
How to Deploy Large Language Models (LLMs) with Ollama
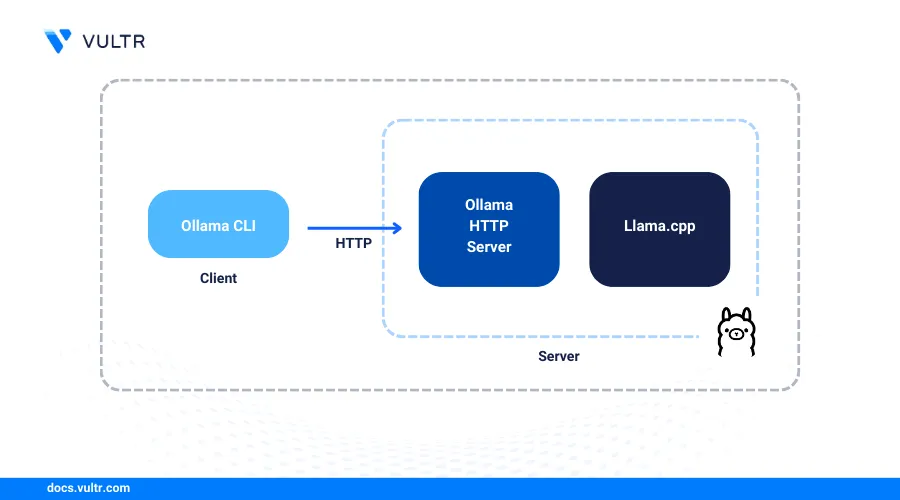
Ollama is an open-source platform for running large language models (LLMs) locally. Ollama supports most open-source Large Language models (LLMs) including Llama 3, DeepSeek R1, Mistral, Phi-4, and Gemma 2 models, you can run locally without an internet connection. It enhances security, privacy, and provides greater control over a model's performance, allowing you to customize it on your workstation.
Ollama includes a default models repository which lets you search and download LLMs to run on your workstation. It also supports OpenWebUI as a graphical web interface for running models without using the command line interface (CLI). It works on Linux, Windows, and macOS without any cloud-based APIs requirements to run models.
This article explains how to install Ollama and run large language models (LLMs) with all required dependencies on your workstation.
Download and Install Ollama
Ollama is compatible with Linux, macOS, and Windows. You can download and install Ollama using the official release package or script from the official website. Follow the steps below to download and install the latest Ollama version on your Linux, macOS, or Windows workstation.
Open a new terminal session.
Run the following command to download the
install.shOllama script and install it on your instance.console$ curl -fsSL https://ollama.com/install.sh | sh
Verify the installed Ollama version.
console$ ollama -v
Your output should be similar to the one below.
ollama version is 0.5.12List all available models.
console$ ollama list
Manage the Ollama System Service on Linux
Ollama creates an ollama.service system service by default when installed, to manage the application. Follow the steps below to test the Ollama system service and enable it to automatically start at boot.
Test the Ollama service status and verify that it's available.
console$ sudo systemctl status ollama
Output:
● ollama.service - Ollama Service Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled) Active: active (running) since Wed 2025-02-26 13:33:41 UTC; 5min ago Main PID: 27138 (ollama) Tasks: 6 (limit: 2269) Memory: 32.2M (peak: 32.7M) CPU: 63ms CGroup: /system.slice/ollama.service └─27138 /usr/local/bin/ollama serveEnable Ollama to automatically start at boot.
console$ sudo systemctl enable ollama
Restart the Ollama service.
console$ sudo systemctl restart ollama
Optional: Install AMD GPU ROCm drivers for Ollama
Download the latest Ollama archive with
rocmsupport from the official website.console$ curl -L https://ollama.com/download/ollama-linux-amd64-rocm.tgz -o ollama-linux-amd64-rocm.tgz
Extract all files from the archive to the
/usr/directory.console$ sudo tar -C /usr/ -xzf ollama-linux-amd64-rocm.tgz
Visit the official Ollama website.
Click Download and download the latest package for macOS.
Open the downloaded
.zipOllama file and extract it.Drag the
Ollama.appto the Applications folder to enable it as an application on your Mac.Open a new terminal.
Verify the installed Ollama version.
console$ ollama -v
List all available models.
console$ ollama list
Start Ollama.
console$ ollama serve
Visit the official Ollama website.
Click Download and download the latest
.exefile for Windows.Open the downloaded
.exeinstaller file.Click Install to install Ollama to the default installation path.
Monitor the installation process and verify that the Ollama is installed.
Open a new Windows PowerShell session.
