

Introduction
Foundation models have become a cornerstone in revolutionizing how developers approach machine learning and they have gained a lot of popularity.
The journey of machine learning has been nothing short of captivating. In the early days of rule-based systems, deep learning models learned from data rather than hardcoded rules. The recent evolution saw the rise of transformer architectures that came with breakthroughs like BERT and GPT models that marked pivotal moments in developing foundation models. In the previous section, you learned the evolution of generative AI and the key differences between discriminative and generative AI. This section helps you to understand the foundation models and their contribution to generative AI.
Foundation Models Layers
Foundation models are large AI models trained on massive amounts of unlabeled data through self-supervised learning. This process produces generalized models capable of performing a wide range of tasks with remarkable accuracy. Samples of such tasks are image classification, natural language processing, and question answering.
A foundation model is a neural network pre-trained on large amounts of data. Unlike traditional models that are trained from scratch for specific tasks, foundation models follow a layered approach:
- Base Layer: This is a generic pre-training over extensive data where the model learns from diverse content ranging from text to images.
- Middle Layer: This is a domain-specific refinement that further narrows down the model's focus.
- Top Layer: This layer fine-tunes the model's performance in applications during text generation, image recognition, or any other AI task.
Before these large foundation models entered the scene, the norm was to build models for specific tasks, often from scratch. This approach was resource-intensive, time-consuming, and relied heavily on large labeled datasets.
The introduction of foundation models shifted the AI paradigm due to the following benefits:
- Reduced Cost: The reduced need for training led to significant cost savings and swift deployment.
- Flexible and Adaptable: Developers observed enhanced performance across many tasks. These models became powerful tools, offering flexibility like never before.
- Accessibility: Foundation models have become increasingly accessible hence democratizing AI capabilities and allowing even those without deep AI expertise to harness their power.
This shift came with a few challenges. Developers and data scientists now grapple with new responsibilities like understanding the nuances and potential biases of these models and ensuring their applications remain ethical and unbiased.
A Closer Look at Foundation Models
Foundation models have emerged as transformative entities in the history of artificial intelligence, redefining the landscape of machine learning development and deployment. They have been called everything from "game changers" to "paradigm shifters."
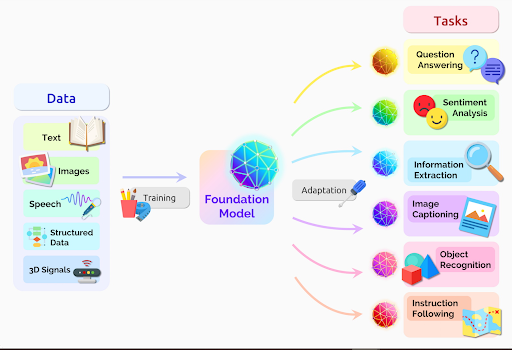
Foundation Models: A Bedrock for AI
At the heart of a foundation model is the idea of extensive pre-training on large-scale datasets, followed by task-specific fine-tuning. Unlike past models that were often trained from the ground up for a particular task, foundation models offer a broad base for building specific AI applications.
Key Characteristics of Foundation Model
- Large-scale data training: Foundation models thrive on lots of data. Whether it's text, images, or a combination of modalities. These models' designs consume vast amounts of information to understand patterns and structures in the input data.
- Generalization across tasks: Because they are trained on diverse datasets, foundation models have the inherent ability to generalize across a variety of tasks. They can understand the context, decipher nuances, and adapt to different scenarios more than their narrowly trained counterparts.
- Fine-tuning potential: A good feature of foundation models is their malleability. After their extensive pre-training, they can be fine-tuned to excel in specific domains or tasks. The foundation model inherits the broad knowledge from the foundational training to fine-tune the results' accuracy.
Types of Foundation Models
There are two categories of foundation models:
- Large Language Models (LLMs).
- Diffusion models.
Large Language Models
LLMs are machine learning models that process and generate natural language using deep learning techniques. They are trained on massive amounts of textual data and are capable of performing many language-related tasks such as language translation, text summarization, and question-answering. Because of their outstanding performance on various natural language processing tasks, transformer-based LLMs have gotten great attention. GPT-3, BERT, and RoBERTa are popular examples of LLMs.
Diffusion Models
Diffusion models generate data similar to the training input. These models work by introducing Gaussian noise into the training data and then learning to reverse the noise process to recover the original data. Diffusion models have demonstrated promising results in many applications like image and speech synthesis. The models are well-known for producing high-quality samples with fine details. The most well-known diffusion models are Dall-E, Imagen, and Glide.
In the upcoming sections of this series, you'll take a closer look at LLMs and diffusion models and integrate them into your applications.
