
AI Powered Search with Python and Milvus Vector Database
Introduction
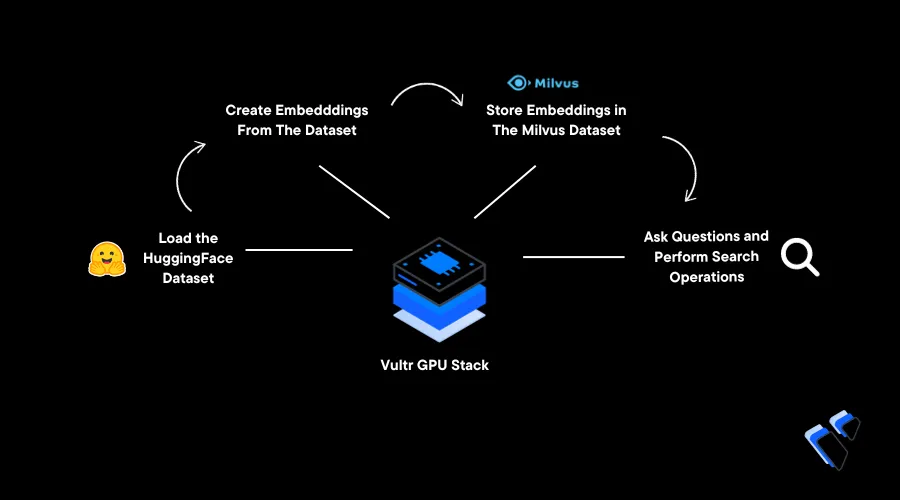
Vector databases are commonly used to store vector embeddings for tasks such as similarity search to build recommendation and question-answering systems. Milvus is a popular open-source database that stores embeddings in the form of vector data. It is well-suited and offers indexing features like Approximate Nearest Neighbours (ANN) that enable fast and accurate results.
This article explains how to implement AI-powered search with Python and a Milvus Database. You will use a HuggingFace dataset, create embeddings from the dataset, divide the dataset into two halves (testing and training), and store all created embeddings to a Milvus database by creating a collection. Then, you are to perform a search operation by giving a question prompt and generate the most similar answers.
Prerequisites
Before you begin:
Deploy a Vultr Kubernetes Engine cluster with at least:
- 4 nodes
- 4 GB RAM
- 2 vCPUs
Deploy a Ubuntu 22.04 A100 Vultr Cloud GPU server.
Use SSH to access the server as a non-root sudo user
Install and Configure Kubectl to access the cluster
Deploy MilvusDB to the VKE cluster
Contact Vultr Support to verify that your account is eligible to deploy at least 20 Block Storage instances required by Milvus DB
Set Up the Server
To develop and deploy your application, install the necessary dependencies and parameters on the server. Then, connect to your Milvus Cluster to set up database operations as described in the steps below.
Using
pip, install the necessary dependencies$ pip install transformers datasets pymilvus torchBelow is what each package does:
transformers: A HuggingFace library used to access and work with pre-trained LLM models for tasks such as text classification and generationdatasets: A HuggingFace library that allows you to access and work with ready-to-use datasets for Natural Language Processing (NLP) taskspymilvus: The Milvus Python client that allows you to perform vector similarity search, storage, and management of large collectionstorch: A machine learning library used to train and build deep learning models
Open the Python console
$ python3Import the required modules
>>> from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility from datasets import load_dataset_builder, load_dataset, Dataset from transformers import AutoTokenizer, AutoModel from torch import clamp, sumBelow is what each of the imported module classes does:
pymilvus:connections: Provides functions to manage connections to the Milvus databaseFieldSchema: Define the schema of fields in a Milvus databaseCollectionSchema: Defines the schema of a collectionDataType: Enumerates data types used in a Milvus collectionCollection: Provides the functionality to interact with Milvus collections to create, insert, and search vectorsutility: Provides the data preprocessing and query optimization functions to work with Milvus
datasets:load_dataset_builder: Loads and returns dataset objects to accesss the database information and its metadataload_dataset: Loads a dataset from a dataset builder and returns the dataset object for data accessDataset: Represents a dataset that provides access to data-related operations
transformers:AutoTokenizer: Loads the pre-trained tokenization models for NLP tasksAutoModel: A model loading class that automatically loads pre-trained models for NLP tasks
torch:clamp: Provides functions for element-wise limiting of tensor valuessum: Computes the sum of tensor elements along specified dimensions
Declare the necessary parameters
>>> DATASET = 'squad' MODEL = 'bert-base-uncased' TOKENIZATION_BATCH_SIZE = 1000 INFERENCE_BATCH_SIZE = 64 INSERT_RATIO = .001 COLLECTION_NAME = 'huggingface_db' DIMENSION = 768 LIMIT = 10 MILVUS_HOST = "MILVUS_CLUSTER_IP_ADDRESS" MILVUS_PORT = "19530"Below is what each declared parameter does:
DATASET: Defines the Huggingface dataset to use when searching for answersMODEL: Defines the transformer to use for creating embeddingsTOKENIZATION_BATCH_SIZE: Determines how many text elements are processed at once during tokenization. This helps to speed up tokenization by using parallelismINFERENCE_BATCH_SIZE: Sets the batch size for predictions, affecting the efficiency of text classification tasks. You can reduce the batch size to32or18when using a smaller GPU sizeINSERT_RATIO: Controls the part of text data to convert into embeddings managing the volume of data to index when performing vector searchCOLLECTION_NAME: Sets the collection name you intend to createDIMENSION: Sets the size of an individual embedding to store in the collectionLIMIT: Sets the number of results to search and display in the outputMILVUS_HOST: Sets the VKE cluster external IP address to access the Milvus databaseMILVUS_PORT: Defines the Milvus Database port accessible using the cluster host IP address
Connect to the Milvus database. Replace
192.0.2.100,19530,root, andMilvuswith your actual Milvus cluster values>>> connections.connect(host=192.0.2.100, port=19530 user=root, password=Milvus)The above command creates a connection to the Milvus database using your VKE cluster deployment details.