Verify the installed Ollama version.
console> ollama -v
Output:
ollama version is 0.5.12List all locally available models.
console> ollama list
Start Ollama if it's not already running in your taskbar.
console> ollama serve
Download LLMs Using Ollama
Ollama downloads models using the ollama pull command that fetches the model to run on your system. You can download models from the Ollama models repository. Follow the steps below to download LLMs using Ollama to run on your workstation.
Run the Ollama with the
pulloption to download a model from the official repository.console$ ollama pull [model]
For example, download Mistral using Ollama.
console$ ollama pull mistral
Download the
Deepseek-R1-Distrill-Qwenmodel with 1.5B parameters using Ollama.console$ ollama pull deepseek-r1:1.5b
Download Llama 3.3 using Ollama.
console$ ollama pull llama3.3
The Llama 3.3 model is
40GBin size. Verify that you have enough storage space to run this model before downloading it.List all locally available models using Ollama.
console$ ollama list
Your output should be similar to the one below.
NAME ID SIZE MODIFIED llama3.3:latest a6eb4748fd29 42 GB 21 seconds ago deepseek-r1:1.5b a42b25d8c10a 1.1 GB 4 minutes ago mistral:latest f974a74358d6 4.1 GB 26 minutes ago
Use Ollama to Run Models
You can run, pull and initialize large language models directly from the Ollama repository or locally from the available models using the ollama run command. Check the required system resources for each AI model before running it using Ollama. Follow the steps below to run models using Ollama and test the performance of each model on your workstation.
List all locally available models.
console$ ollama list
Run a model directly using Ollama. For example, run the
qwen 2.5instruct model with1.5Bparameters.console$ ollama run qwen2.5:1.5b
Enter a new prompt such as
Give me two lines of text about Vultr.>>> Send a message (/? for help)Monitor the model output and results in your terminal.
>>> Give me two lines of text about Vultr Vultr is a popular cloud hosting provider known for its affordable pricing and user-friendly interface, making it an ideal choice for both small businesses and individual users looking to host websites or run servers. It offers various storage options starting at just $5/month, with plans that cater to different needs ranging from basic to advanced configurations.Enter
/byeto exit Ollama.>>> /byeRun a model that's available on your workstation. For example, run the Deepseek R1 model you downloaded earlier.
console$ ollama run deepseek-r1:1.5b
Enter a prompt such as
Generate a recursive fractal pattern description using only mathematical notations and symbolic logic.>>> Send a message (/? for help)Monitor the model output and results in your terminal.
<think> Okay, so I need to create a recursive fractal pattern using only mathematical notation and symbols. Hmm, that's an interesting challenge. Let me think about what I know about fractals and how they can be represented mathematically. ...................................Enter
/byeto exit Ollama.>>> /byeDifferent models excel at specific tasks and running them using Ollama allows you to test the performance and model capabilities. Use the
ollama runcommand to run locally available models, or pull the latest version from the Ollama models repository to run on your system.
Manage Available Models Using Ollama
Downloading multiple LLMs on your system is a complex task that requires continuous management using Ollama. Use the ollama list command to view all available and delete any versions you no longer need on your workstation. Follow the steps below to view and manage all available models using Ollama.
List all locally available models.
console$ ollama list
Show information about a specific model. For example, display the
Llama 3.3model information.console$ ollama show llama3.3
Output:
Model architecture llama parameters 70.6B context length 131072 embedding length 8192 quantization Q4_K_M Parameters stop "<|start_header_id|>" stop "<|end_header_id|>" stop "<|eot_id|>" License LLAMA 3.3 COMMUNITY LICENSE AGREEMENT Llama 3.3 Version Release Date: December 6, 2024Stop a model that's actively running using Ollama.
console$ ollama stop [model-name]
For example, stop the Deepseek R1 model.
console$ ollama stop deepseek-r1:1.5b
Remove a model from your workstation. For example, remove the
mistralmodel you pulled earlier.console$ ollama rm mistral
Output:
deleted 'mistral'List all locally available models and verify that the model is unavailable.
console$ ollama list
Set Ollama Environment Variables
Ollama variables modify the application behavior and allow you to effectively run models on your workstation. The following are the most used Ollama variables.
OLLAMA_HOST: Specifies the Ollama server address.OLLAMA_GPU_OVERHEAD: Reserve a part of VRAM per GPU in bytes.OLLAMA_MODELS: Specifies a custom directory to store the model files on your system.OLLAMA_KEEP_ALIVE: Controls how long models can stay in memory.OLLAMA_DEBUG: Enables additional debug information while running LLMs.OLLAMA_FLASH_ATTENTION: Activates experimental optimizations for attention mechanismsOLLAMA_NOHISTORY: Disables readline history while running LLMs.OLLAMA_NOPRUNE: Disables pruning of model blobs at system boot or startup.OLLAMA_ORIGINS: Configures origin URLs with access to the Ollama server.
