
How to Run Tasks with dstack on Vultr
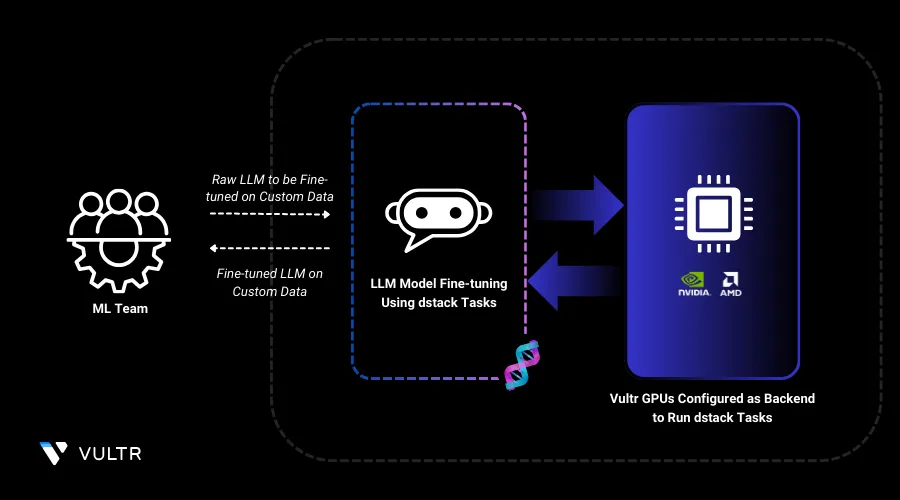
dstack runs AI and machine learning workloads efficiently. Each task defines a specific job, such as training a model or processing data, and runs in a cloud or on-premise environment. Users can define tasks using a simple configuration file, specifying resources like GPUs, dependencies, and scripts. dstack handles scheduling, execution, and resource allocation, ensuring that tasks run smoothly without manual intervention. This makes it easier for teams to manage AI workloads, scale operations, and optimize performance without dealing with complex infrastructure setups.
In this guide, you'll fine-tune the DeepSeek R1 Distill Qwen 1.5B model using dstack on Vultr Cloud GPUs. dstack automates workload management, leveraging Vultr’s high-performance GPUs for efficient training with LoRA optimization and W&B logging.
Create a Virtual Environment
In this section, you are going to create virtual environment on your machine and prepare the environment for the dstack dev environment deployment.
Install the
venvpackage.console$ apt install python3-venv -y
Create a virtual environment.
console$ python3 -m venv dstack-env
Activate the virtual environment.
console$ source dstack-env/bin/activate
Install dstack
In this section, you are going to install all the necessary dependencies for dstack and activate the dstack server for the dev environment deployment in the later section.
Create a directory and navigate into it to store the backend file.
console$ mkdir -p ~/.dstack/server
Create a backend
ymlfile to declare Vultr as the provider.console$ nano ~/.dstack/server/config.yml
Copy and paste the below configuration.
YAMLprojects: - name: main backends: - type: vultr creds: type: api_key api_key: <vultr-account-api-key>
Save and close the file.
Install dstack.
console$ pip install "dstack[all]" -U
Activate the dstack server.
console$ dstack server
Note down the URL on which the dstack server is running and token provided in the output.
Point the CLI to the dstack server.
console$ dstack config --url <URL> \ --project main \ --token <TOKEN>
Run a Fine-tuning Task
In this section, you will configure and run a training task using dstack on Vultr Cloud GPUs. You will define the task, set up environment variables, and execute the fine-tuning process for the DeepSeek-R1-Distill-Qwen-1.5B model.
Continue in the
dstack-envvirtual environment, and create a directory and navigate into it.console$ mkdir quickstart && cd quickstart
Initialize the directory.
console$ dstack init
Create a YAML file to define the dstack dev environment configuration.
console$ nano .dstack.yaml
Copy and paste the below configuration.
YAMLtype: task # The name is optional, if not specified, generated randomly name: trl-train python: "3.10" nvcc: true # Required environment variables env: - WANDB_API_KEY - WANDB_PROJECT - MODEL_ID=deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B # Commands of the task commands: - git clone https://github.com/huggingface/trl.git - pip install transformers - pip install trl - pip install peft - pip install wandb - cd trl/trl/scripts - python sft.py --model_name_or_path $MODEL_ID --dataset_name trl-lib/Capybara --learning_rate 2.0e-4 --num_train_epochs 1 --packing --per_device_train_batch_size 2 --gradient_accumulation_steps 8 --gradient_checkpointing --logging_steps 25 --eval_strategy steps --eval_steps 100 --use_peft --lora_r 32 --lora_alpha 16 --report_to wandb --output_dir DeepSeek-R1-Distill-Qwen-1.5B-SFT resources: gpu: # 24GB or more vRAM memory: 24GB..
Save and close the file.
The YAML file defines a dstack task to fine-tune
DeepSeek-R1-Distill-Qwen-1.5Busing Hugging Face’s TRL with LoRA optimization. It pulls the TRL repository, installs dependencies, and runs supervised fine-tuning ontrl-lib/Capybarawith gradient checkpointing and accumulation for memory efficiency. Training progress is logged to Weights & Biases (W&B). The task requests a 24GB+ GPU, ensuring efficient model fine-tuning on dstack.The configuration uses theNoteWANDB_API_KEYandWANDB_PROJECTenvironment variables for logging training metrics with Weights & Biases (W&B). To use W&B, create an account and retrieve your API key forWANDB_API_KEY. TheWANDB_PROJECTvariable can be set to any preferred project name for organizing experiment logs.Apply the configuration.
console$ dstack apply -f .dstack.yaml
The configuration may take up to several minutes to start (depending on which machine you’re using; VM start under 2 minutes while baremetals may take 30 min to provision). The fine-tuning process may further take additional time to complete the process and store the model.
Visit WandDB Dashboard by accessing the URL in terminal output to track model fine-tuning process.
Conclusion
In this guide, you successfully fine-tuned the DeepSeek R1 Distill Qwen 1.5B model using dstack on Vultr Cloud GPUs. You set up a virtual environment, installed dstack, and configured Vultr as your cloud provider, streamlining the training process. With this setup, you can now efficiently train and optimize AI models at scale, ensuring high-performance and reliable machine learning workflows.
For more information, refer to the following documentation: