
Introduction
PostgreSQL database performance is a key factor that is directly affected when querying data from large tables. To reduce memory swaps and table scans, PostgreSQL partitions allow you to split data into smaller manageable tables to speed up queries. This architecture improves your database reliability and overall performance.
Partitions store a specific group of data depending on the criteria specified when creating the database schema. Mainly, PostgreSQL allows you to partition data based on the date range, lists, or a hash derived from a mathematical formula. This article explains the different types of PostgreSQL partitions, their advantages, and how to implement them on a Vultr Managed Database for PostgreSQL.
Prerequisites
- Deploy a Vultr Managed Database for PostgreSQL
- Deploy a Linux Server on Vultr to use as the management machine
- Using SSH, access the server
- Create a non-root Sudo user and switch to the account
- Update the server
Create a Sample Database
Install the PostgreSQL client tool
psqlOn Ubuntu/Debian Systems:
$ sudo apt install -y postgresql-clientCentOS and RHEL-based Systems:
$ sudo yum install postgresqlFedora Linux:
$ sudo dnf install postgresql
Using
psql, log in to your Vultr Managed Database for PostgreSQL. Replacesample-host.vultrdb.com,16761,vultradminwith you actual database details$ psql -h sample-host.vultrdb.com -p 16751 -U vultradmin defaultdbCreate a new sample database
company_dbdefaultdb=> CREATE DATABASE company_db;Switch to the database
postgres=# \c company_db;Output:
You are now connected to database "company_db" as user "vultradmin". company_db=>
PostgreSQL Partitions and Benefits
In PostgreSQL, partitions split data into smaller manageable tables using user-specified conditions. These table partitions offer the following benefits when implemented:
- Improved query performance: You can generate date-based or column-based reports from a dataset by only querying a specific partition. The query runs faster because it doesn't scan the entire base table
- Improved data availability: Partition-based queries narrow a search to a specific partition. This approach allows PostgreSQL to cache frequently used parts of a partition into the system RAM. The cached data reduces disk I/O and improves access performance
- Improved database manageability: Partitions queries allow you to
dropan entire table partition to remove data instead of filtering data in the main table and running a delete command. This approach is faster and more accurate.
Below is the basic syntax for writing a PostgreSQL partition when defining a table:
postgres=# CREATE TABLE SAMPLE_TABLE_NAME (
COLUMN_LIST
)
PARTITION BY PARTITION_TYPE (PARTITION_COLUMN)Implement PostgreSQL Partitions
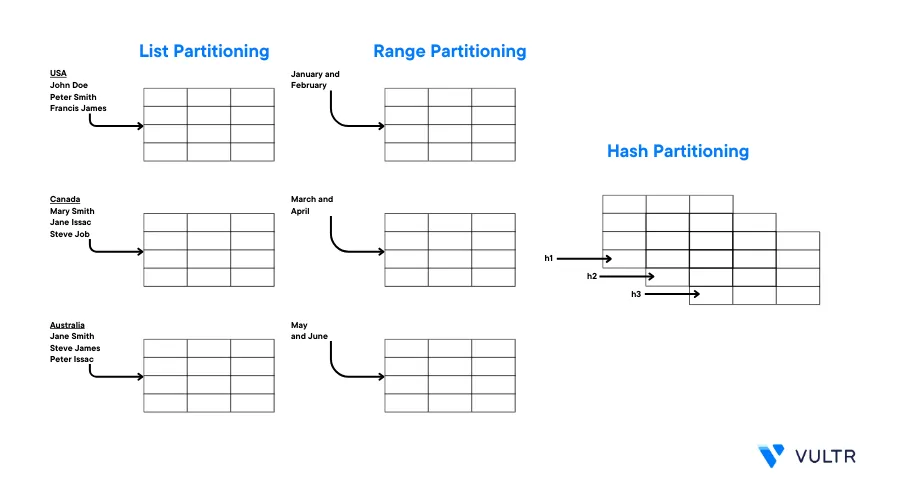
Depending on database grouping and storage structure, PostgreSQL supports the following partition methods:
- List partitions
- Range partitions
- Hash partitions
Implement each of these table partitions as described in the following sections.
List Partitions
List partitions allow you to partition data based on discrete values such as departments, order status, or regions. In this type of partition, PostgreSQL examines the data in each partition field before routing the data to a specific table. Implement a list partition as described in the following example.
Create a new
customerstable with four columns. Then, instruct the PostgreSQL server to partition the table using thecountrycolumn by including thePARTITION BY LIST (country)statement at the end of the SQL queryCREATE TABLE customers ( customer_id SERIAL, first_name VARCHAR(50), last_name VARCHAR(50), country VARCHAR(50), CONSTRAINT customers_pkey PRIMARY KEY (customer_id, country) ) PARTITION BY LIST (country);Output:
CREATE TABLECreate two different partitions. The
usa_customerspartition stores all customers from theUSAwhile thecanada_customerspartition stores all customers fromCANADAcompany_db=> CREATE TABLE usa_customers PARTITION OF customers FOR VALUES IN ('USA'); CREATE TABLE canada_customers PARTITION OF customers FOR VALUES IN ('CANADA');Output:
... CREATE TABLEInsert sample data into the
customerstable. PostgreSQL should route data to the appropriate partitionscompany_db=> INSERT INTO customers (first_name, last_name, country) VALUES ('JOHN', 'DOE', 'USA'); INSERT INTO customers (first_name, last_name, country) VALUES ('MARY', 'SMITH', 'CANADA'); INSERT INTO customers (first_name, last_name, country) VALUES ('PETER', 'SMITH', 'USA'); INSERT INTO customers (first_name, last_name, country) VALUES ('JANE', 'ISAAC', 'CANADA'); INSERT INTO customers (first_name, last_name, country) VALUES ('STEVE', 'JOB', 'CANADA'); INSERT INTO customers (first_name, last_name, country) VALUES ('FRANCIS', 'JAMES', 'USA'); INSERT INTO customers (first_name, last_name, country) VALUES ('ANN', 'HENRY', 'CANADA');Output:
... INSERT 0 1Query the different table partitions to verify that the data is partitioned correctly:
The
usa_customerspartition:company_db=> SELECT * FROM usa_customers;Output:
customer_id | first_name | last_name | country -------------+------------+-----------+--------- 1 | JOHN | DOE | USA 3 | PETER | SMITH | USA 6 | FRANCIS | JAMES | USA (3 rows)The
canada_customerspartition:company_db=> SELECT * FROM canada_customers;Output:
customer_id | first_name | last_name | country -------------+------------+-----------+--------- 2 | MARY | SMITH | CANADA 4 | JANE | ISAAC | CANADA 5 | STEVE | JOB | CANADA 7 | ANN | HENRY | CANADA (4 rows)
Range Partitions
A range partition sub-divides data based on a period. Range partitions are useful in time-series datasets. For example, in a point-of-sale application, you can partition data using the sales_date column. Likewise, in a school registration database, you can partition student records using the admission_date column. Implement Range partitions as described in the following example.
Create a new
sales_orderstable. Set thePARTITION BY RANGE ()value tosales_dateto partition data using thesales_datecolumncompany_db=> CREATE TABLE sales_orders ( sales_id SERIAL, sales_date TIMESTAMP, amount DECIMAL(17,2), CONSTRAINT sales_orders_pkey PRIMARY KEY (sales_id, sales_date) ) PARTITION BY RANGE (sales_date);Create four partitions to handle quarterly sales data for the year 2023. In each partition, specify the date boundaries
company_db=> CREATE TABLE so_q1_2023 PARTITION OF sales_orders FOR VALUES FROM ('2023-01-01') TO ('2023-04-01'); CREATE TABLE so_q2_2023 PARTITION OF sales_orders FOR VALUES FROM ('2023-04-01') TO ('2023-07-01'); CREATE TABLE so_q3_2023 PARTITION OF sales_orders FOR VALUES FROM ('2023-07-01') TO ('2023-10-01'); CREATE TABLE so_q4_2023 PARTITION OF sales_orders FOR VALUES FROM ('2023-10-01') TO ('2024-01-01');Output:
... CREATE TABLEInsert sample data to the base