Follow the steps below to set Ollama environment variables based on your operating system.
Set Ollama Variables on Linux
Open the Ollama system service file.
console$ sudo vim /etc/systemd/system/ollama.service
Add the
Environmentcommand after the[service]declaration and include an Ollama variable. For example, enterEnvironment="OLLAMA_DEBUG=1"to enable debugging.[Service] Environment="OLLAMA_DEBUG=1"Add another Ollama environment variable such as
OLLAMA_HOST=0.0.0.0:11434to allow other hosts to connect to the Ollama server.ini[Service] Environment="OLLAMA_DEBUG=1" Environment="OLLAMA_HOST=0.0.0.0:11434"
Save and close the file.
Setting the Ollama host address to
0.0.0.0allows other hosts to connect and access Ollama using the specified port.
Reload systemd to apply the service configuration changes.
console$ sudo systemctl daemon-reload
Restart Ollama to apply the environment variables.
console$ sudo systemctl restart ollama
Set Ollama Variables on macOS
Quit Ollama if it's running in your terminal session.
Use the
launchctlcommand to set environment variables on Mac. For example, set theOLLAMA_HOSTvariable.console$ launchctl setenv OLLAMA_HOST "0.0.0.0"
Start Ollama to apply the variable changes.
console$ ollama serve
Set Ollama Variables on Windows
Quit Ollama if it's running.
Open the Windows search menu, search for
Environment Variables, and select Edit the System Variables from the search results.Click Environment Variables in the open System Properties window.
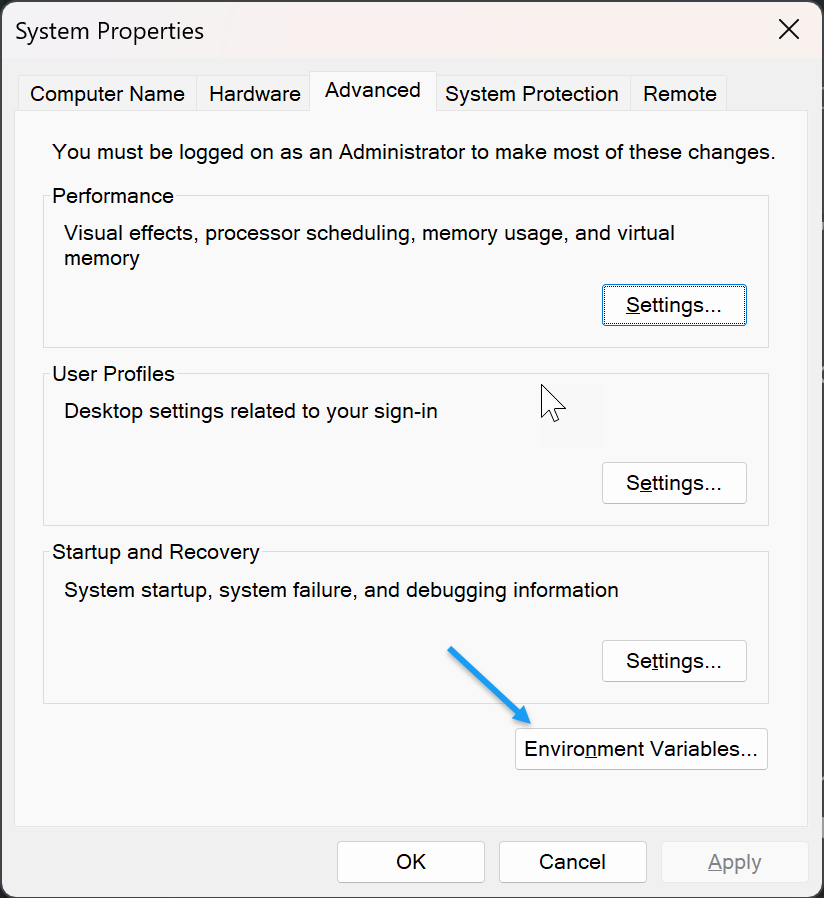
Click New to create a new variable.
Enter your Ollama variable in Variable name.
Enter a value in the Variable value.
Click OK to save the environment variable.
Click OK to close the Environment Variables prompt.
Click Apply to apply the variable changes and close the System Properties dialog.
Conclusion
You have installed Ollama and run large language models (LLMs) on your workstation. Ollama is an efficient platform for running LLMs locally or on a remote server. Use Ollama variables to create a dedicated workstation to run and access your models remotely from any device, including mobile devices. For more information and model examples, visit the Ollama GitHub repository.