NVIDIA Dynamo
Updated on 13 March, 2026NVIDIA Dynamo is an open-source inference framework that adds disaggregated serving, intelligent routing, and tiered KV caching on top of vLLM. Version 0.9.1 supports single-node deployment with in-memory service discovery (--store-kv mem): no external infrastructure (etcd, NATS) required.
Why Dynamo?
Standard vLLM uses all GPUs for both prefill (processing the input prompt) and decode (generating output tokens). These phases have different computational profiles:
- Prefill is compute-bound: process all input tokens at once through the model
- Decode is memory-bandwidth-bound: generate one token at a time, reading KV cache
Dynamo separates these phases onto different GPU pools, allowing each to be independently optimized.
Architecture
Dynamo organizes communication into four planes:
| Plane | Purpose | Single-Node NVIDIA HGX B200 Config |
|---|---|---|
| Discovery | Service discovery | --discovery-backend file (no etcd needed) |
| Request | TCP-based inter-component routing | Zero-copy TCP decoder |
| KV Event | Real-time KV cache block events | ZMQ transport (no NATS needed) |
| Data Transfer (NIXL) | GPU-to-GPU KV tensor movement | NVSwitch 5.0 / NVLink 5.0 |
--discovery-backend file for the discovery plane. KV events use ZMQ by default.
Core Features
Disaggregated Prefill/Decode
Split 8 GPUs into separate pools:
GPUs 0-3: Prefill workers (compute-bound phase)
GPUs 4-7: Decode workers (memory-bound phase)The prefill pool processes input prompts and transfers the generated KV cache to the decode pool via NIXL over NVSwitch 5.0 (1.8 TB/s bidirectional). The decode pool generates output tokens from the transferred KV state.
This separation benefits workloads with high input-to-output token ratios (e.g., RAG, summarization) where prefill is the bottleneck.
KV-Aware Router
Dynamo's router maintains a radix tree of cached KV blocks across all workers. When a new request arrives, the router hashes the prompt prefix and routes to the worker with the highest KV cache overlap, reducing redundant prefill computation.
Two modes:
- Exact mode (default): Workers publish real-time KV cache events via ZMQ. Router maintains a live radix tree mirror.
- Approximate mode (
--no-kv-events): Router infers cache state from its own routing history via TTL expiration. No event bus needed.
# KV-aware routing
--router-mode kv
# Or simpler modes
--router-mode round-robin
--router-mode randomKV Block Manager (Tiered Cache)
Multi-tier caching hierarchy:
- GPU HBM: Primary (179 GB per NVIDIA HGX B200 GPU)
- CPU DRAM: Host memory offload
- Local NVMe SSD: Persistent cache
- Remote storage: NFS, S3-compatible
Tiered caching extends effective capacity beyond the NVIDIA HGX B200's 179 GB GPU VRAM.
NIXL (Transfer Library)
NIXL is NVIDIA's unified transfer library, not just UCX. It wraps multiple transports under a single API:
- NVLink 5.0 / NVSwitch 5.0 (intra-node)
- InfiniBand
- RoCE
- GPUDirect Storage (GDS)
- UCX
On the NVIDIA HGX B200, intra-node KV transfers use NVSwitch 5.0 at 1.8 TB/s bidirectional.
Planner
SLA-driven GPU scheduling that takes TTFT and ITL targets as inputs. Uses time-series forecasting (ARIMA, Prophet, Kalman filter) to predict load and dynamically:
- Switch between aggregated and disaggregated modes
- Shift GPUs between prefill and decode pools
- Scale workers up/down
Setup (Single-Node NVIDIA HGX B200)
# Create a dedicated Dynamo venv (do NOT install in your main vLLM env)
$ python3 -m venv ~/dynamo-venv
$ source ~/dynamo-venv/bin/activate
# Install Dynamo with vLLM backend
$ pip install "ai-dynamo[vllm]==0.9.1"
# Override vLLM to 0.16.0 for NVIDIA HGX B200 support
$ pip install vllm==0.16.0
# Set environment (same as vanilla vLLM)
$ export PATH="/usr/local/cuda/bin:$PATH"
$ NVIDIA_LIB_DIR="~/dynamo-venv/lib/python3.12/site-packages/nvidia"
$ export LD_LIBRARY_PATH="$(find $NVIDIA_LIB_DIR -name 'lib' -type d | tr '\n' ':')$LD_LIBRARY_PATH"
# Start backend worker (aggregated mode)
$ python3 -m dynamo.vllm \
--model nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code \
--store-kv mem \
--request-plane http \
--event-plane zmq \
--connector none \
--no-enable-prefix-caching \
--no-enable-flashinfer-autotune
--no-enable-flashinfer-autotune flag is required on NVIDIA HGX B200 to avoid a segfault in FlashInfer's sm_100 autotuner. This uses pre-compiled cubin kernels instead.
