

Introduction
Langchain is an Artificial Intelligence (AI) framework that simplifies coding when creating apps that implement external data sources and Large Language Models(LLMs).
You can use the framework to create personal assistants, chatbots, Q&A applications, and more. Langchain ships with different libraries that allow you to interact with various data sources like PDFs, spreadsheets, and databases (For instance, Chroma, Pinecone, Milvus, and Weaviate).
Chroma is an open-source embedding database that accelerates building LLM apps that require storing vector data and performing semantic searches.
In this guide, you'll implement the Langchain framework to orchestrate LLMs with a Chroma database.
Prerequisites
Before you begin:
Deploy a new Ubuntu 22.04 A100 Vultr Cloud GPU Server with at least:
- 80 GB GPU RAM
- 12 vCPUs
- 120 GB Memory
Create a non-root user with
sudorights and switch to the account.
Install the Required Python Libraries
You need to install the following Python libraries. Later on this guide, you'll run some Python scripts that use the libraries to work:
$ sudo apt update
$ pip install huggingface-hub pypdf langchain text_generation sentence-transformers chromadb gradio
$ pip install -U jinja2
Run the Hugging Face Text Generation Inference Container
This guide requires Llama 2 model API. You'll expose the API by running the Hugging Face text generation inference Docker container. Follow the steps below:
Initialize the Docker container variables. Replace
$HF_TOKENwith your correct Hugging Face token.console$ model=meta-llama/Llama-2-7b-chat-hf volume=$PWD/data token=$HF_TOKEN
Run the Hugging Face text generation Docker container.
console$ sudo docker run -d \ --name hf-tgi \ --runtime=nvidia \ --gpus all \ -e HUGGING_FACE_HUB_TOKEN=$token \ -p 8080:80 \ -v $volume:/data \ ghcr.io/huggingface/text-generation-inference:1.1.0 \ --cuda-memory-fraction 0.5 \ --model-id $model \ --max-input-length 2048 \ --max-total-tokens 4096
Wait for the container to download and load. Then, check the logs to ensure the container listens for incoming connections.
console$ sudo docker logs -f hf-tgi
Ensure you get the following output.
Status: Downloaded newer image for ghcr.io/huggingface/text-generation-inference:1.1.0 c820c75b4a29ebff7a889443e65305bbf2b632b9299ffc6f3d445353ac1dbbd4
Implement a Basic Langchain Script
Follow the steps below to create a sample Langchain application to generate a query based on a prompt:
Create a new
langchain-llama.pyfile using a text editor likenano.console$ nano langchain-llama.py
Enter the following information into the
langchain-llama.pyfile.pythonfrom langchain.llms import HuggingFaceTextGenInference import warnings warnings.simplefilter('ignore') URI = "http://127.0.0.1:8080/" llm = HuggingFaceTextGenInference(inference_server_url = URI) print(llm("What is the capital of France?").strip())
Save and close the file.
Run the file.
console$ python3 langchain-llama.py
Output:
The capital of France is Paris.
Prompt a Langchain Application
The Langchain framework accepts LLM prompts. Incorporate the prompt in your Python code by following the steps below:
Open a new
langchain-llama-prompt.pyfile.console$ nano langchain-llama-prompt.py
Enter the following information into the
langchain-llama-prompt.pyfile.pythonfrom langchain.llms import HuggingFaceTextGenInference from langchain.llms import HuggingFaceTextGenInference from langchain import PromptTemplate from langchain.schema import StrOutputParser import warnings warnings.simplefilter('ignore') URI = "http://127.0.0.1:8080/" llm = HuggingFaceTextGenInference(inference_server_url = URI) template = """ <s>[INST] <<SYS>> {role} <</SYS>> {text} [/INST] """ prompt = PromptTemplate( input_variables = [ "role", "text" ], template = template, ) role = "Act as a Machine Learning engineer who is teaching high school students." text = "Explain what is artificial intelligence in 2-3 sentences" print(prompt.format(role = role, text = text)) chain = prompt | llm | StrOutputParser() print(chain.invoke({"role": role,"text":text}))
Save and close the file.
