

Introduction
Neural machine translation (NMT) is a deep learning technique that uses artificial neural networks to translate words from one language to another. This guide demonstrates the use of Tensorflow to build an attention-based sequence-to-sequence (seq2seq) model that translates user input on discord from English to Spanish on a Vultr Cloud GPU.
Model Overview
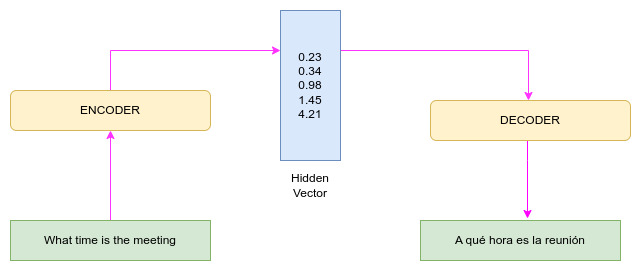
The seq2seq model comprises three blocks; encoder, hidden vector, and decoder. The encoder converts an input into a single-dimensional vector (hidden vector), while the decoder converts the hidden vector into an output sequence. For example, given the sentence What time is the meeting, the encoder converts the sentence to a vector of floating point values, each representing a word on the sentence. The decoder then converts the vector into the Spanish output sequence A qué hora es la reunión.
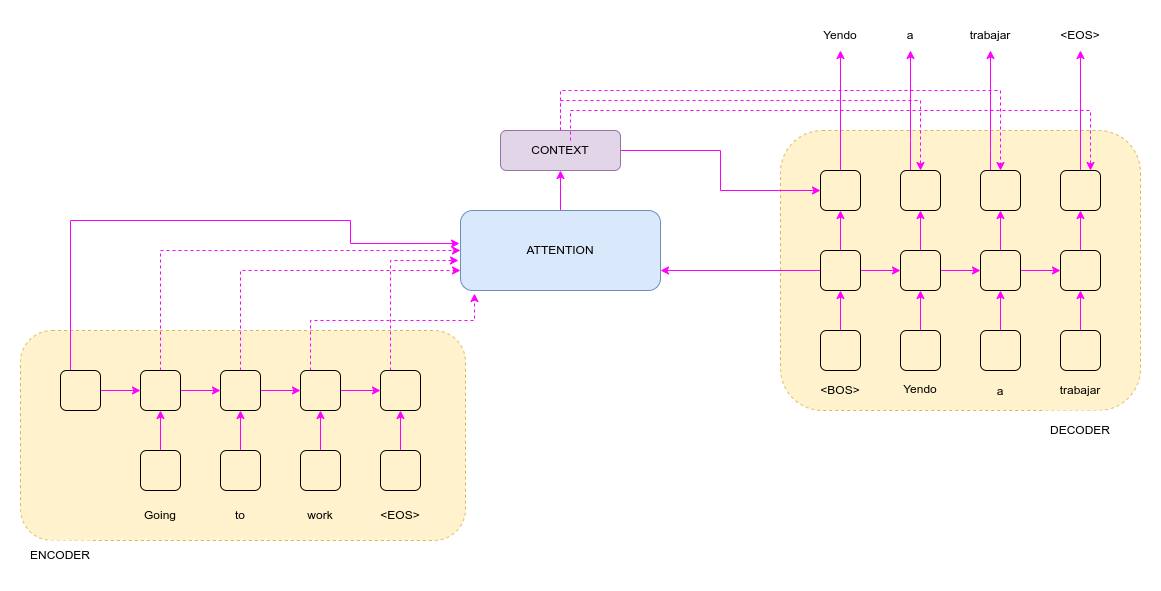
The model works well for short sentences; however, when longer inputs are provided, the model underperforms. The performance drop comes from compressing longer inputs into a fixed vector. To tackle this challenge, the attention mechanism is used. Attention allows the model to focus on the most important parts of the input sequence. The encoder takes in one word at a time until the end of the sentence (<EOS>) and outputs a hidden sentence representation. The decoder produces the target sentence starting from the beginning of the sentence (<BOS>). The decoder has access to the source sentence through the context generated by the attention mechanism. The decoder uses the most relevant words to predict the next word. At all times, the decoder has access to the input sequence.
Prerequisites
- Create a discord account..
- Deploy a Vultr Cloud GPU running on Ubuntu 22.04.
- Update the Ubuntu Server.
- Create a non-root user with sudo access and log in with SSH.
Environment Setup
SSH to the Ubuntu Cloud GPU server as the non-root user.
Create the project folder and navigate to it.
$ mkdir discordTF && cd discordTFInstall virtualenv.
$ sudo apt install virtualenvCreate a virtual environment named env.
$ python3 -m virtualenv envActivate the virtual environment.
$ source env/bin/activateCreate
requirements.txtwith nano.$ nano requirements.txtPaste the following dependencies, then save and exit the file.
tensorflow==2.11.0 tensorflow-text==2.11.0 einops==0.6.0 requests==2.23.0 numpy==1.21.6Install the dependencies.
$ pip install -r requirements.txt
Data Preprocessing
Anki provides bilingual datasets in pairs. This guide uses the English and Spanish pairs. The pairs are in the form:
Be brave. Sé fuerte. CC-BY 2.0 (France) Attribution: tatoeba.org #4054941 (CK) & #5707804 (arh)In the preprocessing step, we need to transform the data into:
Be brave. Sé fuerte.Here are the steps:
Create a data folder.
$ mkdir dataCreate the file
preprocessing.py.$ nano preprocessing.pyCopy the code below to
preprocessing.py, then save and exit the file.import requests import os from zipfile import ZipFile import numpy as np import tensorflow as tf import tensorflow_text as tf_text class PreprocessingAndStandardization: def __init__(self, url): self.url = url self.path_to_file = '' self.english_raw_data = None self.spanish_raw_data = None self.training_raw_dataset=None self.validation_raw_dataset=None self.training_processed_dataset=None self.validation_processed_dataset=None self.english_text_processor=None self.spanish_text_processor=None def download_zip(self): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} request = requests.get(self.url, stream=True, headers=headers) zip_filename = os.path.basename(self.url) with open(zip_filename, 'wb') as zfile: zfile.write(request.content) with ZipFile(zip_filename, 'r') as f: f.extractall('data') self.path_to_file='data/spa.txt' os.remove(zip_filename) def load_data(self): with open(self.path_to_file) as f: lines = f.readlines() language_pairs = [line.split('\t')[0:2] for line in lines] self.spanish_raw_data = np.array([spanish for english, spanish in language_pairs]) self.english_raw_data = np.array([english for english, spanish in language_pairs]) def create_tf_dataset(self): BUFFER_SIZE = len(self.english_raw_data) BATCH_SIZE = 64 is_train = np.random.uniform(size=(len(self.english_raw_data),)) < 0.8 self.training_raw_dataset = ( tf.data.Dataset .from_tensor_slices((self.english_raw_data[is_train], self.spanish_raw_data[is_train])) .shuffle(BUFFER_SIZE) .batch(BATCH_SIZE)) self.validation_raw_dataset =( tf.data.Dataset .from_tensor_slices((self.english_raw_data[~is_train], self.spanish_raw_data[~is_train])) .shuffle(BUFFER_SIZE) .batch(BATCH_SIZE)) def normalization_of_data(self, text_to_normalize): text_to_normalize = tf_text.normalize_utf8(text_to_normalize, 'NFKD') text_to_normalize = tf.strings.lower(text_to_normalize) text_to_normalize = tf.strings.regex_replace(text_to_normalize, '[^ a-z.?!,¿]', '') text_to_normalize = tf.strings.regex_replace(text_to_normalize, '[.?!¡,¿]', r' \0 ') text_to_normalize = tf.strings.strip(text_to_normalize) text_to_normalize = tf.strings.join(['[MWANZO]', text_to_normalize, '[MWISHO]'], separator=' ') return text_to_normalize def text_vectorization(self) : max_vocab_size = 10000 self.english_text_processor = tf.keras.layers.TextVectorization( standardize = self.normalization_of_data, max_tokens=max_vocab_size, ragged=True) self.english_text_processor.adapt(self.training_raw_dataset.map(lambda english, spanish: english)) self.spanish_text_processor = tf.keras.layers.TextVectorization( standardize= self.normalization_of_data, max_tokens=max_vocab_size, ragged=True) self.spanish_text_processor.adapt(self.training_raw_dataset.map(lambda