Observability
Dynamo includes a built-in observability stack:
- Prometheus metrics:
dynamo_-prefixed metrics for all components - Grafana dashboards: Pre-built dashboards included in the repo
- DCGM: GPU hardware metrics (utilization, power, memory bandwidth)
- Distributed tracing: Full request path tracing via Grafana Tempo
# Optional: start the observability stack (compose file from the Dynamo repo)
# See: https://github.com/ai-dynamo/dynamo/tree/main/deploy/observability
$ docker compose -f deploy/docker-compose.observability.yml up -d
Status on This Node
Dynamo was successfully started on NVIDIA HGX B200 with vLLM 0.16.0, but requires specific workarounds. Here is what we found:
Installation
The PyPI release (ai-dynamo==0.9.1) pins vLLM to 0.14.1, which does not work on NVIDIA HGX B200: the FlashInfer autotuner segfaults during initialization. However, manually upgrading vLLM to 0.16.0 within the Dynamo venv works:
# Create a dedicated venv
$ python3 -m venv ~/dynamo-venv
$ source ~/dynamo-venv/bin/activate
# Install Dynamo 0.9.1 (installs vLLM 0.14.1)
$ pip install "ai-dynamo[vllm]==0.9.1"
# Upgrade vLLM to 0.16.0 (required for NVIDIA HGX B200/Blackwell)
$ pip install vllm==0.16.0
main branch on GitHub already pins vllm==0.16.0 in its pyproject.toml. A future PyPI release (likely 1.0.0) will include this fix natively.
Running the Backend
$ export PATH="/usr/local/cuda/bin:$PATH"
$ NVIDIA_LIB_DIR="~/dynamo-venv/lib/python3.12/site-packages/nvidia"
$ export LD_LIBRARY_PATH="$(find $NVIDIA_LIB_DIR -name 'lib' -type d | tr '\n' ':')$LD_LIBRARY_PATH"
$ python3 -m dynamo.vllm \
--model nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code \
--store-kv mem \
--request-plane http \
--event-plane zmq \
--connector none \
--no-enable-prefix-caching \
--no-enable-flashinfer-autotune
Required Workarounds
| Flag | Why |
|---|---|
--no-enable-flashinfer-autotune |
FlashInfer's sm_100 autotuner segfaults. Disabling it uses pre-compiled cubins instead. |
--connector none |
The NiXL connector disables hybrid KV cache, which Nemotron Nano's Mamba layers require. |
--no-enable-prefix-caching |
Prefix caching triggers KV events config, which is incompatible with hybrid KV cache on Mamba models. |
--store-kv mem |
In-memory service discovery for single-node (no etcd needed). |
Limitations (Aggregated Mode)
No OpenAI-compatible API from the backend alone. The Dynamo backend (
dynamo.vllm) serves internal RPC endpoints. The OpenAI-compatible frontend (dynamo.frontend) must be deployed separately with shared service discovery (etcd or file-based).Nemotron Nano incompatible with NIXL connector. The NixlConnector disables hybrid KV cache manager, which Nemotron Nano's Mamba layers require. Use
--connector nonefor aggregated mode, or choose a standard transformer model for disaggregated mode.
Version Compatibility Matrix
| ai-dynamo | vLLM (bundled) | vLLM (override) | NVIDIA HGX B200 Status |
|---|---|---|---|
| 0.8.1 | 0.12.0 | -- | Crashes (FlashInfer) |
| 0.9.1 | 0.14.1 | -- | Crashes (FlashInfer) |
| 0.9.1 | -- | 0.16.0 | Works with workarounds |
| main (1.0.0) | 0.16.0 | -- | Expected to work (not on PyPI yet) |
Benchmark: FlashInfer Autotuner Impact
The --no-enable-flashinfer-autotune workaround uses pre-compiled cubin kernels instead of autotuned ones. We benchmarked vanilla vLLM 0.16.0 with this flag to measure the performance impact.