The Evolving Landscape of Foundation Models
The foundation models are released in three licensing models:
Commercial Models
The model provider typically hosts the foundation models and makes them available under a commercial license. The source code for training the models, the weights, and the artifacts needed to host the models are confidential. These foundation models are available through an API that developers can invoke.
Examples of commercial models include GPT-4 from OpenAI, Command from Cohere, Claude 2 from Anthropic, and PaLM2, Imagen, and Chirp from Google.
Open Source Models
Open-source foundation models are generally available under the Apache 2 license or MIT licenses, which are quite permissive and allow for commercial use, distribution, modification, and private use. Models based on these licenses come with the source code for training, inference, and fine-tuning, along with the weights published in public repositories such as GitHub. These models also offer the datasets used for pre-training the models.
Examples of open-source foundation models are Falcon from TTI, T5 from Google, Dolly V2 from Databricks, and Bark from Suno.
Custom-licensed Models
Foundation models with custom licenses come with specific instructions on the usage and distribution of the model. The provider may or may not publish the source code used for training or share the dataset used for pre-training. These models have usage restrictions based on the number of users or invocations.
For example, the Llama 2 foundation model from Meta has a custom license that requires additional permissions if the number of monthly active users in the preceding calendar month exceeds 700 million. After agreeing to the terms and conditions, users must request the model's weights because they are unavailable in the public domain. The custom license allows both commercial and research usage of the model.
Stable Diffusion, a popular image generation model, is released under a Creative ML OpenRAIL-M license. This is a permissive license that allows for commercial and non-commercial usage. The license is focused on the ethical and legal use of the model and as your responsibility, you must include the license when distributing the model.
This series focuses on leveraging open-source and custom-licensed models to build applications powered by generative AI. You'll explore how to choose the right foundation model for a specific task and the steps involved in customizing and integrating them with applications.
The Foundation Model Supply Chain
Foundation models like software supply chains have a well-defined flow. These models follow several stages right from initial training.
The foundation model supply chain is a complex system that involves a variety of different players. However, it is important for the development and deployment of foundation models. By reviewing the different layers of the supply chain, you can better understand how foundation models are created and used.
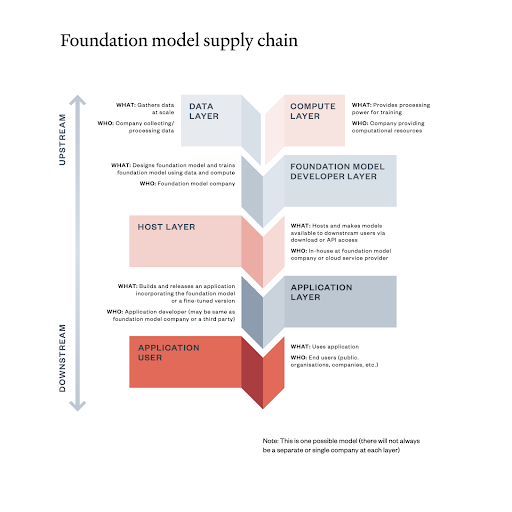
Source: Ada Lovelace Institute
The different layers of the supply chain are:
Data layer: The data layer is the foundation of the foundation model supply chain. The quality and quantity of the data have a significant impact on the performance of the foundation model. The data layer can be a bottleneck in the supply chain because it's sometimes difficult and expensive to collect and label large amounts of data. Compute layer: The compute layer is responsible for training the foundation model. The amount of computing resources depends on the size and complexity of the foundation model. The compute layer can also be a bottleneck in the supply chain because computational resources are expensive to purchase or rent. Foundation model developer layer: This layer is responsible for designing, training, and evaluating the foundation model. This layer involves researchers and engineers who have expertise in machine learning and artificial intelligence. Host layer: The host layer is responsible for hosting the foundation model and making it available to downstream users. The host layer can be a cloud computing platform, a private server, or a dedicated machine learning cluster. Application developer layer: This layer is responsible for building and releasing applications that incorporate the foundation model. This layer consists software engineers, product managers, and designers. Application user layer: The end users of the generative AI applications access the application user layer. These users are businesses, organizations, or individuals.
This section introduced the core concepts of foundation models and their contributions to generative AI. In the next section, you'll set up a testbed on a Vultr GPU server to explore foundation models using Python.
- Generative AI for Developers | Generative AI Series
- Understanding Foundation Models | Generative AI Series
- A Deeper Dive Into Large Language Models | Generative AI Series
- Interacting with Llama 2 | Generative AI Series
- Implementing RAG with Chroma and Llama 2 | Generative AI Series
- Using LangChain with Llama 2 | Generative AI Series
- Fine-Tuning Llama 2 | Generative AI Series
- Generating Images with Stable Diffusion | Generative AI Series
- Transcribing and Translating Audio | Generative AI Series
No comments yet.