

Introduction
Embeddings are the numerical representation of human-readable words and sentences. These numerical representations help in plotting high-dimensional data into a lower-dimensional space. They capture the similarities and relationships between textual objects, with the embeddings usable for semantic similarity search, text retrieval, sentiment analysis, document clustering, and contextual understanding.
This article explains how to use vector embeddings with Python on a Vultr Cloud GPU server. You are to use the sentence-transformer Python framework as it offers many advantages and semantic sentence embeddings as its primary strength. The framework pairs with the all-MiniLM-L6-v2 model which maps words with a dense vector space and offers a high performance benchmark.
By using sentence-transformer, you are to generate embeddings for any given text sentence, compare the similarity between two sentences, and compare the similarity index between multiple sentence pairs.
Prerequisites
Before you begin, you should:
- Deploy a fresh Ubuntu NVIDIA A100 Server on Vultr with at least:
- 10 GB GPU RAM
- Using SSH, access the server.
- Create a non-root user with sudo privileges and switch to the user account.
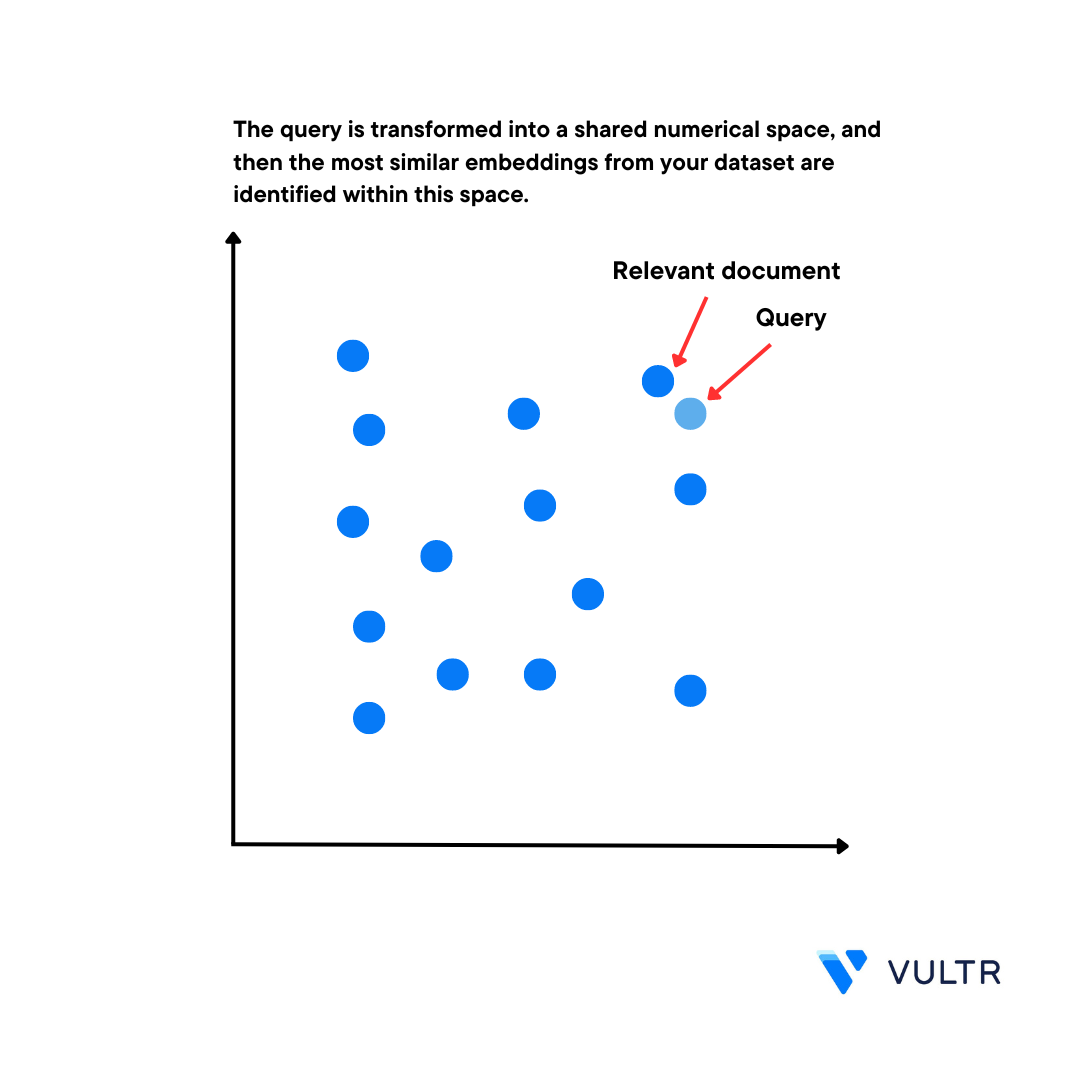
How Embeddings Work
Embeddings give you the relationship between multiple text sentences. In a multi-dimensional space, similar text groups are close to each other, and completely different text groups are distant from each other with the help of the dimensions created by neural network-based techniques like Word2Vec, GloVe, and FastText.