Test config: Nemotron Nano 30B FP8, TP=2, input=2048, output=512, random dataset.
| Concurrency | Autotuner Disabled (tok/s) | Original Autotuned (tok/s) | Difference |
|---|---|---|---|
| 1 | 278 | 277 | +0.4% |
| 32 | 4,023 | 3,798 | +5.9% |
| 64 | 7,641 | 8,120 | -5.9% |
| 128 | 11,689 | 11,556 | +1.2% |
| 256 | 16,177 | 15,552 | +4.0% |
| 512 | 19,361 | 18,746 | +3.3% |
Finding: Disabling the FlashInfer autotuner has negligible impact on throughput (<6% variance across all concurrency levels). The pre-compiled cubin kernels downloaded from NVIDIA's artifact server perform comparably to autotuned kernels on NVIDIA HGX B200. The variance is within normal run-to-run noise.
This means the --no-enable-flashinfer-autotune workaround is production-viable: you lose nothing measurable by using it.
Latency Comparison (at c=64)
| Metric | Autotuner Disabled | Original Autotuned |
|---|---|---|
| Mean TTFT (ms) | 459 | 324 |
| Mean TPOT (ms) | 7.46 | 6.74 |
| Mean ITL (ms) | 7.46 | 6.74 |
TTFT is ~40% higher without the autotuner at c=64. The autotuner primarily optimizes prefill kernels for specific batch/sequence sizes: this benefits TTFT more than throughput. For latency-sensitive workloads, investigate the FlashInfer segfault fix in future vLLM releases.
Disaggregated Prefill/Decode (Tested)
We deployed the full Dynamo disaggregated stack on NVIDIA HGX B200:
- etcd: Service discovery (Docker container, host networking)
- Prefill worker: GPU 0,
--is-prefill-worker --connector nixl - Decode worker: GPU 4,
--is-decode-worker --connector nixl - Frontend:
dynamo.frontendwith--router-mode round-robin, OpenAI-compatible API on port 9000
KV cache transfers between prefill and decode use NIXL over NVSwitch 5.0.
Setup
# 1. Start etcd (Docker)
$ sudo docker run -d --name dynamo-etcd --network host \
quay.io/coreos/etcd:v3.5.21 /usr/local/bin/etcd \
--advertise-client-urls http://127.0.0.1:2379 \
--listen-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://127.0.0.1:2380 \
--initial-advertise-peer-urls http://127.0.0.1:2380 \
--initial-cluster default=http://127.0.0.1:2380
# Common env for all processes
$ export ETCD_ENDPOINTS="http://127.0.0.1:2379"
$ export DYN_NAMESPACE="dynamo"
# 2. Prefill worker (GPU 0)
$ CUDA_VISIBLE_DEVICES=0 python3 -m dynamo.vllm \
--model <model> --tensor-parallel-size 1 \
--store-kv etcd --request-plane tcp --event-plane zmq \
--is-prefill-worker --connector nixl \
--no-enable-prefix-caching --no-enable-flashinfer-autotune
# 3. Decode worker (GPU 4, different NIXL port)
$ VLLM_NIXL_SIDE_CHANNEL_PORT=5700 \
CUDA_VISIBLE_DEVICES=4 python3 -m dynamo.vllm \
--model <model> --tensor-parallel-size 1 \
--store-kv etcd --request-plane tcp --event-plane zmq \
--is-decode-worker --connector nixl \
--no-enable-prefix-caching --no-enable-flashinfer-autotune
# 4. Frontend (no GPU needed)
$ python3 -m dynamo.frontend \
--model-name <model> --model-path /path/to/model \
--store-kv etcd --request-plane tcp --event-plane zmq \
--router-mode round-robin --http-port 9000
VLLM_NIXL_SIDE_CHANNEL_PORT to a different value for each worker.
--connector nixl requires standard KV cache: models with hybrid KV (Nemotron Nano's Mamba layers) are incompatible. Use a standard transformer model.