Run the file
console$ python3 langchain-llama-prompt.py
Output:
Hey there, young minds! *excited tone* Artificial intelligence (AI) is like a superhero for computers - it gives them the power to think and learn like humans! AI is a field of computer science that focuses on creating machines that can perform tasks that typically require human intelligence, like recognizing images, understanding speech, and making decisions. Just like how superheroes have special powers, AI algorithms have the ability to learn from data and improve their performance over time! 💻🦸♂️
Integrate Langchain with Chroma Database and Llama 2 Model
In this step, you'll use a sample speech from Steve Jobs and integrate Langchain with a Chroma database. Follow the steps below:
Download the sample PDF file using the Linux
wgetcommand:console$ wget https://docs.vultr.com/public/doc-assets/new/using-langchain-with-llama-2-generative-ai-series/steve-jobs.pdf
Open a new
langchain_chroma.pyfile.console$ nano langchain_chroma.py
Enter the following information into the
langchain_chroma.pyfile.pythonfrom pypdf import PdfReader from langchain.llms import HuggingFaceTextGenInference from langchain.embeddings import HuggingFaceEmbeddings from langchain.chains.question_answering import load_qa_chain from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import Chroma from langchain.schema import StrOutputParser import joblib import os import warnings warnings.filterwarnings('ignore') URI = "http://127.0.0.1:8080/" model_id = "meta-llama/Llama-2-13b-chat-hf" llm = HuggingFaceTextGenInference(inference_server_url = URI, max_new_tokens = 2000) template = """ <s>[INST] <<SYS>> You are a helpful AI assistant. Answer based on the context provided. If you cannot find the correct answer, say I don't know. Be concise and just include the response. <</SYS>> {context} Question: {question} Helpful Answer: [/INST] """ prompt = PromptTemplate.from_template(template) reader = PdfReader('steve-jobs.pdf') raw_text = '' for i, page in enumerate(reader.pages): text = page.extract_text() if text: raw_text += text text_splitter = CharacterTextSplitter( separator = " \n", chunk_size = 500, chunk_overlap = 20, length_function = len, ) texts = text_splitter.split_text(raw_text) texts[1] embeddings_file = "./data/steve-jobs.joblib" if os.path.exists(embeddings_file): embeddings = joblib.load(embeddings_file) else: embeddings = HuggingFaceEmbeddings() joblib.dump(embeddings, embeddings_file) vectorstore = Chroma.from_texts(texts, embeddings) retriever = vectorstore.as_retriever() chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm ) query = "Where did Steve Jobs deliver this speech?" retriever.get_relevant_documents(query) print(chain.invoke(query))
Save and close the file.
Run the file.
console$ python3 langchain_chroma.py
Output:
Steve Jobs delivered this speech at Stanford University in 2005.
Creating a Q&A Application with Langchain and LLama 2 Model
Langchain has a built-in library for creating professional-looking user interfaces for chats. Follow the steps below to create a Web interface for your application:
Create a new
chatbot.pyfile.console$ nano chatbot.py
Enter the following information into the
chatbot.pyfile.pythonfrom pypdf import PdfReader from langchain.llms import HuggingFaceTextGenInference from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain.text_splitter import CharacterTextSplitter import joblib import os import gradio as gr import warnings # Suppress warnings warnings.filterwarnings('ignore') # Constants URI = "http://127.0.0.1:8080/" MODEL_ID = "meta-llama/Llama-2-13b-chat-hf" EMBEDDINGS_FILE = "./data/steve-jobs.joblib" PDF_FILE = 'steve-jobs.pdf' TEMPLATE = """ <s>[INST] <<SYS>> You are a helpful AI assistant. Answer based on the context provided. If you cannot find the correct answer, say I don't know. Be concise and just include the response. <</SYS>> {context} Question: {question} Helpful Answer: [/INST] """ # Initialize large language model llm = HuggingFaceTextGenInference(inference_server_url = URI, max_new_tokens = 2000) # Create a prompt template prompt = PromptTemplate.from_template(TEMPLATE) # Function to read and extract text from PDF def extract_text_from_pdf(pdf_file): reader = PdfReader(pdf_file) raw_text = '' for page in reader.pages: text = page.extract_text() if text: raw_text += text return raw_text # Function to get or create embeddings def get_or_create_embeddings(texts, embeddings_file): if os.path.exists(embeddings_file): return joblib.load(embeddings_file) embeddings = HuggingFaceEmbeddings() joblib.dump(embeddings, embeddings_file) return embeddings # Main chatbot function def mychatbot(query, history): raw_text = extract_text_from_pdf(PDF_FILE) text_splitter = CharacterTextSplitter(separator=" \n", chunk_size=500, chunk_overlap=20, length_function=len) texts = text_splitter.split_text(raw_text) embeddings = get_or_create_embeddings(texts, EMBEDDINGS_FILE) vectorstore = Chroma.from_texts(texts, embeddings) retriever = vectorstore.as_retriever() retriever.get_relevant_documents(query) chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm) return chain.invoke(query) # Gradio interface setup gr.ChatInterface( mychatbot, chatbot = gr.Chatbot(height = 300), textbox = gr.Textbox(placeholder="Ask me a question", container = False, scale = 7), title = "My Chatbot", description = "Custom Chatbot for your PDF", theme = "soft", examples = [ "Where did Steve Jobs deliver this speech?", "Where did Steve Jobs start Apple?", "Apart from Apple, which other companies were founded by Steve Jobs?", "What was the bible of Steve Jobs?", "Who created the The Whole Earth Catalog and when?", "What was in The Whole Earth Catalog?", "What are the 3 key takeaways from Steve Jobs speech?", ], cache_examples = False, retry_btn = None, undo_btn = "Delete Previous", clear_btn = "Clear" ).launch(share = True)
Save and close the file.
