
Asynchronous Task Queueing in Python using Celery

Introduction
Celery is a task queue/job queue based on asynchronous message passing. It can be used as a background task processor for Python applications in which you dump your tasks to execute in the background or at any given moment. It can be configured to execute your tasks synchronously or asynchronously.
Asynchronous message passing is a system in which the messages are stored between the sender & receiver. This allows the sender to move on to other things as soon as the message has been sent & can also stack up multiple messages before the receiver has taken any action.
Main Components of Celery:
- Tasks
- Task Broker
- Result Backend
- Worker
Tasks are the functions that you are going to send to Celery to execute in its worker. These are normal Python functions with a decorator to separate them from the rest of the functions.
Task Broker is the message passing system that you are going to use to communicate with Celery to send tasks for execution. Celery supports many brokers such as Redis®, RabbitMQ, Amazon SQS, etc.
Result Backend is again a message-passing system but in this case, Celery uses this to store the task execution result which then can be accessed from your application. It supports many result backends such as Redis®, RabbitMQ (AMQP), SQLAlchemy, etc.
Worker is self-explanatory, it's a Celery process that keeps running in the background waiting for tasks to arrive in task broker, generally multiple workers are running together to achieve concurrent executions.
Task Life Cycle in Celery
Process of Task Execution by Celery can be broken down into:
- Task Registration
- Task Execution
- Result Storage
Your application sends the tasks to the task broker, it is then reserved by a worker for execution & finally the result of task execution is stored in the result backend.
Applications of Celery
Understanding Celery can be a bit hectic without knowing its proper applications of it. There are many different ways you can use integrate it into your application.
Most Common Applications of Celery:
- Periodic Execution - Tasks that need to run periodically after an interval such as sending a monthly newsletter.
- Third-party Execution - Tasks that interact with third-party services such as sending emails through SMTP.
- Long-running Execution - Tasks that take a long time to complete execution such as compressing files.
Creating Your First Program with Celery
In this section, you will be learning how to integrate Celery tasks into a Python program.
Prerequisites
To complete this guide, you will need:
- Python 3.7 or newer
- Redis® Server, follow Install and Configure Redis® on Ubuntu 20.04
Installing Celery
Celery is written in Python and can be installed using Python's package installer (pip).
Install the latest version of Celery:
pip install celeryInstall the required dependencies to use Redis® with Celery:
pip install celery[redis]Writing Your First Celery Task
Here we have broken down a very basic program demonstrating how you can write or convert your existing functions to a Celery task. You can copy & paste the final code mentioned in the end to test it by yourself.
Import & Initialize Celery Object from Celery Python Package
Import Celery class from celery python package and initialize it into any variable, here we have used the app variable. The first argument passed to the class is the name of our application.
from celery import Celery
app = Celery(
'tasks',
broker="redis://localhost:6379/0",
backend="redis://localhost:6379/0"
)As we are using Redis® for both our broker and backend we have specified it using keyword arguments. If you're not using Redis® default configuration, you can write a connection string for your environment using the following format.
redis://username:password@hostname:port/dbCreate Basic Celery Task
You can convert any function into a Celery task using the @app.task decorator which adds all the necessary functionality required for our existing function to run as a task.
@app.task
def multiply(a, b):
import time
time.sleep(5)
return a * bFinal Code
You can copy and paste the final code into a new file named tasks.py to follow the instructions given in the next section.
from celery import Celery
app = Celery(
'tasks',
broker="redis://localhost:6379/0",
backend="redis://localhost:6379/0"
)
@app.task
def multiply(a, b):
import time
time.sleep(5)
return a * bManaging Celery Workers
After you're done writing down your tasks, you need workers which will process tasks whenever you execute them.
Start Celery Workers
Start a Celery worker by running the given command to follow the instructions given in the next section. Make sure you're in the same directory in which you saved tasks.py
Start Celery Worker:
celery -A tasks worker -n worker1 -P prefork -l INFOExpected Output:
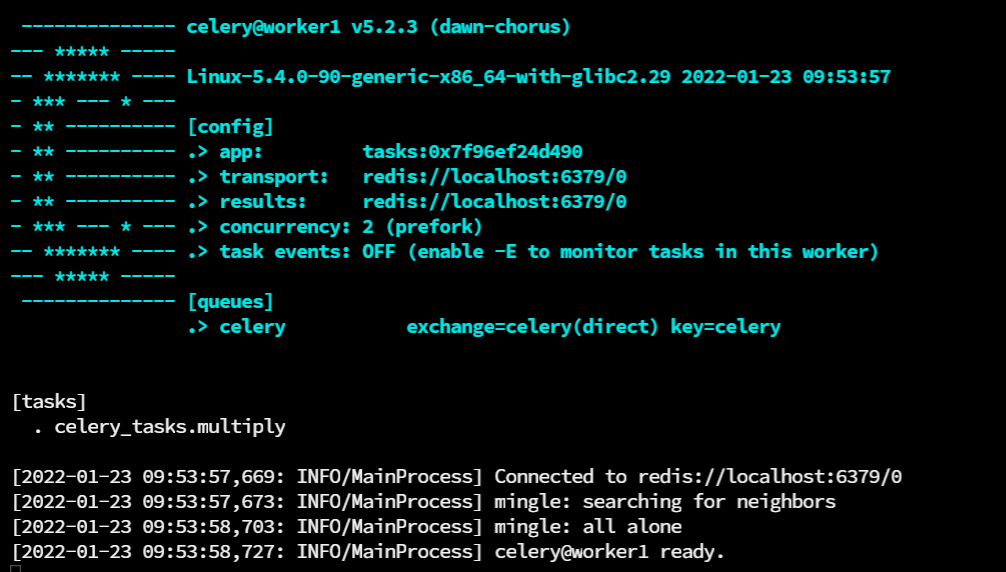
Arguments Used:
-Ais short for--appit is used to specify the application the worker will be working with.-nis short for--hostnameit is used to specify a name to the worker.-Pis short for--poolit is used to specify the type of pool, types of workers are discussed below.-lis short for--loglevelit is used to specify the log level of our worker.
You can also use -D which is short for --detach to run workers in the background.
Stop Celery Workers
When you're done processing all your tasks you can shut down your workers manually by running the given command.
Kill all running Celery workers:
ps auxww | awk '/celery(.*)worker/ {print $2}' | xargs kill -9Executing Tasks in Celery Workers
Now that the worker is up and ready to process the queue, open a new console and execute python command to open a python console. Make sure you're in the same directory in which you saved tasks.py
Import the task:
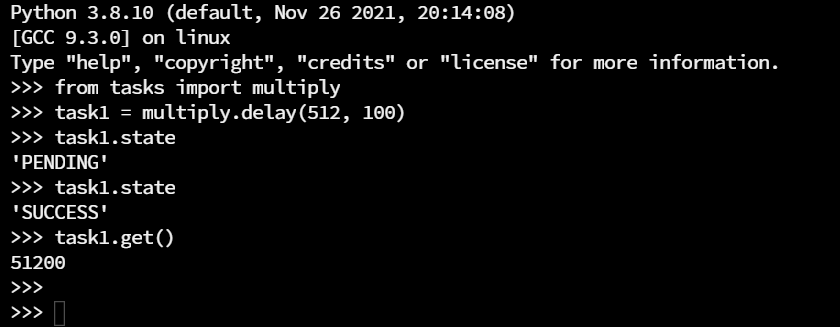
from tasks import multiplyExecute the task:
Use .delay() function to send the task execution request to the message broker.
task1 = mutliply.delay(512, 100)Check task state:
Use .state to check the current state of the task.
task1.stateFetch the task execution result:
Use .get() to get the task execution result.
task1.get()Expected Output:
You can use the demonstrated steps to integrate Celery into your application's workflow.
Type of Workers
Choosing the right type of workers is very essential as it has a major impact on the execution time & efficiency. This segment of the article will guide you through various types of workers available in Celery.
Types of Celery Workers:
- Solo
- Prefork
- Eventlet
- Gevent
Solo as the name suggests is an inline pool which means the tasks are not processed simultaneously. It creates only one thread and executes tasks using that thread.
Start Celery Worker with Solo Pool
celery -A tasks worker --pool=solo --loglevel=infoAn ideal choice for tasks that need to be run one by one. There are not many use cases in which you would require to give up on concurrency and use a solo pool.
Prefork pool uses Python's inbuilt multiprocessing library, it can process multiple tasks concurrently. The number of threads can be adjusted with --concurrency flag.
Start Celery Worker with Prefork Pool
celery -A tasks worker --pool=prefork --concurrency=4 --loglevel=infoAn ideal choice if your tasks are CPU-bound. A task is said to be CPU bound if it spends the majority of its time using CPU and can only go faster if the CPU were faster.
Examples of CPU Bound Tasks: file conversion, compression, search algorithms, etc.
Eventlet & Gevent pool uses coroutines (also known as green threads) for task execution instead of spawning traditional threads. It can process multiple tasks concurrently. The number of coroutines can be adjusted with --concurrency flag.
Start Celery Worker with Eventlet Pool
celery -A tasks worker --pool=eventlet --concurrency=500 --loglevel=infoStart Celery Worker with Gevent Pool
celery -A tasks worker --pool=gevent --concurrency=500 --loglevel=infoAn ideal choice for I/O Bound tasks. A task is said to be I/O bound when the main bottleneck is waiting time for I/O operations to complete. You can set the concurrency number high as this is not limited by the number of CPUs available unlike prefork.
Examples of I/O Bound Tasks: sending an email, making API requests, etc.
Note: eventlet and gevent are not part of Python's standard library, you must install them separately by running
pip install celery[eventlet]orpip install celery[gevent]
Conclusion
You can start integrating Celery into Python application with the given information, but this is not all, there is so much more that can be achieved with Celery. Most SaaS (Software as a Service) web applications use Celery as a background task processor to perform all sorts of actions.