Benchmark: DeepSeek V3.2 685B
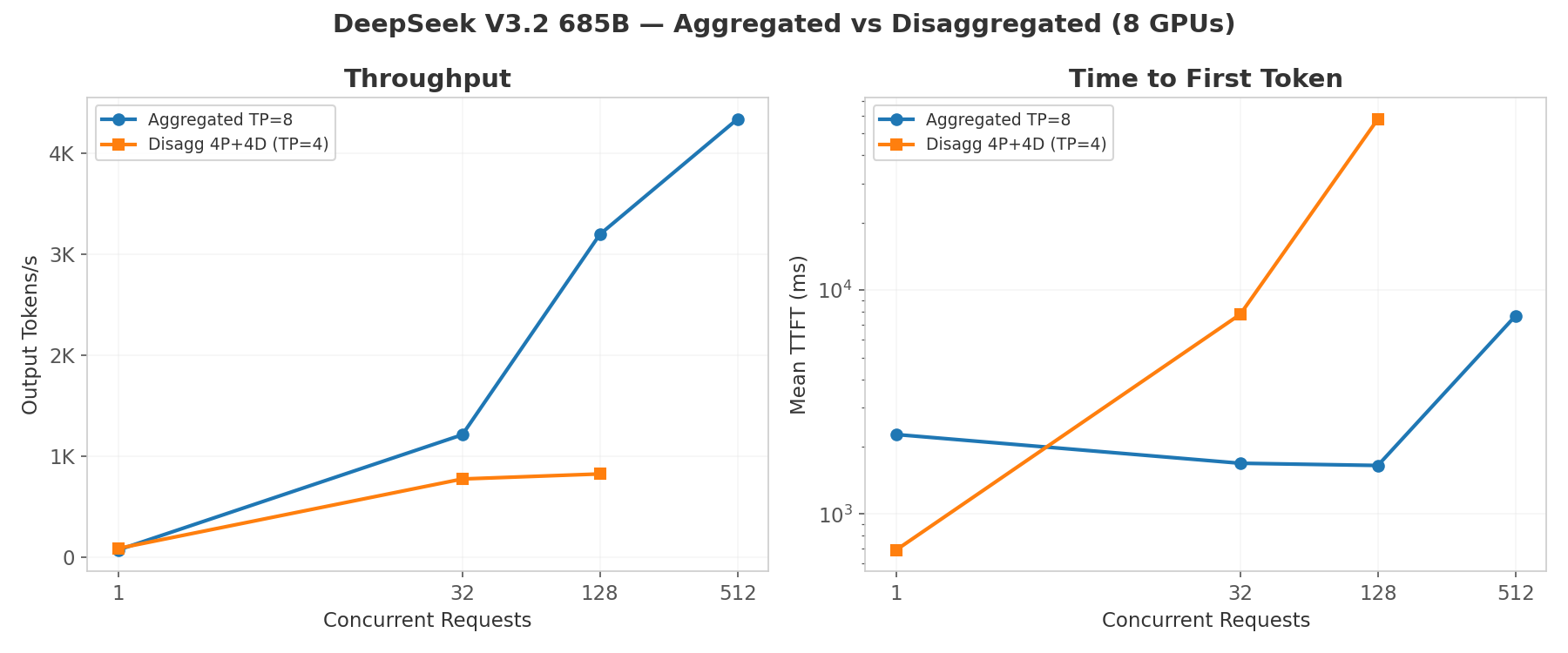
Tested with DeepSeek V3.2 (685B MoE, 37B active, MLA attention): input=2048, output=512 tokens.
- Aggregated: 8 GPUs, TP=8, max-model-len=32768, gpu-memory-utilization=0.90
- Disaggregated: 4 prefill GPUs (0-3) + 4 decode GPUs (4-7), TP=4 each, max-model-len=4096, gpu-memory-utilization=0.95
| Concurrency | Aggregated (8 GPU) tok/s | Disagg (4P+4D) tok/s | Aggregated TTFT (ms) | Disagg TTFT (ms) |
|---|---|---|---|---|
| 1 | 70 | 85 (+21%) | 2,264 | 691 |
| 32 | 1,210 | 772 (-36%) | 1,685 | 7,800 |
| 128 | 3,194 | 822 (-74%) | 1,647 | 58,094 |
| 512 | 4,335 | -- | 7,673 | -- |
Analysis
At low concurrency (c=1), disaggregated mode wins: 21% higher throughput and 3.3x better TTFT (691ms vs 2,264ms). The dedicated prefill pool processes the prompt faster when not competing with ongoing decode. This is the regime where disaggregation shines: latency-sensitive, low-batch workloads.
At high concurrency, aggregated mode scales much better (4,335 tok/s at c=512 vs 822 tok/s at c=128 for disaggregated). Two factors explain this:
Memory constraint. DeepSeek V3.2 at TP=4 consumes ~171 GB/GPU in weights, leaving almost no room for KV cache. We had to reduce
--max-model-lento 4096 (vs 32768 for aggregated TP=8). This limits batch size and throughput ceiling.Prefill GPU saturation. With only 4 prefill GPUs at TP=4 (effectively 1 prefill instance), all prefill compute hits one worker. At c=128, TTFT reaches 58s: the prefill GPU pool is completely saturated.
Benchmark: Nemotron Super 49B (bf16) Multi-Config
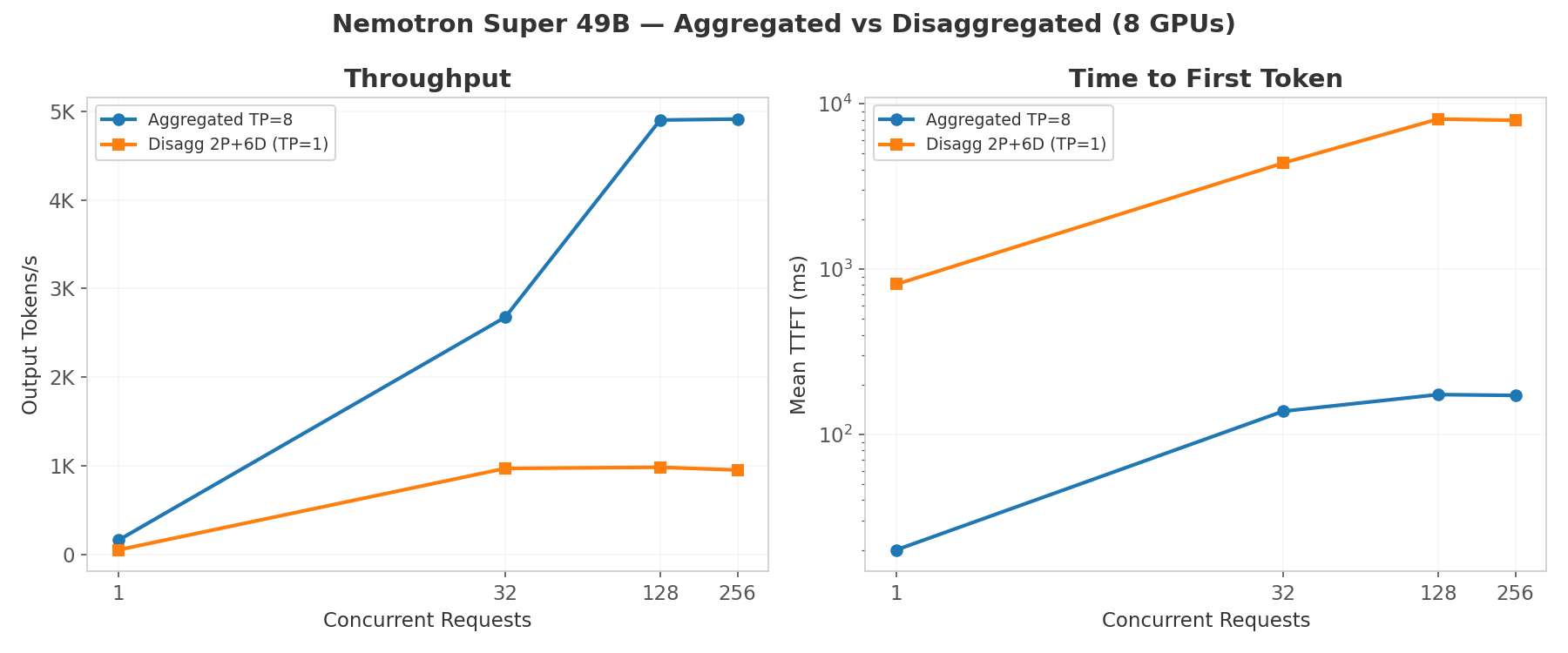
Tested with Llama-3.3-Nemotron-Super-49B-v1.5 (49B dense, standard transformer): input=2048, output=512 tokens. TP=1 per worker, all 8 GPUs used in every configuration.