These techniques work on the following two principles:
- Skip-gram Model: The model tries to predict the surrounding words in a sentence based on your input text prompt
- Continuous Bag of Words (CBOW) Model: The model tries to predict the target word based on your input text
Create Embeddings
In this section, install the required libraries to run the sentence transformers model on the server to create embeddings for the text you enter in your Python script.
Install PyTorch
$ pip3 install torch --index-url https://download.pytorch.org/whl/cu118The above command installs the PyTorch library on the server with CUDA support. To install the latest version that matches your CUDA version, visit the PyTorch installation page.
Install the
sentence-transformerPython framework$ pip3 install -U sentence-transformersThe
sentence-transformerframework allows you to compute and create embeddings in many languages.Using a text editor such as
Nano, create a new Python file namedcreate-embeddings.py$ nano create-embeddings.pyAdd the following contents to the file
from sentence_transformers import SentenceTransformer model = SentenceTransformer('all-MiniLM-L6-v2') sentences = [ 'This is sentence 1', 'This is sentence 2', 'This is sentence 3' ] embeddings = model.encode(sentences) for sentence, embedding in zip(sentences, embeddings): print("Sentence:", sentence) print("Embedding:", embedding) print("")Save and close the file
In the above code, the
all-MiniLM-L6-v2model in use trains on a large and diverse dataset of 1 billion pairs. It consumes less disk storage and is significantly faster than other models, it also has 384 dimensions enough to return relevant results.Run the program file
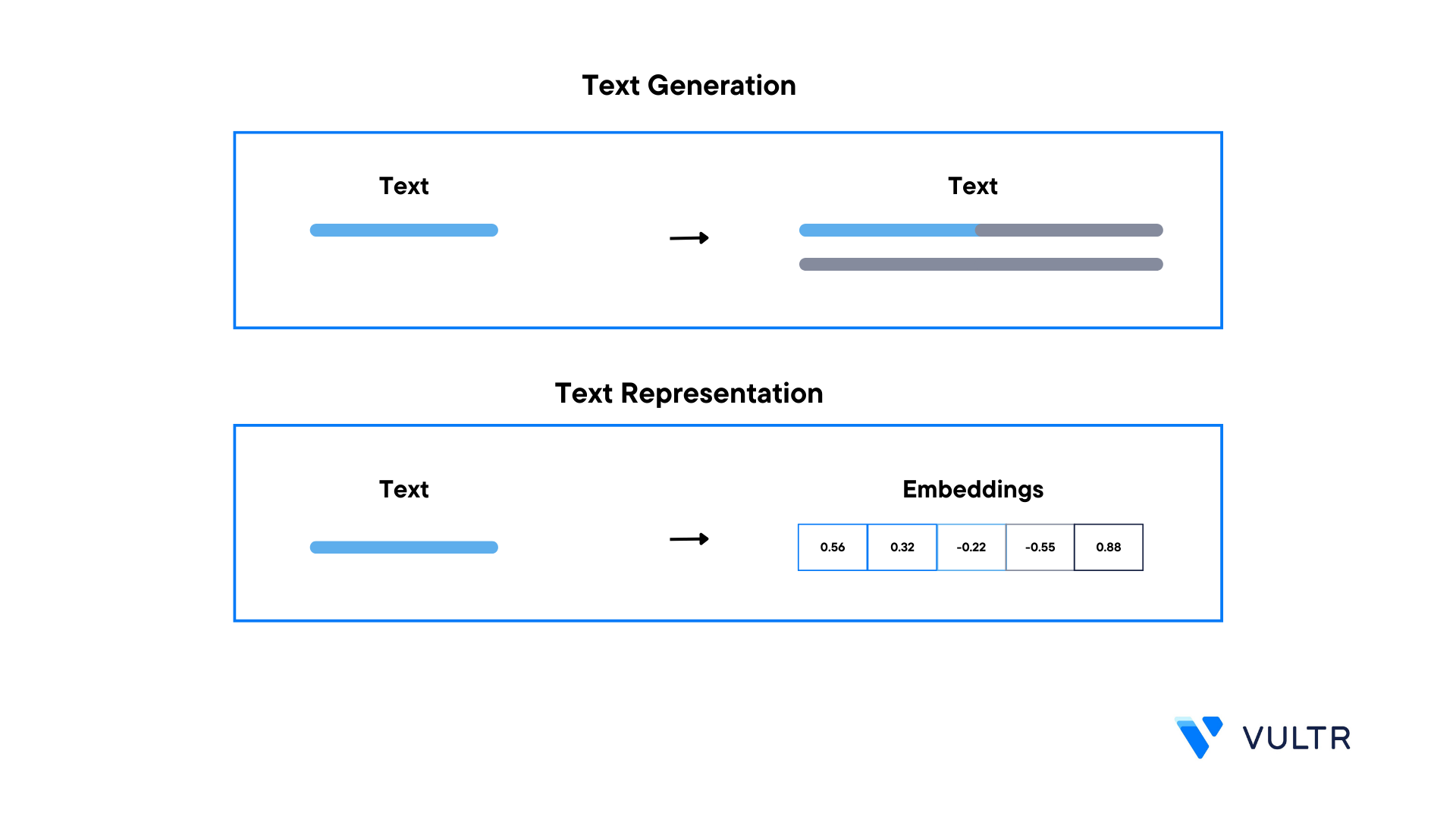
$ python3 create-embeddings.pyWhen successful, sentence embedding vectors display in your output like the one below:
Sentence: This is sentence 1 Embedding: [ 3.56232598e-02 6.59520105e-02 6.31771907e-02 4.98925485e-02 4.25567515e-02 1.73298120e-02 1.29241705e-01 -5.35381809e-02 3.49053964e-02 -1.09756496e-02 7.27292225e-02 -7.02433810e-02 ......... ]As displayed in the output, the text generation outputs text, while text representation outputs embeddings
Calculate Cosine Similarity Between Two Sentences
Cosine similarity is a metric that's calculated by determining the cosine angle of the vectors plotted in a multi-dimensional space. Further, it calculates the similarity between vectors to determine how similar two given sentences are. In this section, calculate the cosine similarity between two given sentences using the all-MiniLM-L6-v2 model.
