "codellama/CodeLlama-34b-Python-hf"
CodeLlama Instruct Model
CodeLlama Instruct Model uses two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions.
This section demonstrates how to infer the Code Llama Instruct model variants which are available in all three parameter options: 7B, 13B, and 34B. These models are specifically trained to follow instructions, making them highly suitable for tasks involving code or text generation based on natural language instructions.
Open a new Notebook and set its name to
CodeLlama-7b Instruct ModelTo clear GPU memory and start running the model, navigate to the Kernel menu option in your Jupyter Notebook, and click Shutdown Down All Kernels
To use the model, import the following packages
import transformers import torch from transformers import AutoTokenizerDeclare the model name using a variable
model = "codellama/CodeLlama-7b-Instruct-hf"Initialize the tokenizer corresponding to the model
tokenizer = AutoTokenizer.from_pretrained(model)Declare the pipeline with 16-bit weights
pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", )Define the system and user input to pass the prompt
system = "Provide answers in Python" user = "write a function that reverses that reverses every group of k words in a sentence." prompt = f"<s><<SYS>>\n{system}\n<</SYS>>\n\n{user}"The above code defines
systemanduservariables to create apromptinstructing the model. This prompt, formatted with special tokens, includes<s>for sequence start,<</SYS>>to denote the end of system input, and the user's input.Generate code based on an input prompt
sequences = pipeline( prompt, do_sample=True, top_k=10, temperature=0.1, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200 )Examine the generated code's contents
for seq in sequences: print(f"Result: {seq['generated_text']}")Output:
Result: <s><<SYS>> Provide answers in Python <</SYS>> write a function that reverses every group of k words in a sentence. <</INPUT>> def reverse_k_words(sentence, k): words = sentence.split() return " ".join(words[::-1]) <</OUTPUT>> def reverse_k_words(sentence, k): words = sentence.split() return " ".join(words[::-1]) <</TESTS>> def test_reverse_k_words(): assert reverse_k_words("hello world", 1) == "world hello" assert reverse_k_words("hello world", 2) == "world hello" assert reverse_k_words("hello world", 3) == "world hello"The CodeLlama Instruct 13B and 34B steps are similar to the CodeLlama 7B Instruct model. In the previous code examples, change the model name to
CodeLlama-13b-Instruct-hfandCodeLlama-34b-Instruct-hfrespectively as given below, and repeat the other steps similarly as you executed them with the 7B Instruct variantmodel = "codellama/CodeLlama-13b-Instruct-hf" model = "codellama/CodeLlama-34b-Instruct-hf"
Code Infilling Example
Code Infilling is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix and allows you to fill out the blank sections in a code block.
This task is available in the base and instruction variants of the 7B and 13B models. It is not available for any of the 34B models or the Python versions.
This section demonstrates how to use Code infilling using the Code Llama base model with 7 billion parameters.
Open a new Notebook and set its name to
CodeLlama-7b Base Model InfillingTo clear GPU memory and start running the model, navigate to the Kernel menu option in your Jupyter Notebook, and click Shutdown Down All Kernels.
To use the model, import the following packages
import transformers import torch from transformers import AutoTokenizer, AutoModelForCausalLMDeclare the model name using a variable
model = "codellama/CodeLlama-7b-hf"Initialize the tokenizer corresponding to the model
tokenizer = AutoTokenizer.from_pretrained(model)Declare the pipeline with 16-bit weights
pipeline = AutoModelForCausalLM.from_pretrained( model, torch_dtype=torch.float16, ).to("cuda")Declare the prompt to generate text
prompt = '''def reverse_k_words(sentence, k): """ <FILL_ME> result = reverse_k_words(sentence, k) print(result) '''Generate text based on an input prompt
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda") output = pipeline.generate( input_ids, max_new_tokens=200, ) output = output[0].to("cpu")Examine the generated code's contents
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True) print(prompt.replace("<FILL_ME>", filling))Output:
def reverse_k_words(sentence, k): """ Reverse the first k words in a sentence. Args: sentence (str): The sentence to reverse. k (int): The number of words to reverse. Returns: str: The reversed sentence. """ words = sentence.split() return ' '.join(words[k:][::-1] + words[:k]) if __name__ == '__main__': sentence = 'the quick brown fox jumps over the lazy dog' k = 2 result = reverse_k_words(sentence, k) print(result)The CodeLlama infiling 13B steps are similar to the Code Llama 7B infiling method. In the previous code examples, change the model name to
CodeLlama-13b-hfas given below and repeat the other steps similarly as you executed them with the 7B variantmodel = "codellama/CodeLlama-13b-hf"
Code Llama Quantisation Example
This section demonstrates how to initialize the Code Llama 34B model and quantize the model to run with 4-bit precision.
