
How to Use Vultr Serverless Inference For Retrieval Augmented Generation
Introduction
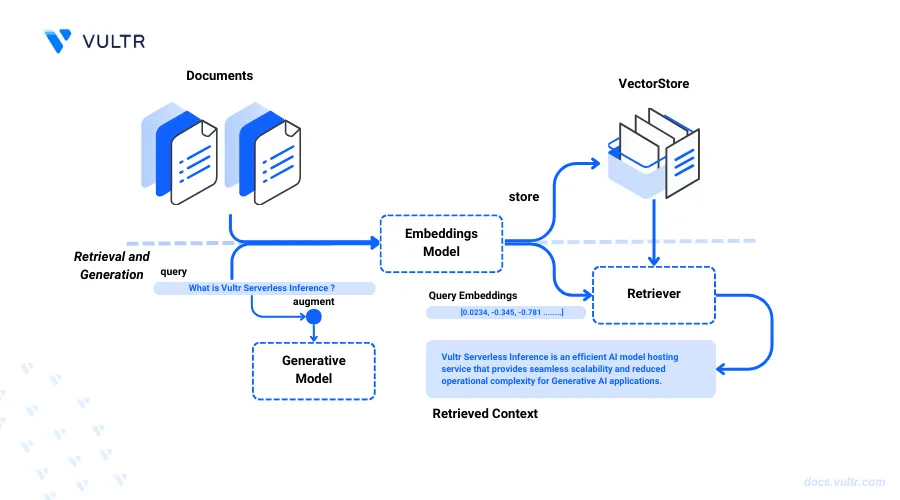
RAG (Retrieval-Augmented Generation) is a technique that combines retrieval and generation. It first retrieves relevant information from a dataset and then uses this information to generate responses. This approach enhances the model's ability to provide accurate and contextually relevant answers by leveraging external knowledge.
Vultr Serverless Inference's endpoints allows you to create collections in vector stores, these collections can be used store files and content. Using the stored content, embeddings are generated which can be used for the RAG functionality.
This article demonstrates step-by-step process to utilize the vector store and RAG completion endpoint using Vultr Serverless Inference.
Prerequisites
- Create a Vultr Serverless Inference Subscription.
- Fetch the API key for Vultr Serverless Inference.
Perform RAG Operations
Create a vector store collection.
console$ curl "https://api.vultrinference.com/v1/vector_store" \ -X POST \ -H "Authorization: Bearer ${VULTR_API_KEY}" \ -H "Content-Type: application/json" \ -d '{ "name": "<collection-name>" }'
When the API call is executed you will receive a collection ID in the output. Note down the collection ID as it will be used further in this article.
Confirm the presence of collection by sending a
GETrequest.console$ curl "https://api.vultrinference.com/v1/vector_store" \ -X GET \ -H "Authorization: Bearer ${VULTR_API_KEY}" \ -H "Content-Type: application/json"
When the API call is executed you will be able to see all the collections present.
Create a collection item in the created collection.
console$ curl "https://api.vultrinference.com/v1/vector_store/<collection-id>/items" \ -X POST \ -H "Authorization: Bearer ${VULTR_API_KEY}" \ -H "Content-Type: application/json" \ -d '{ "content": "<some-content>", "description": "<some-description>" }'
content: The text to be converted into embeddings and stored in the vector store collection.description: A description of the contents in this collection item record. If omitted, this value will default to a shortened version of the text stored in the collection.
When the API call is executed you will be able to see an ID generated specific to the collection item. A similar API request can be sent to feed a document.
View all the collection items in the collection.
console$ curl "https://api.vultrinference.com/v1/vector_store/first_collecti/items" \ -X GET \ -H "Authorization: Bearer ${VULTR_API_KEY}" \ -H "Content-Type: application/json"
Send a RAG chat completion request.
console$ curl "https://api.vultrinference.com/v1/chat/completions/RAG" \ -X POST \ -H "Authorization: Bearer ${VULTR_API_KEY}" \ -H "Content-Type: application/json" \ -d '{ "collection": "<collection-id>", "model": "llama2-7b-chat-Q5_K_M", "messages": [ { "role": "user", "content": "<some-content>" } ], "max_tokens": 512, "seed": -1, "temperature": 0.8, "top_k": 40, "top_p": 0.9 }'
When you execute the API call, you'll receive a generated response. If your query pertains to the content within the collection item you just created, the model will use that content as context to generate an informed answer.
Conclusion
In this article, you learned how to use Vultr Serverless Inference for creating vector collections and infer them using the RAG chat completion endpoint. You can now integrate Vultr Serverless Inference into your applications to provide a personalized experience.