Build the Question Answering System
To build the question-answering system, create a collection. Then, insert data to the collection after tokenizing and creating the embeddings.In addition, perform a search operation to get the relevant answers for a specific question to test the system functionality as described in the following sections.
Create a Collection
In this section, check for the existence of the collection, create the collection, and set up the index for the collection. To perform text-based operations, load the collection as described in the steps below.
Verify if a collection exists. Replace
COLLECTION_NAMEwith your target collection name>>> if utility.has_collection(COLLECTION_NAME): utility.drop_collection(COLLECTION_NAME)The above command checks if the collection you are making is already made or not, if the collection is present then it is deleted to avoid any conflicts.
Create a new collection. Replace
COLLECTION_NAMEwith your desired name>>> fields = [ FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True), FieldSchema(name='original_question', dtype=DataType.VARCHAR, max_length=1000), FieldSchema(name='answer', dtype=DataType.VARCHAR, max_length=1000), FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION) ] schema = CollectionSchema(fields=fields) collection = Collection(name=COLLECTION_NAME, schema=schema)The above code defines a new collection schema with the following fields:
id: Sets the primary field in which all database entries identifiedoriginal_question: Stores the original question and matches any other question you askanswer: Holds the answer to eachoriginal_quesitionoriginal_question_embedding: Contains embeddings for each entry in theoriginal_questionto perform a similarity search with your input question
Create the collection index
>>> index_params = { 'metric_type':'L2', 'index_type':"IVF_FLAT", 'params':{"nlist":1536} } >>> collection.create_index(field_name="original_question_embedding", index_params=index_params)The above code creates a new index for the
original_question_embeddingfield to perform a similarity search. When successful, your output should look like the one below:Status(code=0, message=)Load the collection
>>> collection.load()The above code loads the collection which is important when working with vector databases. Loading the collection ensures that the collection is ready to perform search operations.
Insert Data to the Collection
Load the dataset
>>> data_dataset = load_dataset(DATASET, split='all') data_dataset = data_dataset.train_test_split(test_size=INSERT_RATIO, seed=42)['test'] data_dataset = data_dataset.map(lambda val: {'answer': val['answers']['text'][0]}, remove_columns=['answers'])The above code loads the dataset, splits the dataset into training and test sets, then processes the test set to remove any other columns except for the answer text.
Initialize the tokenizer
>>> tokenizer = AutoTokenizer.from_pretrained(MODEL)Tokenize the question
>>> def tokenize_question(batch): results = tokenizer(batch['question'], add_special_tokens = True, truncation = True, padding = "max_length", return_attention_mask = True, return_tensors = "pt") batch['input_ids'] = results['input_ids'] batch['token_type_ids'] = results['token_type_ids'] batch['attention_mask'] = results['attention_mask'] return batchThe above code defines a function
tokenize_questionthat takes a batch of data as input and tokenizes thequestionfield into an acceptable Bert model format. It applies truncation and padding, then returns the encoded data in a batch along withinput_ids,token_type_ids, andattention_mask. This is a common pre-processing step in NLP tasks before you send data to the model.Tokenize each entry
>>> data_dataset = data_dataset.map(tokenize_question, batch_size=TOKENIZATION_BATCH_SIZE, batched=True) data_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True)The above code uses the
mapfunction on thedata_datasetand applies thetokenize_questionfunction on every question in the dataset. When successful, the output format is set to atorchcompatible format for PyTorch based machine learning models.Create the embeddings
>>> model = AutoModel.from_pretrained(MODEL) >>> def embed(batch): sentence_embs = model( input_ids=batch['input_ids'], token_type_ids=batch['token_type_ids'], attention_mask=batch['attention_mask'] )[0] input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand(sentence_embs.size()).float() batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9) return batch >>> data_dataset = data_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)The above code loads the pre-trained model and passes the tokenized questions through the model to get the required embeddings and the generated embeddings are added to the dataset as
question_embeddings.Insert questions into a collection
>>> def insert_function(batch): insertable = [ batch['question'], [x[:995] + '...' if len(x) > 999 else x for x in batch['answer']], batch['question_embedding'].tolist() ] collection.insert(insertable) >>> data_dataset.map(insert_function, batched=True, batch_size=64) collection.flush()The above code uses data from the dataset and inserts it to the collection. The
answeris then truncated to consider the VARCHAR limit as displayed in the following output:Dataset({ features: ['id', 'title', 'context', 'question', 'answer', 'input_ids', 'token_type_ids', 'attention_mask', 'question_embedding'], num_rows: 99 })
Generate responses
In this section, create a custom question dataset, tokenize, and embed the dataset. Then, perform a search operation in the Milvus collection to find the top relevant answers for your question.