english, spanish: spanish)) def text_preprocessing(self,english_context,spanish_target ): english_context = self.english_text_processor(english_context).to_tensor() spanish_target = self.spanish_text_processor(spanish_target) spanish_target_in = spanish_target[:,:-1].to_tensor() spanish_target_out = spanish_target[:,1:].to_tensor() return (english_context, spanish_target_in), spanish_target_out def process_dataset(self): self.training_processed_dataset=self.training_raw_dataset.map(self.text_preprocessing, tf.data.AUTOTUNE) self.validation_processed_dataset=self.validation_raw_dataset.map(self.text_preprocessing, tf.data.AUTOTUNE) def __call__(self): self.download_zip() self.load_data() self.create_tf_dataset() self.text_vectorization() self.process_dataset() return (self.english_text_processor, self.spanish_text_processor , self.training_processed_dataset, self.validation_processed_dataset)
The code breakdown is as follows:
Relevant modules are imported.
In the class, the constructor takes in a URL. The URL will be the path used to download the zip file from Anki.
The constructor initiates the following variables:
- Self.url - assigned to the URL passed on class initialization.
- Self.path_to_file - will hold the path to the downloaded dataset from Anki.
- Self.english_raw_data - Will store the extracted English phrases.
- Self.spanish_raw_data - Will store the extracted Spanish phrases.
- Self.trainingraw_dataset - will hold the raw training set.
- Self.validation_raw_dataset - will hold the raw validation set.
- Self.training_processed_dataset - will hold the processed training set.
- Self.validation_processed_dataset - will hold the processed validation set.
- Self.english_text_processor and self.spanish_text_processor - will hold the Keras text vectorization layers for English and Spanish, respectively. The vectorization layer is a preprocessing layer that maps text features to integer sequences.
The download_zip function sends a get request that downloads the zip file containing the dataset. The zip is extracted, and the contents are saved to the data folder as
spa.txt. The zip file is afterwards deleted from the system.The load_data function opens the text file containing the bilingual pairs and splits the pairs line by line. All the Spanish sentences are saved in spanish_raw_data while the English are saved in english_raw_data.
The create_tf_dataset converts the raw data into tensors. The data is divided into two; 20% for validation and 80% for training.
The normalization_of_data normalizes a text in the following order :
Converts the text into utf8 format.
Converts all characters to lowercase.
Retains select punctuations(.?!,¿), a to z, and spaces.
Adds space around punctuations.
Removes white spaces.
Adds the <SOS> and <EOS> to the phrase.
In this case, we use words that are neither Spanish nor English. [MWANZO] serves as the <SOS> while [MWISHO] serves as the <EOS>.
¿Por qué no? # <-- Original sentence [MWANZO] ¿Por que no? [MWISHO] # <-- final sentence
The text_vectorization maps text features to integer sequences of a maximum token size of 10,000. The vectorization layer has an adapt method that reads one epoch of the training data and initializes the layer based on this data to determine vocabulary. The vectorization is done for the English and Spanish training datasets.
The text_preprocessing function converts data into zero padded tensors of token IDs. Keras.Model.fit takes in (input, labels) pairs; thus, the inputs are transformed to (english_context, spanish_target_in), spanish_target_out. The english_context, spanish_target_in) being the input and spanish_target_out being the labels. The difference between the spanish_target_out and spanish_target_in is that they are shifted by one step.
The process_dataset applies the text_preprocessing function to the training and validation datasets.
[2 9 1512 10 136 883 7 137 148 4] <-- spanish\_target\_in [9 1512 10 136 883 7 137 148 4 3] <-- spanish\_target\_outThe __call__ method ties everything together and returns english_text_processor, spanish_text_processor, training_processed_dataset, and validation_processed_dataset.
Utilities
Utilities are functions used across other modules.
Create a utility file
utils.py.$ nano utils.pyCopy the following code to
utils.py, then save and exit the file.import tensorflow as tf import einops class ShapeChecker(): def __init__(self): self.shapes = {} def __call__(self, tensor, names, broadcast=False): if not tf.executing_eagerly(): return parsed = einops.parse_shape(tensor, names) for name, new_dim in parsed.items(): old_dim = self.shapes.get(name, None) if (broadcast and new_dim == 1): continue if old_dim is None: self.shapes[name] = new_dim continue if new_dim != old_dim: raise ValueError(f"Shape mismatch for dimension: '{name}'\n" f" found: {new_dim}\n" f" expected: {old_dim}\n") def masked_loss(y_true, y_pred): loss_fn = tf.keras.losses.SparseCategoricalCrossentropy( from_logits=True, reduction='none') loss = loss_fn(y_true, y_pred) mask = tf.cast(y_true != 0, loss.dtype) loss *= mask return tf.reduce_sum(loss)/tf.reduce_sum(mask) def masked_acc(y_true, y_pred): y_pred = tf.argmax(y_pred, axis=-1) y_pred = tf.cast(y_pred, y_true.dtype) match = tf.cast(y_true == y_pred, tf.float32) mask = tf.cast(y_true != 0, tf.float32) return tf.reduce_sum(match)/tf.reduce_sum(mask)
Going over the utils code:
- The ShapeChecker class will be used to check the shape of a tensor and throw an error on occurrence of a wrongly shaped tensor.
- The masked_loss and masked_acc are metric functions used during the model's training. They calculate the loss of each item in the batch and lasks of the losses on padding.
Encoder
The encoder will process the English context sequence into English sequence vectors to be used by the decoder. A bidirectional RNN will be used during processing for the flow of information within the encoder has no restrictions.
Create the encoder file
encoder.py.$ nano encoder.pyPaste the encoder class below to
encoder.py, then save and exit the file.import tensorflow as tf from utils import ShapeChecker class Encoder(tf.keras.layers.Layer): def __init__(self, text_processor, units): super(Encoder, self).__init__() self.text_processor = text_processor self.vocab_size = text_processor.vocabulary_size() self.units = units self.embedding = tf.keras.layers.Embedding(self.vocab_size, units, mask_zero=True) self.rnn = tf.keras.layers.Bidirectional( merge_mode='sum', layer=tf.keras.layers.GRU(units, return_sequences=True, recurrent_initializer='glorot_uniform')) def __call__(self, x): shape_checker = ShapeChecker() shape_checker(x, 'batch s') x = self.embedding(x) shape_checker(x, 'batch s units') x = self.rnn(x) shape_checker(x, 'batch s units') return x #inference helper function used in translation.py def convert_input(self, texts): texts = tf.convert_to_tensor(texts) if len(texts.shape) == 0: texts = tf.convert_to_tensor(texts)[tf.newaxis] context = self.text_processor(texts).to_tensor() context = self(context) return context
The encoder class does the following:
- The constructor takes in a text_processor and units that determine the dimensionality of the output space. The vocab size is derived from the text_processor.
- Tokens are converted to vectors on the embedding layer.
- The bidirectional RNN layer sequentially processes the vectors.
- The embedding layer looks up the embedding vectors for each token on the call function.
- The GRU (Gated Recurrent Unit) processes the embedding sequence.
- Returns the processed sequence to be passed to the attention mechanism.
- The convert_input will be used during translation to process input texts into contexts.
Cross Attention
The attention layer computes vectors from the English context sequence and adds to the output of the decoder. The mechanism gives the decoder to information extracted by the encoder.
Create a file
attention.py.$ nano attention.pyCopy the code below to
attention.py, then save and exit the file.import tensorflow as tf from utils import ShapeChecker class CrossAttention(tf.keras.layers.Layer): def __init__(self, units, **kwargs): super().__init__() self.mha = tf.keras.layers.MultiHeadAttention(key_dim=units, num_heads=1, **kwargs) self.layernorm = tf.keras.layers.LayerNormalization() self.add = tf.keras.layers.Add() def __call__(self, x, context): shape_checker = ShapeChecker() shape_checker(x, 'batch t units') shape_checker(context, 'batch s units') attention_output, attention_scores = self.mha( query=x, value=context, return_attention_scores=True) shape_checker(x, 'batch t units') shape_checker(attention_scores, 'batch heads t s') attention_scores = tf.reduce_mean(attention_scores, axis=1) shape_checker(attention_scores, 'batch t s') self.last_attention_weights = attention_scores x = self.add([x, attention_output]) x = self.layernorm(x) return x
Decoder
The decoder generates the prediction for the next token at each location in the Spanish target sequence. The decoder does this by:
- Looking up embeddings for each token in the English target sequence.
- Using RNNs to process the English target sequence and keep track of currently generated tokens.
- Attending to the encoder output by use of the RNN output as the query to the attention layer.
- During each location, the decoder predicts the next token. Due to this, there is a one-way flow of information with the decoder. Therefore, a unidirectional RNN is used to process the English target sequences.
Create the file
decoder.py.$ nano decoder.pyCopy the code below to
decoder.py, then save and exit the file.import tensorflow as tf from utils import ShapeChecker from attention import CrossAttention class Decoder(tf.keras.layers.Layer): def __init__(self, text_processor, units): super(Decoder, self).__init__() self.text_processor = text_processor self.vocab_size = text_processor.vocabulary_size() self.word_to_id = tf.keras.layers.StringLookup( vocabulary=text_processor.get_vocabulary(), mask_token='', oov_token='[UNK]') self.id_to_word = tf.keras.layers.StringLookup( vocabulary=text_processor.get_vocabulary(), mask_token='', oov_token='[UNK]', invert=True) self.start_token = self.word_to_id('[MWANZO]') self.end_token = self.word_to_id('[MWISHO]') self.units = units self.embedding = tf.keras.layers.Embedding(self.vocab_size, units, mask_zero=True) self.rnn = tf.keras.layers.GRU(units, return_sequences=True, return_state=True, recurrent_initializer='glorot_uniform') self.attention = CrossAttention(units) self.output_layer = tf.keras.layers.Dense(self.vocab_size) def __call__(self, context, target_seq_input, state=None, return_state=False): shape_checker = ShapeChecker() shape_checker(target_seq_input, 'batch t') shape_checker(context, 'batch s units') target_seq_input = self.embedding(target_seq_input) shape_checker(target_seq_input, 'batch t units') target_seq_input, state = self.rnn(target_seq_input, initial_state=state) shape_checker(target_seq_input, 'batch t units') target_seq_input = self.attention(target_seq_input, context) self.last_attention_weights = self.attention.last_attention_weights shape_checker(target_seq_input, 'batch t units') shape_checker(self.last_attention_weights, 'batch t s') logits = self.output_layer(target_seq_input) shape_checker(logits, 'batch t target_vocab_size') if return_state: return logits, state else: return logits ## inference methods for later def get_initial_state(self, context): batch_size = tf.shape(context)[0] start_tokens = tf.fill([batch_size, 1], self.start_token) done = tf.zeros([batch_size, 1], dtype=tf.bool) embedded = self.embedding(start_tokens) return start_tokens, done, self.rnn.get_initial_state(embedded)[0] def tokens_to_text(self, tokens): words = self.id_to_word(tokens) result = tf.strings.reduce_join(words, axis=-1, separator=' ') result = tf.strings.regex_replace(result, '^ *\[MWANZO\] *', '') result = tf.strings.regex_replace(result, ' *\[MWISHO\] *$', '') return result def get_next_token(self, context, next_token, done, state, temperature = 0.0): logits, state = self( context, next_token, state = state, return_state=True) if temperature == 0.0: next_token = tf.argmax(logits, axis=-1) else: logits = logits[:, -1, :]/temperature next_token = tf.random.categorical(logits, num_samples=1) done = done | (next_token == self.end_token) next_token = tf.where(done, tf.constant(0, dtype=tf.int64), next_token) return next_token, done, state
The decoder class does the following:
- The constructor takes in a text processor and the number of units. The vocab size is derived from the text_processor.