Create a new file named
cosine-similarity.py$ nano cosine-similarity.pyAdd the following code to the file
from sentence_transformers import SentenceTransformer, util model = SentenceTransformer('all-MiniLM-L6-v2') emb1 = model.encode("This is sentence 1") emb2 = model.encode("This is sentence 2") cos_sim = util.cos_sim(emb1, emb2) print("Cosine-Similarity:", cos_sim)Save and close the file
The above code block takes two sentences and encodes them using
model.encode()to create their respective embeddings and encode them into vectors.Run the file
$ python3 cosine-similarity.pyOutput:
Cosine-Similarity: tensor([[0.9145]])As displayed in the output, the closer the cosine similarity tensor value is to 1, the more similar the embedding vectors are.
Calculate Top Similar Sentence Pairs
In this section, calculate the top 5 sentence pairs based on their similarity by giving a corpus of many sentences using the all-MiniLM-L6-v2 model.
Create a new file named
top-similar-pairs.py$ nano top-similar-pairs.pyAdd the following code to the file
from sentence_transformers import SentenceTransformer, util model = SentenceTransformer('all-MiniLM-L6-v2') sentences = [ 'A man is eating food.', 'A man is eating a piece of bread.', 'The girl is carrying a baby.', 'A man is riding a horse.', 'A woman is playing violin.', 'Two men pushed carts through the woods.', 'A man is riding a white horse on an enclosed ground.', 'A monkey is playing drums.', 'Someone in a gorilla costume is playing a set of drums.' ] embeddings = model.encode(sentences) cos_sim = util.cos_sim(embeddings, embeddings) all_sentence_combinations = [] for i in range(len(cos_sim)-1): for j in range(i+1, len(cos_sim)): all_sentence_combinations.append([cos_sim[i][j], i, j]) all_sentence_combinations = sorted(all_sentence_combinations, key=lambda x: x[0], reverse=True) print("Top-5 most similar pairs:") for score, i, j in all_sentence_combinations[0:5]: print("{} \t {} \t {:.4f}".format(sentences[i], sentences[j], cos_sim[i][j]))Save and close the file
The above code block takes in a corpus of multiple sentences. It encodes them using
model.encode()to create embedding vectors, and calculates the cosine similarity between all those sentence pairs. After calculation, a list of sentences generates with the respective cosine similarity scores. Then, the list sorts according to the highest cosine similarity score, and all the top 5 pair of sentences display in the program output.Run the program file
$ python3 top-similar-pairs.pyOutput:
Top-5 most similar pairs: A man is eating food. A man is eating a piece of bread. 0.7553 A man is riding a horse. A man is riding a white horse on an enclosed ground. 0.7369 A monkey is playing drums. Someone in a gorilla costume is playing a set of drums. 0.6433 A woman is playing violin. Someone in a gorilla costume is playing a set of drums. 0.2564 A man is eating food. A man is riding a horse. 0.2474In the above output, the top 5 pairs that are closely match with each other are displayed, the sentence pair with a cosine similarity closer to 1 is the most similar pair.
Conclusion
In this article, you discovered the fundamentals of embeddings and how to make embedding vectors using custom input, you also calculated the similarity between two text sentences and ranked the top 5 pairs of similar text sentences. For more information on how to use embeddings models applied in this article, visit thesentence transformer documentation or all-MiniLM-L6-v2 documentation.
Next Steps
To implement additional solutions and leverage the power of your Vultr Cloud GPU server, visit the following resources:
No comments yet.