Create a new question dataset. Replace
When was maths inventedwith your desired question>>> questions = {'question':['When was maths invented?']} question_dataset = Dataset.from_dict(questions)The above code creates a new
question_datasetdataset. You can increase the number of questions you wnt to generate answers using thequestionsvariable.Tokenize and embed the question
>>> question_dataset = question_dataset.map(tokenize_question, batched = True, batch_size=TOKENIZATION_BATCH_SIZE) >>> question_dataset.set_format('torch', columns=['input_ids', 'token_type_ids', 'attention_mask'], output_all_columns=True) >>> question_dataset = question_dataset.map(embed, remove_columns=['input_ids', 'token_type_ids', 'attention_mask'], batched = True, batch_size=INFERENCE_BATCH_SIZE)The above code tokenizes the
question_datasetusing thetokenize_questionfunction. Then, sets the output format totorchand embeds thequestion_datasetby applying theembedfunction to generate the embeddings.Define the search function
>>> def search(batch): res = collection.search(batch['question_embedding'].tolist(), anns_field='original_question_embedding', param = {}, output_fields=['answer', 'original_question'], limit = LIMIT) overall_id = [] overall_distance = [] overall_answer = [] overall_original_question = [] for hits in res: ids = [] distance = [] answer = [] original_question = [] for hit in hits: ids.append(hit.id) distance.append(hit.distance) answer.append(hit.entity.get('answer')) original_question.append(hit.entity.get('original_question')) overall_id.append(ids) overall_distance.append(distance) overall_answer.append(answer) overall_original_question.append(original_question) return { 'id': overall_id, 'distance': overall_distance, 'answer': overall_answer, 'original_question': overall_original_question }The above
searchfunction performs a search operation using the embeddings. It searches for similar questions in the embeddings and retrieves information such as theid,distance,answerandoriginal_question. Retrieved information is organized into lists and returned as a dictionary.Perform a search operation
>>> question_dataset = question_dataset.map(search, batched=True, batch_size = 1) >>> for x in question_dataset: print() print('Question:') print(x['question']) print('Answer, Distance, Original Question') for x in zip(x['answer'], x['distance'], x['original_question']): print(x)The above code applies the search function you defined earlier in the
question_dataset. When successful, it prints the information for each question as displayed in the output below:Question: When was maths invented? Answer, Distance, Original Question ('until 1870', tensor(33.3018), 'When did the Papal States exist?') ('October 1992', tensor(34.8276), 'When were free elections held?') ('1787', tensor(36.0596), 'When was the Tower constructed?') ('Poland, Bulgaria, the Czech Republic, Slovakia, Hungary, Albania, former East Germany and Cuba', tensor(38.3254), 'Where was Russian schooling mandatory in the 20th century?') ('6,000 years', tensor(41.9444), 'How old did biblical scholars think the Earth was?') ('1992', tensor(42.2079), 'In what year was the Premier League created?') ('1981', tensor(44.7781), "When was ZE's Mutant Disco released?") ('Medieval Latin', tensor(46.9699), "What was the Latin of Charlemagne's era later known as?") ('taxation', tensor(49.2372), 'How did Hobson argue to rid the world of imperialism?') ('light weight, relative unbreakability and low surface noise', tensor(49.5037), "What were advantages of vinyl in the 1930's?")As displayed in the above output, the closest 10 answers are generated in descending order for the question you asked along with the original questions those answers belong to. The output also displays tensor values with each answer, a less tensor value means that the generated answer is more accurate to your question.
Conclusion
You have built a question answering system using a HuggingFace dataset and Milvus. You created embeddings from the dataset, stored them in a Milvus collection, and performed a similarity search to find the most suitable answers for the provided prompt. You can modify the questions to return more accurate results depending on the tensor values associated with each answer.
Next Steps
To implement more solutions on your Vultr Cloud GPU server, visit the following resources:
- Create embeddings using Sentence Transformers
- Build a Recommendation system using BERT and Nvidia NGC