- The word_to_id and id_to_word Keras layers are initialized and used to convert the <SOS> and <EOS> into tokens.
- The embedding layer converts token IDs to vectors.
- The unidirectional RNN keeps track of currently generated units.
- The RNN output becomes the query of the attention layer that was imported from the attention.py.
- The call method accepts four arguments; the context from the encoder's output, the English target sequence input, state, and return state.
- We look up the embeddings within the call method and then process the target sequence using an RNN. The RNN output is used as the query for attention over the context. Logit predictions for the next token are returned.
- The rest of the methods will be used during the inference phase.
Translator
Now that all the components are ready for training the model, combine them to build the model.
Create the file
translator.py.$ nano translator.pyCopy the code below to
translator.py, then save and exit the file.import numpy as np import tensorflow as tf import einops from encoder import Encoder from decoder import Decoder from utils import ShapeChecker class Translator(tf.keras.Model): def __init__(self, units, context_text_processor, target_text_processor): super().__init__() encoder = Encoder(context_text_processor, units) decoder = Decoder(target_text_processor, units) self.encoder = encoder self.decoder = decoder def translate(self, texts, *, max_length=500, temperature=tf.constant(0.0)): shape_checker = ShapeChecker() context = self.encoder.convert_input(texts) batch_size = tf.shape(context)[0] shape_checker(context, 'batch s units') next_token, done, state = self.decoder.get_initial_state(context) tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True) for t in tf.range(max_length): next_token, done, state = self.decoder.get_next_token( context, next_token, done, state, temperature) shape_checker(next_token, 'batch t1') tokens = tokens.write(t, next_token) if tf.reduce_all(done): break tokens = tokens.stack() shape_checker(tokens, 't batch t1') tokens = einops.rearrange(tokens, 't batch 1 -> batch t') shape_checker(tokens, 'batch t') text = self.decoder.tokens_to_text(tokens) shape_checker(text, 'batch') return text def __call__(self, inputs,training=False): context, x = inputs context = self.encoder(context) logits = self.decoder(context, x) return logits
The translator returns logits that are used for training the model.
Exporting the model
Create a directory for storing the saved model and within it, create a subfolder
1. We need to do this as a way to version our models. Tensorflow serving also requires the folder structure to include a numbered folder when creating a REST API to query the model. Tensorflow serving will serve the most recent model therefore the need to version models.$ mkdir models && cd modelsCreate a subfolder within the models folder.
$ mkdir englishtospanish && cd englishtospanishCreate a subfolder within the englishtospanish folder and navigate back to project directory.
$ mkdir 1Navigate to the project folder root.