Throughput (tok/s)
| Config | c=1 | c=32 | c=128 | c=256 |
|---|---|---|---|---|
| Aggregated TP=8 | 161 | 2,677 | 4,900 | 4,911 |
| Aggregated TP=1 (1 GPU) | 55 | 1,249 | 2,267 | -- |
| Disagg 2P+6D | 52 | 971 | 984 | 953 |
| Disagg 4P+4D | 50 | 791 | 813 | 807 |
| Disagg 6P+2D | 50 | 798 | 811 | 826 |
| Disagg 1P+1D | 50 | 471 | 461 | -- |
TTFT (ms)
| Config | c=1 | c=32 | c=128 | c=256 |
|---|---|---|---|---|
| Aggregated TP=8 | 20 | 138 | 174 | 172 |
| Aggregated TP=1 (1 GPU) | 42 | 167 | 222 | -- |
| Disagg 2P+6D | 809 | 4,378 | 8,075 | 7,938 |
| Disagg 4P+4D | 1,068 | 7,819 | 14,706 | 14,875 |
| Disagg 6P+2D | 1,086 | 7,172 | 13,996 | 13,771 |
| Disagg 1P+1D | 1,021 | 17,957 | 27,345 | -- |
Aggregated TP=8 outperforms all disaggregated configs: 5x higher throughput and 40x lower TTFT. The 49B model fits on 1 GPU with 80 GB spare for KV cache, so there is no prefill bottleneck to disaggregate. Every disaggregated request pays ~800ms NIXL transfer overhead that exceeds the prefill cost itself.
2P+6D is the best disaggregated config at 984 tok/s, but still 5x slower than aggregated TP=8. The extra decode workers help absorb decode-bound traffic, while prefill capacity is adequate for this model size.
TPOT is consistent (~18 ms) across all disaggregated configs, confirming decode performance is unaffected by NIXL. The bottleneck is entirely on the prefill→decode transfer path.
Query dtype mismatch: expected torch.bfloat16, got torch.float8_e4m3fn). The NIXL HND layout override is incompatible with FP8 attention in vLLM 0.16.0. Use bf16 checkpoints for disaggregated serving.
Models That Cannot Be Disaggregated
| Model | Blocker |
|---|---|
| GLM-5 744B | OOM at TP=4 (~176 GB/GPU weights > 179 GB VRAM). Requires TP=8 minimum. |
| Nemotron Nano 30B | Mamba hybrid KV cache incompatible with NIXL connector. |
| MiniMax M2.5 | vLLM 0.16.0 n_group=0 fused MoE kernel crash. |
| Nemotron Super 49B FP8 | FlashInfer FP8 attention + NIXL HND layout assertion failure. |
When Disaggregation Helps
The DeepSeek V3.2 c=1 result demonstrates the core benefit: 3.3x better TTFT (691ms vs 2,264ms) by dedicating GPU resources to prefill without decode interference.
For production deployments, disaggregation makes sense when:
- High input-to-output token ratios (RAG, summarization with 10K+ input tokens): prefill is the bottleneck
- SLA-driven workloads where TTFT matters more than throughput
- Asymmetric GPU allocation: e.g., 6 prefill + 2 decode GPUs
- Multi-node deployments where prefill and decode pools scale independently
Single-Node Limitations
On a single 8-GPU NVIDIA HGX B200 node, disaggregation is constrained by:
- 700B+ models need TP=8: no GPUs left to split into pools
- 1P+1D with small models adds overhead without benefit: NIXL transfer cost exceeds any prefill isolation gain
- FP8 models incompatible with NIXL: bf16 required, doubling memory footprint
The sweet spot for single-node disaggregation is a model that fits at TP=2 (allowing 3P+1D or 2P+2D splits) with long input sequences where prefill is genuinely compute-bound. For most single-node workloads, aggregated serving is simpler and faster.
Additional Tools
- AIPerf (github.com/ai-dynamo/aiperf): NVIDIA's benchmarking tool with dashboard UI, trace replay, and SLA-driven profiling
- AIConfigurator: Simulates optimal configurations (TP, worker count, batching) without real deployment
- Grove (github.com/NVIDIA/grove): Kubernetes topology orchestration for production multi-node deployments
For a condensed overview of all Dynamo findings, see the Executive Summary.
References
- Dynamo GitHub (v0.9.1 / main)
- Dynamo Blog: Introduction
- Dynamo Blog: v0.4 Performance