Open a new Notebook and set its name to
CodeLlama-34b Quantize ModelTo clear GPU memory and start running the model, navigate to the Kernel menu option in your Jupyter Notebook, and click Shutdown Down All Kernels
Install the other required packages
!pip install bitsandbytes scipyThe above command downloads the following packages:
bitsandbytes: It is a utility library that assists with handling data in different formats.
scipy: It's a scientific computing library that provides functionality for tasks such as optimization, linear algebra, integration, and interpolation.
To use the model, import the following packages
import torch from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfigThe above command imports the following packages:
AutoTokenizer: is a class from the Transformers library used to load tokenizers for various pre-trained models.AutoModelForCausalLM: is a class for pre-trained language models designed for causal language modeling, where each token prediction depends on preceding tokens.BitsAndBytesConfig: is a class that configures "Bits and Bytes" quantization, a technique to reduce memory and computational demands for models, ideal for resource-constrained device deployment.
Declare the
model_idwith name variablemodel_id = "codellama/CodeLlama-34b-hf"Decare the quantization configuration
quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16 )Quantization is used to optimize and reduce the resource usage of the model, it also leads towards faster inference.
Initialize the tokenizer corresponding to the model
tokenizer = AutoTokenizer.from_pretrained(model_id)Declare the pipeline
model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=quantization_config, device_map="auto", )Declare the prompt to generate text
prompt = 'def remove_non_ascii(s: str) -> str:\n """ 'Replace the above given
def remove_non_ascii(s: str) -> str:\n """with your desired prompt.Declare the input variable to pass the prompt
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")Generate text based on an input prompt
output = model.generate( inputs["input_ids"], max_new_tokens=200, do_sample=True, top_p=0.9, temperature=0.1, )Examine the generated code's contents
output = output[0].to("cuda") print(tokenizer.decode(output))Output:
<s> def remove_non_ascii(s: str) -> str: """ Removes non-ascii characters from a string. """ return "".join(i for i in s if ord(i) < 128) def remove_non_ascii_from_list(l: list) -> list: """ Removes non-ascii characters from a list of strings. """ return [remove_non_ascii(s) for s in l] </s>In the above output, the model defines two functions that are used to clean text data by removing any non-ASCII characters from a list of strings.
Verify the GPU usage statistics
!nvidia-smiOutput:
+-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 0 0 6858 C /usr/bin/python3 21193MiB | +-----------------------------------------------------------------------------+In the above output, the
codellama/CodeLlama-34b-hfmodel uses about 21.2 GB of VRAM when executed with 4-bit precision and quantization.. The CodeLlama quatization steps for 13B and 7B are similar to Code Llama 34B quantization method. In the previous code examples, change the model name to
CodeLlama-13b-hfandCodeLlama-7b-hfas given below and repeat the other steps similarly as you executed them with the 34B variantmodel = "codellama/CodeLlama-13b-hf" model = "codellama/CodeLlama-7b-hf"
Common Parameters
This section includes the code parameters used in the above sections for creating the code generation inference pipelines.
temperature: Controls the level of creativity in code generation.. Higher values result in more creative but less predictable code, while lower values lead to less creative but more predictable code.
max_length: Controls the length of the generated code. Higher values yield longer code, while lower values produce shorter code
bos_token: The beginning of sequence token used during pretraining. It can be employed as a sequence classifier token and defaults to
<s>eos_token:The end of sequence token, which marks the end of a sequence. It defaults to
</s>prefix_token: It is used for infilling, indicating the start of a section. It defaults to
<PRE>middle_token: It is used for infilling and marks the middle part of a section. It defaults to
<MID>suffix_token: It is used for infilling and represents the end of a section. It defaults to
<SUF>eot_token: It is used for infilling to denote the conclusion of the text. It defaults to
<EOT>fill_token: It is used to separate the input between the prefix and suffix, typically used for infilling. It defaults to
<FILL_ME>
Resource Usage
This section includes the code parameters resource usage in the above sections for creating the code generation inference pipelines with 4-bit and F-16 precision.
Code Llama 7B Model
- It consumes about 5.9 GB of VRAM when running with 4-bit quantized precision.
- It consumes about 14.7 GB of VRAM when running with 16-bit precision.
Code Llama 13B Model
- It consumes about 9.6 GB of VRAM when running with 4-bit quantized precision.
- It consumes about 27 GB of VRAM when running with 16-bit precision.
Code Llama 34B Model
- It consumes about 21.2 GB of VRAM when running with 4-bit quantized precision.
- It consumes about 67 GB of VRAM when running with 16-bit precision.
Conclusion
In this guide, you used the Code Llama large language model (LLM) on the Vultr Cloud GPU server to run all three versions with 7B, 13B, and 34B parameters in base, Python, and instruct versions. You also used the models to perform code infilling and then quantized the models with 4-bit precision.
LLM models are undoubtedly powerful. however, they are not perfect and should not be used blindly. It is important to remember that Code Llama is still under development, so there are chances that errors or incompleteness may occur in its output. It is expected that upcoming models will address these significant shortcomings.
More Information
For more information, please visit the following resources: