
How to Manage KV Cache in NVIDIA Dynamo
NVIDIA Dynamo is an open-source, high-throughput, low-latency inference framework designed to deploy large-scale generative AI and reasoning models across multi-node, multi-GPU environments. It optimizes datacenter-scale AI workloads by boosting LLM inference efficiency and reducing time-to-first-token (TTFT) through intelligent resource management, dynamic GPU allocation, and distributed orchestration.
This guide covers configuring and deploying the NVIDIA Dynamo KV Block Manager (KVBM) for efficient KV cache management across aggregated and disaggregated serving configurations. It focuses on cache tier architecture setup (GPU→CPU→Disk), environment variable configuration, and integration with vLLM and TensorRT-LLM backends to reduce KV cache recomputation, improve TTFT, and increase throughput.
Prerequisites
Before you begin, ensure you:
- Have access to a Linux server with NVIDIA GPUs installed and the NVIDIA Container Toolkit configured. Use a non-root user with sudo privileges.
- 1 GPU minimum for aggregated serving.
- 2 GPUs minimum for disaggregated serving.
- Install Docker Engine and Docker Compose.
- Create a Hugging Face account and generate an access token for gated models like Llama.
Understanding KVBM (KV Block Manager)
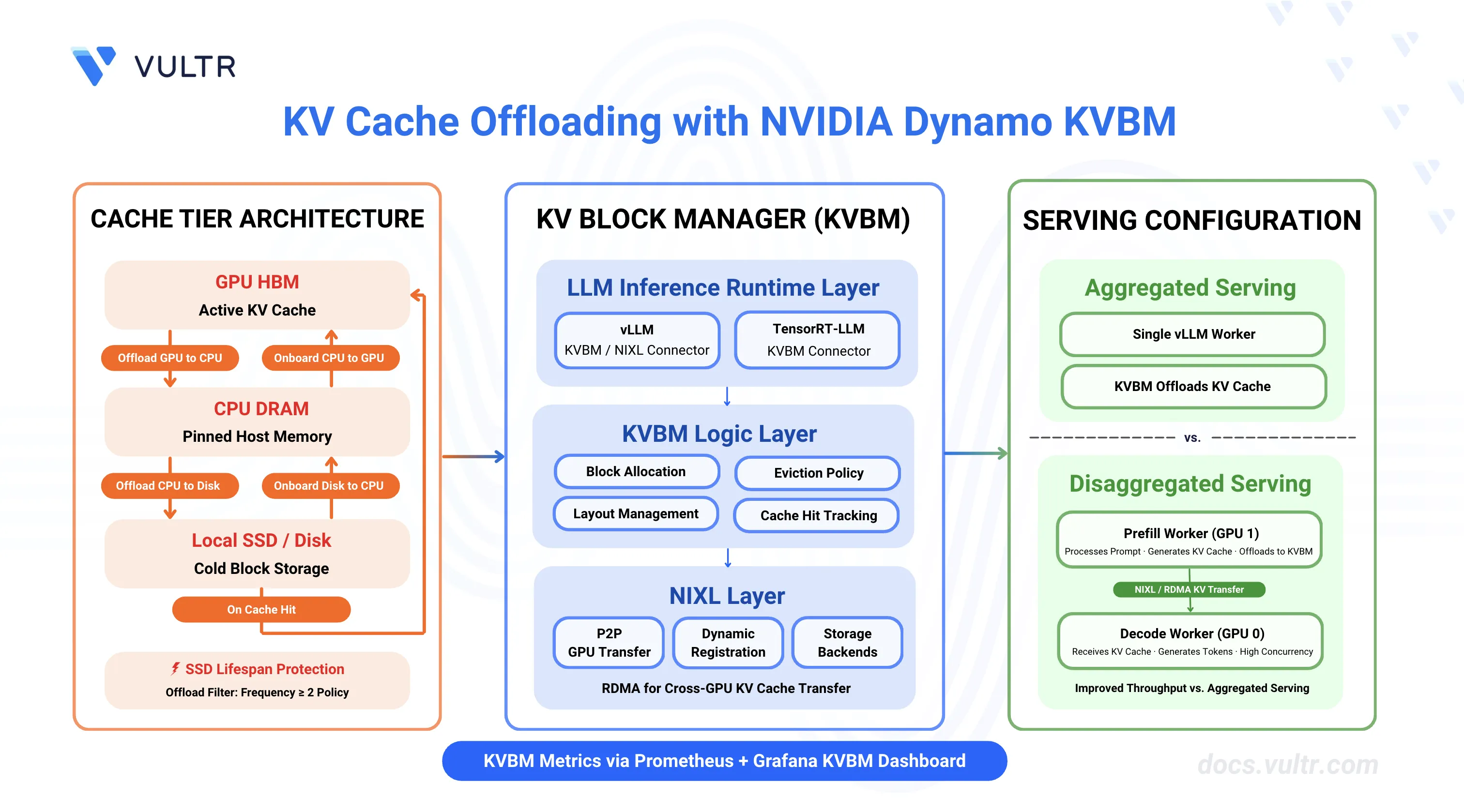
The Dynamo KV Block Manager (KVBM) is a scalable runtime component that handles memory allocation, management, and remote sharing of Key-Value (KV) blocks for inference tasks across heterogeneous and distributed environments. KVBM enables KV cache offloading from GPU memory to CPU memory and disk storage, avoiding expensive recomputation of KV cache data when GPU memory is constrained.
KVBM provides a unified memory API spanning GPU memory, pinned host memory, and local/distributed storage systems. It integrates with NIXL, a dynamic memory exchange layer for remote registration, sharing, and access of memory blocks across GPUs.
KVBM Architecture
KVBM has three primary logical layers:
LLM Inference Runtime Layer includes inference runtimes (vLLM, TensorRT-LLM) that integrate through dedicated connector modules to the Dynamo KVBM. These connectors act as translation layers, mapping runtime-specific operations and events into KVBM's block-oriented memory interface.
KVBM Logic Layer encapsulates core KV block manager logic and serves as the runtime substrate for managing block memory. This layer implements table lookups, memory allocation, block layout management, lifecycle state transitions, and block reuse/eviction policies.
NIXL Layer provides unified support for all data and storage transactions. NIXL enables P2P GPU transfers, RDMA and NVLink remote memory sharing, dynamic block registration and metadata exchange, and provides a plugin interface for storage backends including block memory (GPU HBM, Host DRAM, Local SSD).
Cache Tier Architecture
KVBM supports three cache tier configurations:
| Configuration | Data Flow | Use Case |
|---|---|---|
| GPU → CPU | Offload from GPU to pinned host memory | Fast access with CPU DRAM capacity |
| GPU → CPU → Disk | Offload from GPU to CPU, then to disk | Maximum capacity with tiered performance |
| GPU → Disk (Experimental) | Direct offload from GPU to disk | Bypass CPU tier for specific workloads |
When to Use KV Cache Offloading
KV cache offloading is most effective when cache reuse outweighs the overhead of transferring data between memory tiers. It provides significant benefits in:
| Scenario | Benefit |
|---|---|
| Long sessions and multi-turn conversations | Preserves large prompt prefixes, avoids recomputation, improves first-token latency and throughput |
| High concurrency | Idle or partial conversations move out of GPU memory, allowing active requests to proceed without hitting memory limits |
| Shared or repeated content | Reuse across users or sessions (system prompts, templates) increases cache hits, especially with remote or cross-instance sharing |
| Memory- or cost-constrained deployments | Offloading to RAM or SSD reduces GPU demand, allowing longer prompts or more users without adding hardware |
Clone the Dynamo Repository
NVIDIA Dynamo provides deployment scripts, container utilities, and orchestration modules required to run KVBM-enabled inference workloads. Clone the repository to access the deployment assets and container runtime scripts.
Clone the repository.
console$ git clone https://github.com/ai-dynamo/dynamo.git
Navigate to the repository directory.
console$ cd dynamo
Switch to the latest stable release.
console$ git checkout release/0.9.0
The command checks out the stable release. Visit the Dynamo releases page to find the latest stable release version.
Start Infrastructure Services
Dynamo's KVBM component relies on etcd for worker registry and service discovery. The Docker Compose configuration launches etcd with exposed ports for client connections (2379-2380). The etcd service must run continuously for KVBM to coordinate worker resources and manage distributed KV cache state.
Start the infrastructure services.
console$ docker compose -f deploy/docker-compose.yml up -d
Verify the services are running.
console$ docker compose -f deploy/docker-compose.yml ps
All containers should be up and running with exposed ports for etcd and NATS.
Verify CUDA Version and Pull Container Image
The vLLM container requires a CUDA version match between the host driver and container runtime to prevent GPU kernel incompatibilities. The NVIDIA Container Toolkit maps host GPUs into containers, requiring the container's CUDA version to align with the host driver's supported version.
Check the installed CUDA version.
console$ nvidia-smiThe output displays the CUDA version in the top-right corner of the table.
+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.95.05 Driver Version: 580.95.05 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ ....Pull the vLLM container image from NGC. Match the CUDA version in the image tag to your system's CUDA version.
For CUDA 13.x, use:
console$ docker pull nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13
For CUDA 12.x, use:
console$ docker pull nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
Visit the NVIDIA NGC Catalog to view all available image tags and CUDA versions.Note(Optional) Build the container from source instead of pulling the pre-built image.
console$ ./container/build.sh --framework VLLM
The build process creates an image named
dynamo:latest-vllm. If you prefer using this locally built image, replacenvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13withdynamo:latest-vllmin all subsequent commands.
Configure Hugging Face Cache Permissions
The container runs as UID 1000 and requires write access to the Hugging Face cache directory for model downloads. Incorrect permissions prevent the container from accessing cached model weights, causing worker initialization failures.
Create the cache directory if it does not exist.
console$ mkdir -p container/.cache/huggingface
Set ownership to the container user (UID 1000).
console$ sudo chown -R 1000:1000 container/.cache/huggingface
Set appropriate permissions.
console$ sudo chmod -R 775 container/.cache/huggingface
Configure Cache Tier Environment Variables
KVBM cache tiers are configured using environment variables that control the size and behavior of CPU and disk cache layers. Configure these variables before starting the Dynamo workers to enable KV cache offloading.
| Environment Variable | Description | Example Value |
|---|---|---|
DYN_KVBM_CPU_CACHE_GB |
Size of CPU cache tier in GB (pinned host memory) | 20 |
DYN_KVBM_DISK_CACHE_GB |
Size of disk cache tier in GB (local storage) | 50 |
DYN_KVBM_CPU_CACHE_OVERRIDE_NUM_BLOCKS |
Override CPU cache size with exact block count | 1000 |
DYN_KVBM_DISK_CACHE_OVERRIDE_NUM_BLOCKS |
Override disk cache size with exact block count | 2000 |
DYN_KVBM_DISABLE_DISK_OFFLOAD_FILTER |
Disable disk offload filtering for SSD lifespan protection | true |
DYN_KVBM_DISK_ZEROFILL_FALLBACK |
Enable disk zerofill fallback for filesystems without fallocate support | true |
DYN_KVBM_DISK_DISABLE_O_DIRECT |
Disable O_DIRECT flag for disk writes | true |
DYN_KVBM_LEADER_WORKER_INIT_TIMEOUT_SECS |
Timeout for KVBM leader-worker initialization | 3600 |
Cache Tier Configuration Examples
Option 1: GPU → CPU Offloading - Offload KV cache from GPU to pinned host memory (CPU). This provides fast access with CPU DRAM capacity.
export DYN_KVBM_CPU_CACHE_GB=20Option 2: GPU → CPU → Disk Tiered Offloading - Offload KV cache from GPU to CPU, then from CPU to disk. This provides maximum capacity with tiered performance.
export DYN_KVBM_CPU_CACHE_GB=20 export DYN_KVBM_DISK_CACHE_GB=50Option 3: GPU → Disk Direct Offloading (Experimental) - Offload KV cache directly from GPU to disk, bypassing the CPU tier. This is experimental and may not provide optimal performance.
export DYN_KVBM_DISK_CACHE_GB=50
SSD Lifespan Protection
When disk offloading is enabled, disk offload filtering is enabled by default to extend SSD lifespan. The current policy only offloads KV blocks from CPU to disk if the blocks have frequency ≥ 2. Frequency doubles on cache hit (initialized at 1) and decrements by 1 on each time decay step.
To disable disk offload filtering:
export DYN_KVBM_DISABLE_DISK_OFFLOAD_FILTER=trueDeploy KVBM with vLLM: Aggregated Serving
Aggregated serving with KVBM combines prefill and decode phases on a single worker while enabling KV cache offloading to CPU and disk tiers. This configuration suits single-GPU or small multi-GPU environments where KV cache reuse provides performance benefits without the complexity of disaggregated serving.
Export your Hugging Face token to avoid rate limitations when downloading large models. Replace
YOUR_HF_TOKENwith your actual token.console$ export HF_TOKEN=YOUR_HF_TOKEN
Run the vLLM container with GPU access and workspace mounting. Use the image tag that matches your CUDA version from the previous section.
console$ ./container/run.sh -it --framework VLLM --mount-workspace --image nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13 -e HF_TOKEN=$HF_TOKEN --use-nixl-gds
The command starts an interactive container session with GPU support and passes the Hugging Face token to the container. The
--use-nixl-gdsflag enables NIXL with GPU Direct Storage support for efficient KV cache offloading.Inside the container, create environment configuration for KVBM.
console$ cat << 'EOF' > ~/kvbm.env # KVBM Cache Tier Configuration export DYN_KVBM_CPU_CACHE_GB=20 # Optional: Add disk cache tier # export DYN_KVBM_DISK_CACHE_GB=50 EOF
You can use any of the Cache Tier Configuration options (GPU→CPU, GPU→CPU→Disk, or GPU→Disk) mentioned in the previous section based on your requirements.
Create a custom launch script for aggregated serving with KVBM.
console$ cat << 'EOF' > ~/kvbm_agg.sh #!/bin/bash set -e trap 'echo Cleaning up...; kill 0' EXIT # Model configuration - use command line argument or default MODEL="${1:-nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1}" # Load KVBM configuration source ~/kvbm.env echo "Starting Dynamo Frontend..." python3 -m dynamo.frontend & echo "Starting vLLM Worker with KVBM enabled" echo "Model: $MODEL" echo "CPU Cache: ${DYN_KVBM_CPU_CACHE_GB}GB" # NOTE: remove --enforce-eager for production use DYN_KVBM_CPU_CACHE_GB=${DYN_KVBM_CPU_CACHE_GB:-20} \ python3 -m dynamo.vllm \ --model "$MODEL" \ --connector kvbm \ --trust-remote-code \ --enforce-eager wait EOF
The script configures the vLLM worker with
--connector kvbm, which integrates KVBM for KV cache management. The connector enables both KV cache offloading to CPU/disk and onboarding back to GPU on the same worker.Make the script executable.
console$ chmod +x ~/kvbm_agg.sh
Run the aggregated serving script with KVBM.
console$ ~/kvbm_agg.shThe script starts a frontend service on port
8000and a vLLM worker with KVBM enabled using 20GB of CPU cache for offloading (defaults to NVIDIA Nemotron Nano 4B).Open a new terminal session on your server (outside the container).
Test with a chat completion request.
console$ curl -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1", "messages": [{"role": "user", "content": "Hello! Tell me about AI."}], "max_tokens": 100 }'
The output displays the model's chat response in JSON format.
Monitor the container logs to verify KVBM is operational. The logs display model discovery, KV event consolidator connection, and cache statistics.
