
Introduction
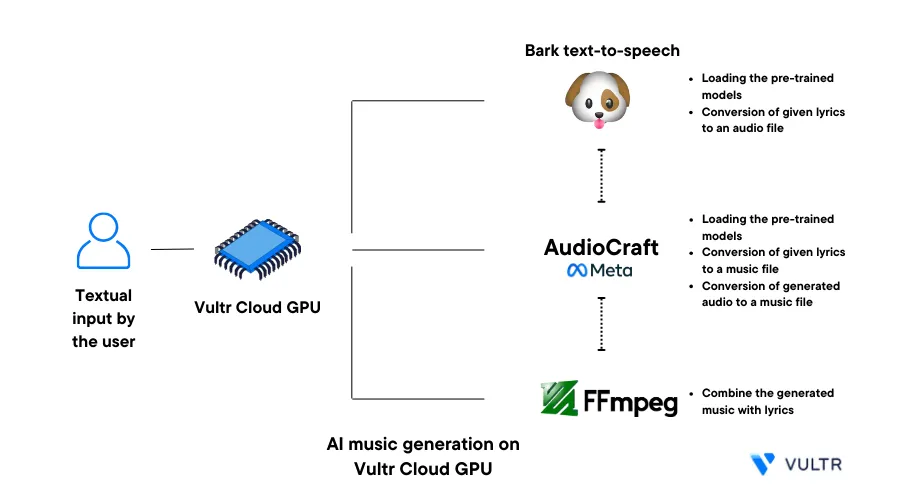
AI music generation is an innovative synthesis of art and science. By analyzing vast databases of existing musical compositions, AI models, often based on deep learning techniques have become adept at generating music across different genres and styles. With the advance of such models and algorithms, you can generate attractive music and sounds in a few minutes.
AudioCraft and Bark are two open-source text-to-audio tools used together to generate a soundtrack and lyrics to match an audio file. In addition, tools such as FFmpeg mix the generated melody and lyrics to create a single final output file.
This article explains how you can perform AI Music Generation tasks on a Vultr Cloud GPU server. You are to mix the generated soundtrack and lyrics to create a single output file you can download and share with personal licenses.
Prerequisites
Before you begin, make sure you:
- Deploy a Debian NVIDIA A100 Cloud GPU server on Vultr with at least:
- 1/7 GPU
- 10GB GPU RAM
- 15GB memory
- Using SSH, access the server
- Create a non-root user and switch to the user account
- Update the server
Set Up the Server
Install FFmpeg
$ sudo apt install ffmpegInstall the Python virtual environment package
$ sudo apt install python3.11-venvCreate a new Python Virtual environment
$ python3 -m venv myenvActivate the environment
$ source myenv/bin/activateUpgrade the Pip package manager
$ pip install --upgrade pipUsing
pip, the necessary dependency packages$ pip install torch==2.0.1 audiocraft==0.0.2 bark==0.1.5 protobuf==4.24.2The above command installs the following packages:
pyTorch: A deep-learning Python libraryaudiocraft: A PyTorch library used for deep learning on audio generationbark: A transformer-based text-to-audio modelprotobuf: A required package necessary for loading the AudioCraft model
Generate the Lyrics Audio
To create a full audio file, generate the lyrics audio before mounting a melody as described in the steps below.
Access the Python Shell
$ python3Import the
barklibrary and necessary packages to your sessionfrom bark import SAMPLE_RATE, generate_audio, preload_models from scipy.io.wavfile import write as write_wavDownload and load all bark text-to-audio models
>>> preload_models()The download process may take between 1 to 2 minutes to complete, and the total model size is above 10GB
Define your lyrics using the
lyrics_textvariable>>> lyrics_text = ''' In the realm of the digital, where clouds converge, Vultr's brilliance shines, a power to emerge. Bytes and data swirling in cosmic dance, Unveiling solutions, fate is given a chance. '''Replace the above lyrics with your desired text
Call the Bark library
generate_audiofunction to generate lyrics using the audio array>>> audio_array = generate_audio(lyrics_text)Save the generated audio to a local file. Replace
lyrics.wavwith your desired filename>>> write_wav('lyrics.wav', SAMPLE_RATE, audio_array)Exit the Python Shell
>>> exit ()List files in your working directory
$ lsVerify that your generated lyrics audio file is available
Generate the Sound Track
To generate a soundtrack you can combine with your lyrics audio, choose your desired audiocraft pre-trained model to apply. As of September 2023, below are the available models:
- Text-to-music only models:
- A small model with 300M parameters
- A medium model with 1.5B parameters
- A large model with 3.3B parameters
- A melody model with 1.5B parameters that supports melody-guided music generation
This section uses the melody model to generate a soundtrack based on your text prompt as described below.
Access the Python Shell
$ python 3Import the
audiocraftlibraries>>> from audiocraft.models import MusicGen >>> from audiocraft.data.audio import audio_writeLoad your target model. For this article,
melody>>> model = MusicGen.get_pretrained("melody")Set the soundtrack length
>>> model.set_generation_params(duration=14)It's recommended to generate a soundtrack with the same length as your lyrics audio. The above code generates a track with 14 seconds that matches the lyrics audio length
Define the sound track prompt with your desired text
>>> melody_prompt = 'modern and forward-looking, with a blend of electronic and acoustic elements'Generate the sound track using the
generatefunction from the AudioCraft library>>> audio_array = model.generate([melody_prompt], progress=True)Export the generated soundtrack to a file. Replace
melody-trackwith your desired filename>>> audio_write('melody-track', audio_array[0].cpu(), model.sample_rate)Close the Python console
>>> exit ()List files in your working directory
$ lsVerify that a new
melody-track.wavfile is available
Mix the Generated Lyrics and the Sound Track
When you generate and export the necessary audio files to your directory, use ffmpeg to combine the lyrics with your sound to create a single output file as described below.
Using
ffmpeg, normalize the lyrics audio file to a standard volume to match your soundtrack$ ffmpeg -i lyrics.wav -filter:a loudnorm lyrics_norm.wavNormalize the soundtrack file volume
$ ffmpeg -i melody.wav -filter:a loudnorm melody_norm.wavMix the normalized audio inputs to create a single stereo output file
$ ffmpeg -i melody_norm.wav -i lyrics_norm.wav -filter_complex "[0:a][1:a]amerge=inputs=2,pan=stereo|c0<c0+c1+c2+c3|c1<c0+c1+c2+c3[a]" -map "[a]" output.mp3When successful, verify that a new
output.mp3file is available in your working directoryDeactivate the Python virtual environment
$ deactivate
Download the Generated Music File
To download a copy of your generated music file to your computer, use a secure file transfer protocol such as SFTP, FTP, Rsync, or SCP. In this section, use Secure Copy (SCP) to download the mixed music file to your computer as described below.
In a new terminal window, use scp to download the output.mp3 file from your user home directory to your computer's working directory
$ scp example-user@SERVER-IP:~/output.mp3 .When the download is complete, find the file in your computer files, and open it using a media application such as VLC to listen to the generated music
Conclusion
In this article, you generated AI music on a Vultr Cloud GPU server. Depending on your use case, you can change the lyrics and soundtrack prompts to match your needs. The music generation process takes a few minutes to complete, for more information about the generation tools, visit the following documentation pages.
No comments yet.