Run the file.
console$ python3 chatbot.py
Output:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://860a379e601450d71e.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)Access the web interface by navigating to the public URL mentioned in the output.
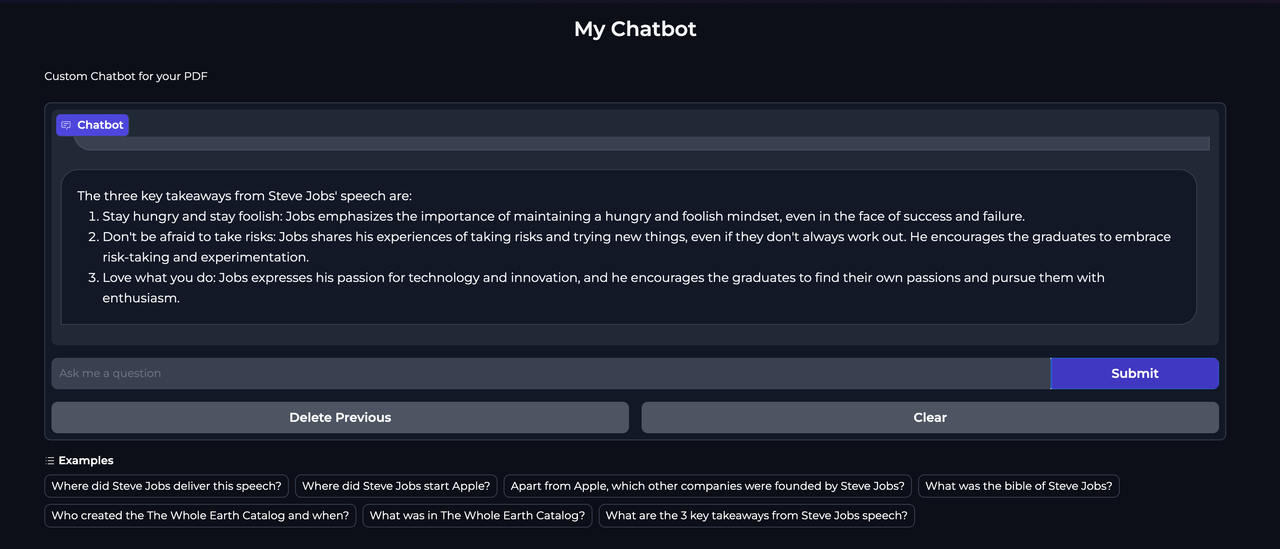
Conclusion
In this guide, you have implemented the Langchain framework to orchestrate LLMs with the Chroma vector database. You've also created a chatbot using Chroma that exposes the functionalities of the Llama 2 model in a web interface.
- Generative AI for Developers | Generative AI Series
- Understanding Foundation Models | Generative AI Series
- A Deeper Dive Into Large Language Models | Generative AI Series
- Interacting with Llama 2 | Generative AI Series
- Implementing RAG with Chroma and Llama 2 | Generative AI Series
- Using LangChain with Llama 2 | Generative AI Series
- Fine-Tuning Llama 2 | Generative AI Series
- Generating Images with Stable Diffusion | Generative AI Series
- Transcribing and Translating Audio | Generative AI Series
No comments yet.