Llama-3.3 Nemotron Super 49B
Updated on 11 March, 2026Deploy NVIDIA's Nemotron Super 49B on NVIDIA HGX B200 GPUs. This dense transformer model is based on Llama 3.3 with NAS-optimized architecture, delivering strong reasoning performance.
Model Overview
| Property | Value |
|---|---|
| Model ID | nvidia/Llama-3_3-Nemotron-Super-49B-v1_5-FP8 |
| Architecture | NAS-optimized Transformer (Llama-based) |
| Total Parameters | 49B (dense) |
| Active Parameters | 49B per token |
| Attention | Standard multi-head attention |
| Context Length | 131,072 tokens (128K) |
| Quantization | FP8 (also available: bf16, NVFP4) |
| License | NVIDIA Open Model License |
| Link | HuggingFace |
Architecture
Nemotron Super uses a NAS-optimized dense transformer based on the Llama 3.3 architecture. Unlike the hybrid Mamba-Transformer design of Nemotron Nano, this is a standard attention model — all 49B parameters are active on every token. This makes it compatible with NVIDIA Dynamo's NIXL KV transfer for disaggregated prefill/decode serving.
Key deployment characteristics on NVIDIA HGX B200:
- FP8 fits on 1 GPU: ~49 GB FP8 weights leave ~130 GB for KV cache on a 179 GB NVIDIA HGX B200
- Standard KV cache: Compatible with all vLLM optimizations including prefix caching and NIXL transfer
- FP8 delivers 1.7x throughput over bf16: Measured at high concurrency on NVIDIA HGX B200
Quick Start
$ vllm serve nvidia/Llama-3_3-Nemotron-Super-49B-v1_5-FP8 \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code
Or with Docker:
$ docker run --rm --gpus all --ipc=host \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
vllm/vllm-openai:v0.16.0 \
--model nvidia/Llama-3_3-Nemotron-Super-49B-v1_5-FP8 \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--gpu-memory-utilization 0.90 \
--trust-remote-code
--trust-remote-code is required for the nemotron-nas architecture.
Configuration
| Flag | Purpose |
|---|---|
--tensor-parallel-size 1 |
FP8 fits on 1 GPU. Use TP=8 for maximum throughput across all GPUs |
--max-model-len 32768 |
Context window. Model supports up to 128K |
--gpu-memory-utilization 0.90 |
Reserve 90% of VRAM for model + KV cache |
--trust-remote-code |
Required for custom nemotron-nas architecture |
Performance: FP8 (NVIDIA HGX B200 Verified)
Benchmark parameters: 2048 input tokens, 512 output tokens, random dataset. TP=1 on 1x NVIDIA HGX B200.
Concurrency Scaling
| Concurrent | Output tok/s | TTFT (ms) | TPOT (ms) |
|---|---|---|---|
| 1 | 73 | 170 | 13.40 |
| 8 | 570 | 71 | 12.34 |
| 16 | 1,054 | 117 | 11.17 |
| 32 | 2,120 | 172 | 11.57 |
| 64 | 3,816 | 205 | 12.70 |
| 128 | 3,799 | 222 | 12.70 |
| 256 | 1,586 | 5,551 | 20.56 |
| 512 | 3,775 | 271 | 12.69 |
| 1024 | 1,587 | 5,544 | 20.56 |
Peak sustained throughput is 3,816 tok/s at c=64, with throughput oscillating at higher concurrency due to batch scheduling effects at TP=1.
Performance: bf16 (NVIDIA HGX B200 Verified)
Benchmark parameters: 2048 input tokens, 512 output tokens, random dataset. TP=1 on 1x NVIDIA HGX B200.
| Concurrent | Output tok/s | TTFT (ms) | TPOT (ms) |
|---|---|---|---|
| 1 | 54 | 161 | 18.15 |
| 8 | 379 | 98 | 18.75 |
| 16 | 651 | 114 | 19.22 |
| 32 | 1,224 | 184 | 20.19 |
| 64 | 2,224 | 250 | 22.00 |
| 128 | 2,228 | 225 | 21.99 |
| 256 | 2,228 | 225 | 21.99 |
| 512 | 2,231 | 220 | 21.99 |
| 1024 | 1,365 | 4,286 | 28.08 |
bf16 saturates at ~2,230 tok/s with consistent TTFT and TPOT through c=512.