$ cd .. && cd ..Create a file
index.py.$ nano index.pyPaste the code below to
index.py. It contains all the code for bringing all the different components together and exporting the model ready to be used for inference.from decoder import Decoder import tensorflow as tf from preprocessing import PreprocessingAndStandardization from utils import ShapeChecker,masked_loss,masked_acc from translator import Translator from encoder import Encoder from attention import CrossAttention UNITS=256 def run_example(url): (english_text_processor,spanish_text_processor,training_processed_dataset,validation_processed_dataset) = PreprocessingAndStandardization(url)() for (ex_context_tok, ex_tar_in), ex_tar_out in training_processed_dataset.take(1): print('+'*1000) print(ex_context_tok[0, :10].numpy()) print() print(ex_tar_in[0, :10].numpy()) print(ex_tar_out[0, :10].numpy()) # Encode the input sequence. encoder = Encoder(english_text_processor, UNITS) ex_context = encoder(ex_context_tok) print(f'Context tokens, shape (batch, s): {ex_context_tok.shape}') print(f'Encoder output, shape (batch, s, units): {ex_context.shape}') attention_layer = CrossAttention(UNITS) # Attend to the encoded tokens embed = tf.keras.layers.Embedding(spanish_text_processor.vocabulary_size(), output_dim=UNITS, mask_zero=True) ex_tar_embed = embed(ex_tar_in) result = attention_layer(ex_tar_embed, ex_context) print(f'Context sequence, shape (batch, s, units): {ex_context.shape}') print(f'Target sequence, shape (batch, t, units): {ex_tar_embed.shape}') print(f'Attention result, shape (batch, t, units): {result.shape}') print(f'Attention weights, shape (batch, t, s): {attention_layer.last_attention_weights.shape}') print('Sum ---> ',attention_layer.last_attention_weights[0].numpy().sum(axis=-1)) attention_weights = attention_layer.last_attention_weights print('afteer attention weight') decoder = Decoder(spanish_text_processor, UNITS) model = Translator(UNITS, english_text_processor, spanish_text_processor) model.compile(optimizer='adam', loss=masked_loss, metrics=[masked_acc, masked_loss]) vocab_size = 1.0 * spanish_text_processor.vocabulary_size() {"expected_loss": tf.math.log(vocab_size).numpy(), "expected_acc": 1/vocab_size} model.evaluate(validation_processed_dataset, steps=20, return_dict=True) model.fit(training_processed_dataset.repeat(), epochs=50, steps_per_epoch = 100, validation_data=validation_processed_dataset, validation_steps = 50, callbacks=[ tf.keras.callbacks.EarlyStopping(patience=3)]) inputs = [ "Its really cold here.",# 'Hace mucho frio aqui.', "This is my life." , # 'Esta es mi vida.', "His room is a mess.", #'Su cuarto es un desastre.' # ] for t in inputs: print(model.translate([t])[0].numpy().decode()) print() result = model.translate(inputs) print(result[0].numpy().decode()) print(result[1].numpy().decode()) print(result[2].numpy().decode()) print() return model url = 'http://www.manythings.org/anki/spa-eng.zip' model = run_example(url) print('0'*100) class Export(tf.Module): def __init__(self, model): self.model = model @tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])]) def translate(self, inputs): return self.model.translate(inputs) export = Export(model) tf.saved_model.save(export, 'models/englishtospanish/1', signatures={'serving_default': export.translate})Run the
index.pyfile.$ python3 index.pyThe output should be:
Epoch 38/50 100/100 [==============================] - 90s 899ms/step - loss: 0.9116 - masked_acc: 0.7811 - masked_loss: 0.9132 - val_loss: 1.2271 - val_masked_acc: 0.7397 - val_masked_loss: 1.2285 Epoch 39/50 100/100 [==============================] - 89s 887ms/step - loss: 0.9140 - masked_acc: 0.7828 - masked_loss: 0.9150 - val_loss: 1.2303 - val_masked_acc: 0.7397 - val_masked_loss: 1.2316 aqui hace mucho frio . esta es mi vida . su habitacion es un quilombo .
Tensorflow Serving using Docker
Install Docker and run the hello world example to ensure Docker is properly installed and running.
Use Tensorflow serving to create a REST endpoint for inference.
$ docker run -t -d --rm -p 8501:8501 -v ~/discordTF/models/englishtospanish:/models/englishtospanish -e MODEL_NAME=englishtospanish tensorflow/servingTest the model is being served on port 8501 by sending a POST request using curl.
$ curl -d '{"inputs": ["This is an english sentence"]}' -X POST http://localhost:8501/v1/models/englishtospanish:predict -H Content-Type:Application/JsonThe translation will be printed on the terminal.
{ "outputs": [ "es una sentencia de ingles . " ] }
Discord
Install the Discord Python module and
python-dotenvusing pip.$ pip install discord.py python-dotenvCreate a .env file
$ nano .envOn your browser, navigate to Discord's application page.
Create a new application by clicking the New Application button and giving the application a name.
