Nemotron 3 Nano 30B
Updated on 11 March, 2026Deploy NVIDIA's Nemotron 3 Nano on NVIDIA HGX B200 GPUs. This hybrid Mamba-Transformer model delivers high throughput with only 3B active parameters per token.
Model Overview
| Property | Value |
|---|---|
| Model ID | nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 |
| Architecture | Hybrid Mamba-Transformer MoE |
| Total Parameters | 30B |
| Active Parameters | 3B per token |
| Attention | Mamba (linear/SSM) + Standard Transformer (interleaved) |
| Routing | MoE (128 experts) |
| Context Length | 1,048,576 tokens (1M) |
| Quantization | FP8 (also available: NVFP4, BF16) |
| License | NVIDIA Open Model License |
| Link | HuggingFace |
Architecture
Nemotron Nano uses a hybrid Mamba-Transformer architecture — the first production model to combine State Space Model (SSM) layers with traditional attention layers at scale. Mamba layers process sequences in linear time (O(n)) without maintaining a KV cache, while Transformer layers handle tasks that benefit from full attention. The MoE routing activates only 3B of the 30B total parameters per token.
This architecture has three implications for NVIDIA HGX B200 deployment:
- Minimal KV cache: Mamba layers have no KV cache, so memory consumption grows much slower with context length than pure-attention models
- High throughput at low TP: Only 3B active params means a single NVIDIA HGX B200 has more than enough compute
- NVFP4 support: The NVIDIA HGX B200's native NVFP4 format can further halve memory usage versus FP8
Quick Start
$ vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code
Or with Docker:
$ docker run --rm --gpus all --ipc=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
vllm/vllm-openai:v0.16.0 \
--model nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code
--trust-remote-code is required — the nemotron_h architecture uses custom model code.
Configuration
| Flag | Purpose |
|---|---|
--tensor-parallel-size 2 |
Distribute across 2 GPUs. TP=1 also works but leaves less room for KV cache |
--max-model-len 32768 |
Context window. Increase up to 1M for long-context workloads |
--gpu-memory-utilization 0.90 |
Reserve 90% of VRAM for model + KV cache |
--trust-remote-code |
Required for custom nemotron_h architecture |
--kv-cache-dtype fp8 |
Optional: FP8 KV cache for even lower memory usage |
Memory Usage (NVIDIA HGX B200 Verified)
With TP=2 on FP8:
| Component | Per GPU | Total (2 GPUs) |
|---|---|---|
| Model weights | ~15 GB | ~30 GB |
| KV cache (available) | ~139 GB | ~278 GB |
| VRAM used | 169 GB | 338 GB |
| Max concurrent (32K ctx) | 1,298x | - |
The model uses only 169 GB per GPU out of 179 GB available, leaving 139 GB per GPU for KV cache — enough for over 1,200 concurrent requests at 32K context length.
Performance (NVIDIA HGX B200 Verified)
Benchmark parameters: 2048 input tokens, 512 output tokens, random dataset. TP=2 on 2x NVIDIA HGX B200.
Concurrency Scaling
| Concurrent | Output tok/s | Peak tok/s | TTFT (ms) | TPOT (ms) | ITL p99 (ms) |
|---|---|---|---|---|---|
| 1 | 277 | 344 | 362 | 2.91 | 3.14 |
| 8 | 1,881 | 2,264 | 152 | 3.96 | 4.28 |
| 16 | 3,455 | 3,952 | 160 | 4.32 | 5.19 |
| 32 | 3,798 | 4,416 | 206 | 7.86 | 40.72 |
| 64 | 8,120 | 10,688 | 324 | 6.74 | 43.82 |
| 128 | 11,556 | 17,536 | 520 | 8.91 | 45.19 |
| 256 | 15,552 | 26,908 | 1,254 | 11.77 | 48.20 |
| 512 | 18,746 | 32,935 | 2,610 | 15.46 | 47.88 |
| 1024 | 18,829 | 32,780 | 2,563 | 15.46 | 47.75 |
Zero failed requests across all concurrency levels.
Peak Performance
| Metric | Value |
|---|---|
| Peak sustained throughput | 18,829 tok/s (output) |
| Peak burst throughput | 32,935 tok/s |
| Saturation point | ~512 concurrent requests |
| TTFT at 32 concurrent | 206 ms |
| TPOT at 32 concurrent | 7.86 ms |
Scaling Behavior
Throughput scales linearly from concurrency 1 to 256 (~56x increase), then plateaus around 512 concurrent. The model saturates at approximately 18,800 tok/s sustained output throughput on 2 GPUs. TTFT degrades linearly with concurrency — expected behavior as prefill requests queue. TPOT remains under 8ms up to 32 concurrent, making this suitable for real-time applications at moderate load.
Test Endpoints
Chat Completion
$ curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8",
"messages": [{"role": "user", "content": "Explain KV caching in transformers"}],
"max_tokens": 256
}'
Text Completion
$ curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8",
"prompt": "The NVIDIA HGX B200 GPU features",
"max_tokens": 128
}'
NVFP4 Variant
NVIDIA HGX B200 supports NVIDIA's FP4 format (NVFP4), which halves memory compared to FP8. The NVFP4 variant of Nemotron Nano can run on a single GPU:
$ vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code
NVFP4 Performance (NVIDIA HGX B200 Verified)
Benchmark parameters: 2048 input tokens, 512 output tokens, random dataset. TP=1 on 1x NVIDIA HGX B200.
| Concurrent | Output tok/s | Peak tok/s | TTFT (ms) | TPOT (ms) | ITL p99 (ms) |
|---|---|---|---|---|---|
| 1 | 257 | 320 | 387 | 3.13 | 3.26 |
| 8 | 1,636 | 1,960 | 298 | 4.32 | 4.49 |
| 16 | 2,902 | 3,392 | 203 | 5.12 | 6.22 |
| 32 | 4,264 | 5,189 | 280 | 6.77 | 38.31 |
| 64 | 6,401 | 8,576 | 507 | 8.44 | 56.80 |
| 128 | 9,153 | 13,821 | 692 | 11.26 | 59.11 |
| 256 | 12,998 | 20,226 | 1,644 | 14.38 | 64.02 |
| 512 | 15,496 | 28,259 | 3,378 | 18.51 | 63.90 |
| 1024 | 15,575 | 28,230 | 3,322 | 18.49 | 64.33 |
FP8 vs NVFP4 Comparison
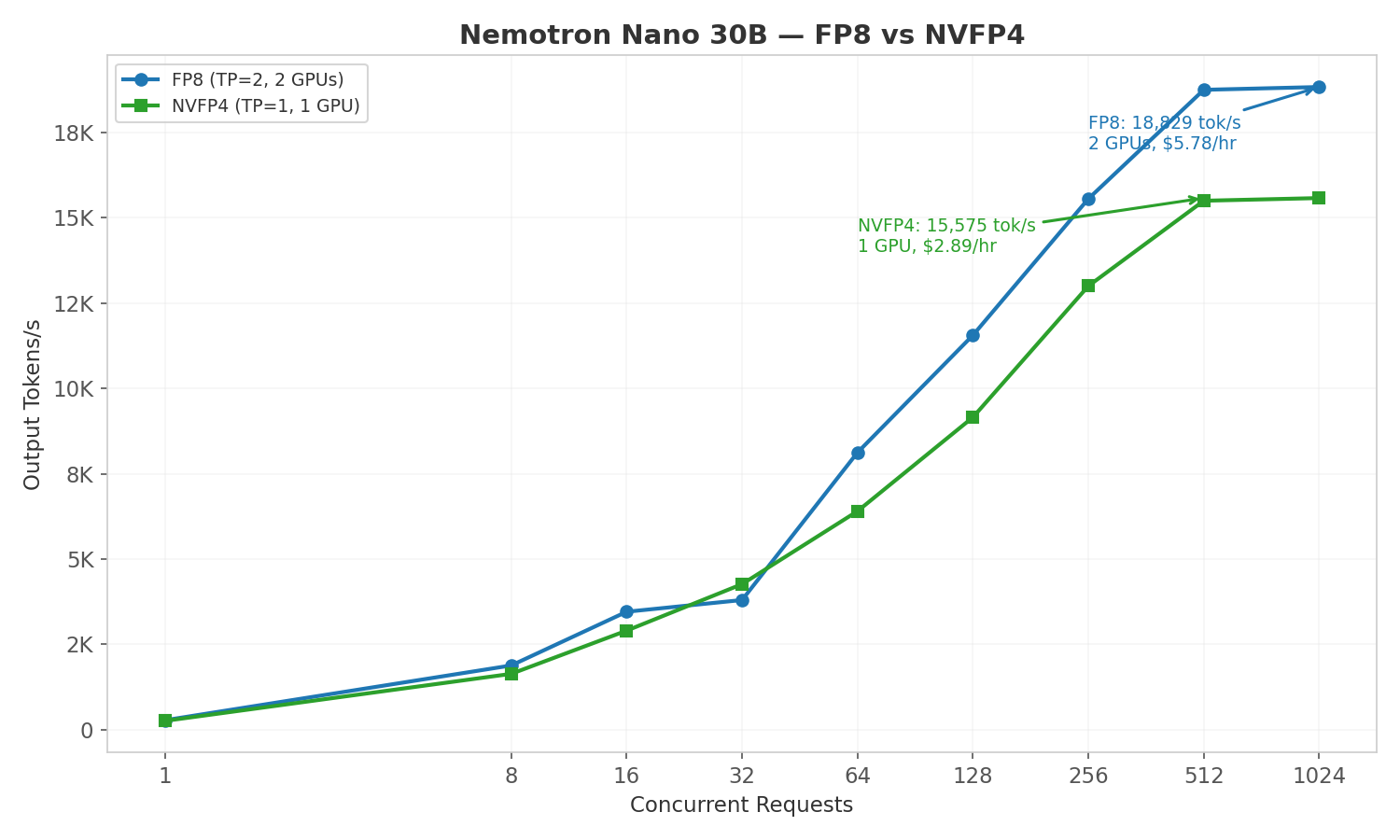
| Metric | FP8 (TP=2, 2 GPUs) | NVFP4 (TP=1, 1 GPU) |
|---|---|---|
| Peak sustained tok/s | 18,829 | 15,575 |
| tok/s per GPU | 9,415 | 15,575 |
| VRAM used | 169 GB × 2 = 338 GB | 173 GB × 1 = 173 GB |
NVFP4 delivers 1.65x better cost efficiency than FP8 by eliminating the second GPU entirely. On a single 8-GPU node, you could run 8 NVFP4 instances (~124,000 tok/s aggregate) vs 4 FP8 instances (~75,000 tok/s aggregate). NVFP4 is an NVIDIA HGX B200-exclusive feature not available on prior GPU generations.
Goodput: FP8 vs NVFP4 (SLOs: TTFT<500ms, TPOT<50ms)
| Concurrency | FP8 Goodput (req/s) | NVFP4 Goodput (req/s) |
|---|---|---|
| 32 | 6.10 | 7.21 |
| 64 | 13.29 | 8.90 |
| 128 | 6.20 | 8.24 |
| 256 | 3.65 | 8.87 |
FP8 has higher peak goodput (13.29 vs 8.90 at c=64) because TP=2 distributes prefill across 2 GPUs, keeping TTFT lower. But NVFP4 uses half the GPUs (1 vs 2), delivering better per-GPU efficiency.
See FP8/NVFP4 Quantization for more details.
Startup Time (Model Cached)
| Configuration | Weight Load | Total Startup |
|---|---|---|
| FP8 (TP=2) | 4.6s | ~70s |
| NVFP4 (TP=1) | 3.6s | ~41s |
First-time model download adds ~1 minute for Nemotron Nano (~15–31 GB).
Known Issues
- MoE config warning: vLLM logs
Using default MoE config. Performance might be sub-optimal!because no tuned FP8 MoE kernel config exists for NVIDIA HGX B200 yet. Performance is still strong — a tuned config would likely improve throughput further. - Custom code: Always pass
--trust-remote-code. Without it, vLLM cannot load thenemotron_harchitecture.