sales_orderstablecompany_db=> INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-01-01', 500); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-03-15', 1200); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-04-01', 3600); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-06-30', 800); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-09-15', 2400); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-10-01', 8700); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-11-11', 2780); INSERT INTO sales_orders (sales_date, amount) VALUES ('2023-12-31', 3650);Output:
... INSERT 0 1Query data on each partition to verify that PostgreSQL segments the data as expected:
The
so_q1_2023partition:company_db=> SELECT * FROM so_q1_2023;Output:
sales_id | sales_date | amount ----------+---------------------+--------- 1 | 2023-01-01 00:00:00 | 500.00 2 | 2023-03-15 00:00:00 | 1200.00 (2 rows)The
so_q2_2023partition:company_db=> SELECT * FROM so_q2_2023;Output:
sales_id | sales_date | amount ----------+---------------------+--------- 3 | 2023-04-01 00:00:00 | 3600.00 4 | 2023-06-30 00:00:00 | 800.00 (2 rows)The
so_q3_2023partition:company_db=> SELECT * FROM so_q3_2023;Output:
sales_id | sales_date | amount ----------+---------------------+--------- 5 | 2023-09-15 00:00:00 | 2400.00 (1 row)The
so_q4_2023partition:company_db=> SELECT * FROM so_q4_2023;Output:
sales_id | sales_date | amount ----------+---------------------+--------- 6 | 2023-10-01 00:00:00 | 8700.00 7 | 2023-11-11 00:00:00 | 2780.00 8 | 2023-12-31 00:00:00 | 3650.00 (3 rows)
Hash Partitions
In PostgreSQL hash partitions, data is partitioned using a mathematical formula. This partitioning method is ideal for scenarios where there is no obvious way to partition records using dates or discrete values. The hash algorithm distributes data to child tables to avoid overloading the base table. A hash partition requires a modulus and a remainder. These two values specify where PostgreSQL saves the data in each partition as implemented in the following example.
Create a new
employeestable. Include thePARTITION BY hash( )statement withemployee_idas the value to partition the table by a hash of theemployee_idcolumncompany_db=> CREATE TABLE employees ( employee_id SERIAL NOT NULL, first_name varchar(50), last_name varchar(50) ) PARTITION BY hash(employee_id);Output:
CREATE TABLECreate three partitions on the
employeestablecompany_db=> CREATE TABLE emp_p1 PARTITION OF employees FOR VALUES WITH (MODULUS 3, REMAINDER 0); CREATE TABLE emp_p2 PARTITION OF employees FOR VALUES WITH (MODULUS 3, REMAINDER 1); CREATE TABLE emp_p3 PARTITION OF employees FOR VALUES WITH (MODULUS 3, REMAINDER 2);Output:
... CREATE TABLEInsert sample data into the
employeestablecompany_db=> INSERT INTO employees (first_name, last_name) VALUES ('JOHN', 'DOE'); INSERT INTO employees (first_name, last_name) VALUES ('MARY', 'SMITH'); INSERT INTO employees (first_name, last_name) VALUES ('JANE', 'ERIC'); INSERT INTO employees (first_name, last_name) VALUES ('PETER', 'JOB'); INSERT INTO employees (first_name, last_name) VALUES ('RACHEAL', 'FRANCIS'); INSERT INTO employees (first_name, last_name) VALUES ('STEVE', 'ISAAC');Output:
... INSERT 0 1Query the partition tables:
emp_p1partition:company_db=> SELECT * FROM emp_p1;Output:
employee_id | first_name | last_name -------------+------------+----------- 2 | MARY | SMITH 4 | PETER | JOB 6 | STEVE | ISAAC (3 rows)emp_p2partition:company_db=> SELECT * FROM emp_p2;Output:
employee_id | first_name | last_name -------------+------------+----------- 3 | JANE | ERIC (1 row)The
emp_p3partition:company_db=> SELECT * FROM emp_p3;Output.
employee_id | first_name | last_name -------------+------------+----------- 1 | JOHN | DOE 5 | RACHEAL | FRANCIS (2 rows)
Conclusion
In this guide, you implemented three different types of PostgreSQL partitions. Depending on your database size, partition your large database tables into manageable units to query data faster, reduce disk I/O, and improve data manageability. Usually, a complex application may require advanced partitioning models other than the ones discussed in this guide. In such a case, consider using the PostgreSQL table inheritance model or the UNION clause to join multiple tables to run queries.
Next Steps
To implement more PostgreSQL operations, visit the following resources:
No comments yet.