Navigate to the Bot tab, click the Add Bot button under Build-A-Bot, and click yes on the popup. Also, allow the message intent permissions under the privilege Gateway Intents Section.
Copy the token and paste it on the env with the key TOKEN. If you cannot see a token, click on the reset button.
TOKEN=paste_token_hereBack on the Discord page, on the OAuth2 Tab, click on URL generator.
Give the bot all text permissions, Manage Server, Manage Channels and Manage Events permissions.
Copy the generated URL and open it on a new tab.
Add the bot to the server you want to use it on.
On your Discord server, create two new channels; English and Spanish. By default, Discord bots listen to messages from all channels.
Create a file
app.py.$ nano app.pyAdd the code below to
app.py, then save and exit the file.import requests import json import os from dotenv import load_dotenv import discord load_dotenv() TOKEN= os.getenv("TOKEN") intents = discord.Intents.default() intents.message_content = True client = discord.Client(intents=intents) @client.event async def on_ready(): print(f'We have logged in as {client.user}') @client.event async def on_message(message): if message.author == client.user: return if message.content.startswith('$translate'): spanish_channel = discord.utils.get(client.get_all_channels(), name='spanish') message = message.content.replace('$translate ', '') data = json.dumps({"inputs": [message]}) url ="http://localhost:8501/v1/models/englishtospanish:predict" response = requests.post(url, data=data ,headers={"Content-Type":"Application/Json"}) spanish_translation = json.loads(response.text)['outputs'][0] await spanish_channel.send(spanish_translation) client.run(TOKEN)The code above establishes a connection to our discord server using the generated token. The discord bot listens to messages on all channels that start with $translate and makes an API call to the running model on Docker. The translated text is pushed to the Spanish channel.
Run the code using:
$ python3 app.pyThe output should be similar to:
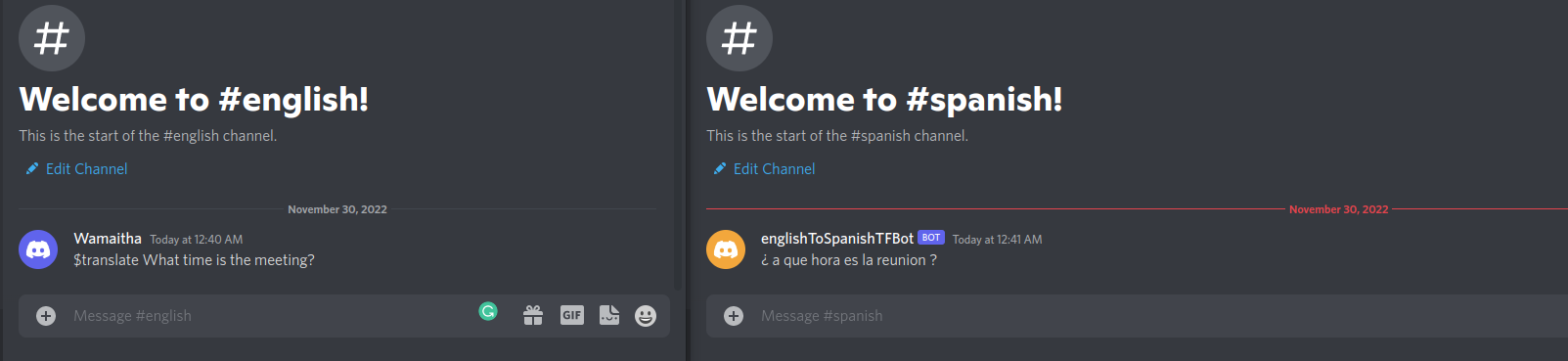
2022-12-07 04:15:08 INFO discord.client logging in using static token 2022-12-07 04:15:09 INFO discord.gateway Shard ID None has connected to Gateway (Session ID: 7915162e394cc1eab4e9fb5d5243c94d). We have logged in as englishToSpanishTFBot#8393Head to the Discord server and interact with the bot by sending an English message starting with $translate. The bot will respond with the Spanish translation on the #spanish channel.
More Resources
To learn more, please see:
No comments yet.