INFO dynamo_llm::discovery::watcher: added model model_name="nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1" namespace="dynamo" INFO dynamo_llm::block_manager::kv_consolidator::subscriber: KV event consolidator ZMQ listener successfully connected to tcp://127.0.0.1:20080 INFO _core::block_manager::cache_stats: KVBM [worker-66967993-8d81-40b7-b42d-fe2a67ffcd70] Cache Hit Rates - Host: 0.0% (0/1), Disk: 0.0% (0/1)The logs confirm:
- Model registration with Dynamo discovery
- ZMQ listener connection for KV event consolidation
- KVBM cache statistics showing host and disk cache hit rates
KVBM is now operational and ready to offload KV cache to CPU/disk tiers, reducing prefill computation time for subsequent requests with overlapping prompts.
Deploy KVBM with vLLM: Disaggregated Serving
Disaggregated serving with KVBM enables prefill workers to offload KV cache to CPU/disk tiers and share the cache with decode workers via NIXL. This configuration maximizes throughput by allowing decode workers to receive precomputed KV cache from prefill workers while benefiting from KVBM's cache management capabilities.
Exit the container if you are still inside from the previous section. Press
Ctrl+Cto terminate the running process, then pressCtrl+Dto exit the container.Export your Hugging Face token. Replace
YOUR_HF_TOKENwith your actual token.console$ export HF_TOKEN=YOUR_HF_TOKEN
Run the container with the image tag that matches your CUDA version.
console$ ./container/run.sh -it --framework VLLM --mount-workspace --image nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13 -e HF_TOKEN=$HF_TOKEN --use-nixl-gds
The
--use-nixl-gdsflag enables NIXL with GPU Direct Storage support for efficient KV cache transfer between prefill and decode workers.Inside the container, create environment configuration for KVBM.
console$ cat << 'EOF' > ~/kvbm.env # KVBM Cache Tier Configuration export DYN_KVBM_CPU_CACHE_GB=40 # Optional: Add disk cache tier # export DYN_KVBM_DISK_CACHE_GB=50 EOF
Disaggregated serving uses 40GB of CPU cache (double the aggregated configuration) to accommodate the larger memory requirements of running separate prefill and decode workers. You can use any of the Cache Tier Configuration options (GPU→CPU, GPU→CPU→Disk, or GPU→Disk) mentioned in the previous section based on your requirements.
Create a custom launch script for disaggregated serving with KVBM.
console$ cat << 'EOF' > ~/kvbm_disagg.sh #!/bin/bash set -e trap 'echo Cleaning up...; kill 0' EXIT MODEL="${1:-nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1}" source ~/kvbm.env echo "Starting Dynamo Frontend..." python3 -m dynamo.frontend & echo "Starting Decode Worker (GPU 0)..." CUDA_VISIBLE_DEVICES=0 \ python3 -m dynamo.vllm \ --model "$MODEL" \ --tensor-parallel-size 1 \ --max-model-len 8192 \ --trust-remote-code \ --connector nixl & echo "Starting Prefill Worker with KVBM (GPU 1)..." echo "Model: $MODEL" echo "CPU Cache: ${DYN_KVBM_CPU_CACHE_GB}GB" DYN_VLLM_KV_EVENT_PORT=20081 \ VLLM_NIXL_SIDE_CHANNEL_PORT=20097 \ DYN_KVBM_CPU_CACHE_GB=${DYN_KVBM_CPU_CACHE_GB:-40} \ CUDA_VISIBLE_DEVICES=1 \ python3 -m dynamo.vllm \ --model "$MODEL" \ --tensor-parallel-size 1 \ --max-model-len 8192 \ --is-prefill-worker \ --trust-remote-code \ --connector kvbm nixl wait EOF
The script uses the
--connector kvbm nixlflag on the prefill worker, which combines KVBM for KV cache offloading and NIXL for KV cache transfer to decode workers. The decode worker uses--connector nixlto receive KV cache from the prefill worker.Make the script executable.
console$ chmod +x ~/kvbm_disagg.sh
Run the disaggregated serving script with KVBM.
console$ ~/kvbm_disagg.shThe script starts the frontend service on port
8000, a decode worker on GPU0using NIXL connector for KV cache transfer, and a prefill worker on GPU1with KVBM enabled for KV cache offloading and sharing via NIXL. KVBM cache configuration is loaded from~/kvbm.env.Open a new terminal session on your server (outside the container).
Test the disaggregated deployment.
console$ curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1", "messages": [ {"role": "system", "content": "You are a helpful AI assistant."}, {"role": "user", "content": "Explain deep learning in one sentence."} ], "max_tokens": 50 }'
Verify KVBM and disaggregated serving are operational by checking the container logs.
INFO consolidator_config.should_enable_consolidator: KV Event Consolidator auto-enabled (KVBM connector + prefix caching detected) INFO consolidator_config.get_consolidator_endpoints: Consolidator endpoints: vllm=tcp://127.0.0.1:20081, output_bind=tcp://0.0.0.0:57001, output_connect=tcp://127.0.0.1:57001 (derived from KVBM port 56001) ... INFO nixl_connector._nixl_handshake: NIXL compatibility check passed (hash: cae818f9461cb277c305be4b8cd4aca3273e21a6ea98f7399d1a339560e1b3ea) INFO _core::block_manager::cache_stats: KVBM [worker-89bfdd19-ae6e-4857-92ab-8d7155d7ac8e] Cache Hit Rates - Host: 0.0% (0/1), Disk: 0.0% (0/1)The logs confirm that KVBM is operational with KV Event Consolidator enabled, NIXL compatibility verified, and cache statistics being tracked. The prefill worker processes the prompt and offloads KV cache to KVBM. The decode worker receives the KV cache via NIXL and generates tokens.
Enable KVBM Metrics and Monitoring
KVBM provides detailed metrics about cache offloading, onboarding, and hit rates. Enable metrics collection and visualize them in Grafana to monitor KVBM performance.
Deploy the Monitoring Stack
Follow the How to Enable Observability in NVIDIA Dynamo Inference Pipelines guide to deploy the monitoring stack (Prometheus, Grafana, Tempo, DCGM Exporter).
Enable KVBM Metrics
To enable KVBM metrics, add the following environment variables to your ~/kvbm.env configuration file:
# KVBM Cache Tier Configuration
export DYN_KVBM_CPU_CACHE_GB=20
# Enable KVBM Metrics
export DYN_KVBM_METRICS=true
After updating the configuration, restart your KVBM deployment (aggregated or disaggregated) using the launch scripts. The KVBM metrics will be exported to Prometheus and can be visualized in the Grafana KVBM Dashboard.
View KVBM Metrics in Grafana
Access Grafana at http://localhost:3000 and navigate to the KVBM Dashboard to view metrics including:
- Matched Tokens: Number of tokens matched from KV cache.
- Offload Blocks D2H: KV blocks offloaded from Device (GPU) to Host (CPU).
- Offload Blocks H2D: KV blocks offloaded from Host (CPU) to Disk.
- Onboard Blocks H2D: KV blocks onboarded from Host (CPU) to Device (GPU).
- Host Cache Hit Rate: Percentage of KV cache hits in CPU memory (0.0-1.0).
- Disk Cache Hit Rate: Percentage of KV cache hits in disk storage (0.0-1.0).
High cache hit rates and onboard block counts indicate effective KV cache reuse, which translates to reduced prefill computation and improved TTFT.
Conclusion
You have successfully configured and deployed KVBM for KV cache management in NVIDIA Dynamo. The aggregated serving configuration enables KV cache offloading on a single worker, while the disaggregated serving configuration combines KVBM with NIXL for efficient cache sharing between prefill and decode workers. KVBM's tiered cache architecture (GPU→CPU→Disk) reduces KV cache recomputation, improves TTFT, and increases throughput for workloads with cache reuse patterns. For more advanced configurations, including LMCache integration, FlexKV, and SGLang HiCache, refer to the official NVIDIA Dynamo KVBM documentation.