FP8 vs bf16 Comparison
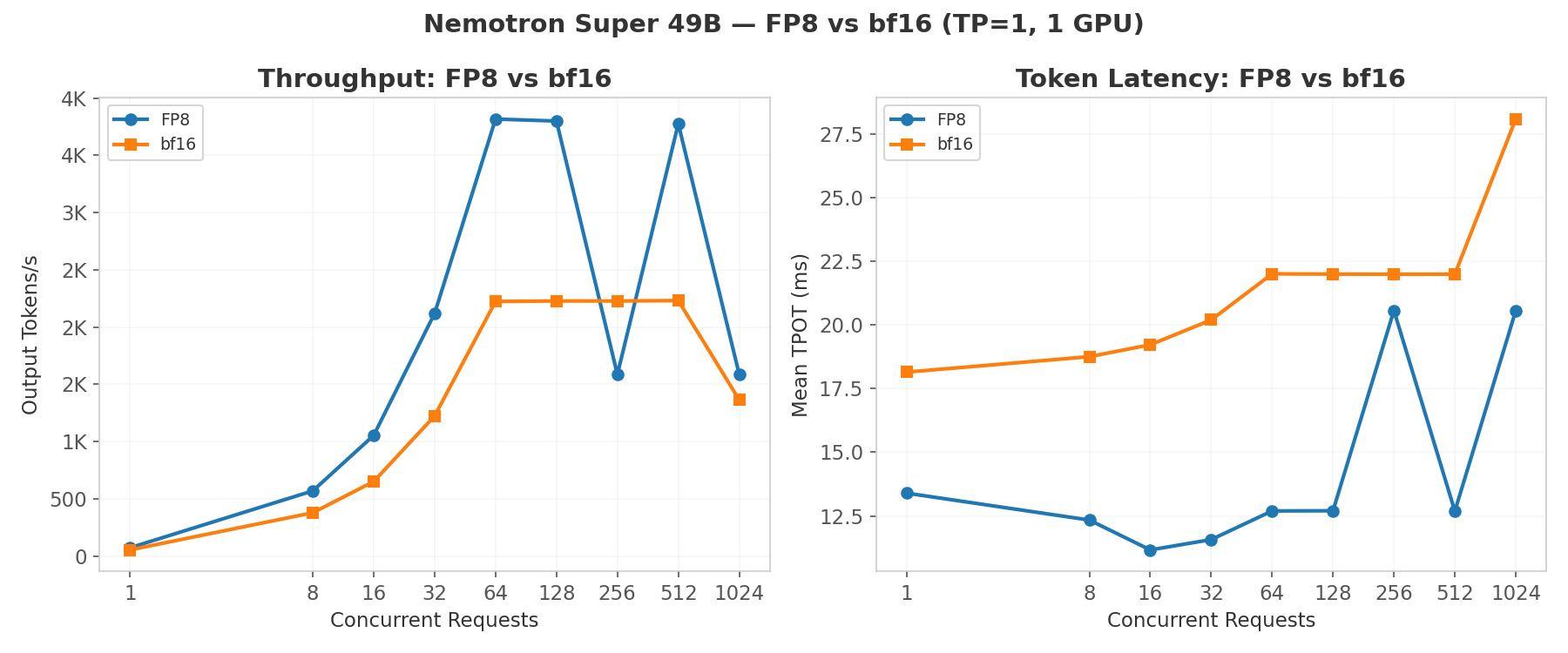
| Metric | FP8 (TP=1) | bf16 (TP=1) |
|---|---|---|
| Peak sustained tok/s | 3,816 | 2,231 |
| VRAM (weights) | ~49 GB | ~98 GB |
| VRAM (KV cache available) | ~130 GB | ~80 GB |
| TPOT at c=64 | 12.70 ms | 22.00 ms |
| Throughput advantage | 1.71x | — |
FP8 delivers 1.71x higher peak throughput with half the memory footprint. The extra KV cache capacity from lower weight size enables better batching at high concurrency.
Dynamo Disaggregated Serving
This model was tested with NVIDIA Dynamo for prefill/decode disaggregation. See Dynamo Overview for full setup and results.
Multi-GPU Aggregated Baseline (TP=8, 8 GPUs)
| Concurrent | Output tok/s | TTFT (ms) | TPOT (ms) |
|---|---|---|---|
| 1 | 161 | 20 | 6.05 |
| 32 | 2,677 | 138 | 8.23 |
| 128 | 4,900 | 174 | 8.50 |
| 256 | 4,911 | 172 | 8.53 |
Best Disaggregated Config (2P+6D, TP=1)
| Concurrent | Output tok/s | TTFT (ms) | TPOT (ms) |
|---|---|---|---|
| 1 | 52 | 809 | 17.89 |
| 32 | 971 | 4,378 | 17.65 |
| 128 | 984 | 8,075 | 17.81 |
| 256 | 953 | 7,938 | 17.82 |
Aggregated TP=8 outperforms disaggregated 2P+6D by 5x on throughput. The model fits comfortably on 1 GPU, so disaggregation adds NIXL transfer overhead without resolving any memory bottleneck. See the Dynamo chapter for analysis of when disaggregation helps.
Known Issues
- FP8 + NIXL incompatible: The FP8 variant crashes in Dynamo disaggregated mode due to FlashInfer assertion (
Query dtype mismatch: expected torch.bfloat16, got torch.float8_e4m3fn). Use bf16 for disaggregated serving. - Custom code: Always pass
--trust-remote-code. Without it, vLLM cannot load thenemotron-nasarchitecture. - c=256/1024 throughput dip (FP8 TP=1): At certain concurrency levels, throughput drops due to batch scheduling effects. This is a TP=1 artifact — TP=8 aggregated does not exhibit this behavior.