
Extract Tables from Images on Vultr Cloud GPU
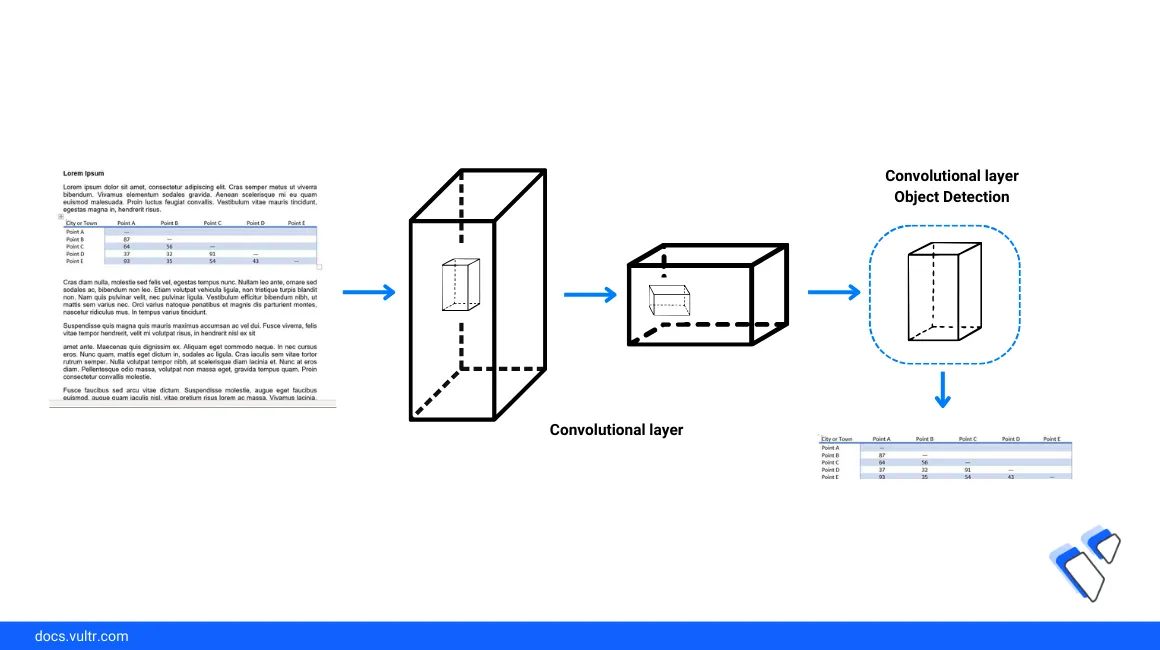
Introduction
Tables are commonly used to represent structured data in print and display documents. Manually detecting, replicating, and recreating tables from graphical files is time-consuming and resource-intensive. However, by leveraging Machine Learning (ML) packages such as YOLO, you can automate table detection and extraction process by utilizing the latest deep learning algorithms.
This article describes how to extract tables from Images using the YOLO package on a Vultr Cloud GPU server.
Prerequisites
Before you start:
- Deploy a Ubuntu 22.04 A100 Cloud GPU server.
- Access the server using SSH as a non-root user with sudo rights.
- Update the server.
- Install JupyterLab.
Set Up the Table Detection Model
Follow the steps below to perform table detection to generate the possible data tables with bounding boxes from an existing image or scanned document. To enable the model processese, install all necessary dependency packages and import a sample image in a new Jupyter Notebook session.
Click Notebook within the JupyterLab interface and select Python3 to create a new Kernel file.
In a new code cell, install the required deep-learning dependency packages.
pythonpip install --ignore-installed ultralyticsplus==0.0.28 ultralytics==8.0.43 "paddleocr>=2.0.1" PyMuPDF==1.21.1 paddlepaddle==2.6.0 "numpy<1.24"
The above command installs the
ultralyticsplus,ultralytics, andpaddleocrpackages on your server to activate the YOLO (You Only Look Once) real-time object detection algorithm. Below is the task performed by each dependency package:ultralytics: Installs the latest YOLOv8 version.ultralyticsplus: Imports Hugging Face utilities for use with the Ultralytics/YOLOv8 package.PaddleOCR: Recognizes and extracts text from available images and documents.paddlepaddle: Enables the parallel distributed deep learning framework.PyMuPDFandnumpy: Enable additional PaddleOCR recognition functionalities.
Press Shift + Enter to run the notebook cell.
Import all necessary libraries from the dependency packages.
pythonfrom ultralyticsplus import YOLO, render_result from paddleocr import PPStructure from PIL.Image import open import pandas as pd import numpy as np import requests
Define new image variables and import a sample image that contains table data. Replace the
image_urlvalue with your source image URL.pythonimage_url = 'https://docs.vultr.com/public/doc-assets/1766/91ba4e6c2f211b77.png' image_data = requests.get(image_url, stream=True, headers={'User-agent': 'vultr-demo'}).raw img = open(image_data)
The above code imports a sample research screenshot image from a public URL with a
vultr-demoHTTP header value. To use local image files, replace the source image URL value with your directory path and theimage_datadirective withimage_data = requests.get(image_url, stream=True).raw.View the loaded image.
pythondisplay(img)
Based on your source image, verify that the image correctly loads in your session and ready for detection.

Load the YOLO table detection model.
pythonmodel = YOLO('keremberke/yolov8s-table-extraction')
To improve the table detection process, modify the YOLO model parameters (such as confidence, threshold, and IOU threshold) to modify the performance and processing time.
Perform table detection and display the detected table data results.
pythonresults = model.predict(img) render = render_result(model=model, image=img, result=results[0]) render.show()
Based on the imported image structure, the model detection result displays with a rectangular boundary box on the target table data.

Extract the Table Contents to CSV Files
Follow the steps below to extract detected table contents generated with the YOLO model to a supported spreadsheet format such as .csv in a standalone file for storage on your server.
Load the
PPOCRmodel to identify your table content language. Replace the lang value with your target data language code. For example,enfor English.pythontable_engine = PPStructure(lang="en")
Generate the bounding boxes in form of
xandycoordinators for detected top-left and bottom-right points.pythonboxes = results[0].boxes.xyxy
Crop the table images from the original document and pass them to the OCR engine to extract a standalone
.csvfile using aforloop.pythonfor i, box in enumerate(boxes): crop_img = img.crop([i.item() for i in box]) res = table_engine(np.array(crop_img)) df = pd.read_html(res[0]["res"]["html"])[0] df.to_csv(f"table{i}.csv", index=False)
The above
forloop crops all detected tables from your base image and creates a new file based on theivariable value such astable0.csv.View the generated
.csvfile contents within your notebook session.pythonpd.read_csv("table0.csv")
Based on your input image, the extracted table contents should display in your session. Replace
table0.csvwith your actual generated filename. For example, additional files generated by the OCR engine follow a sequential file naming scheme such astable1.csv, andtable2.csv.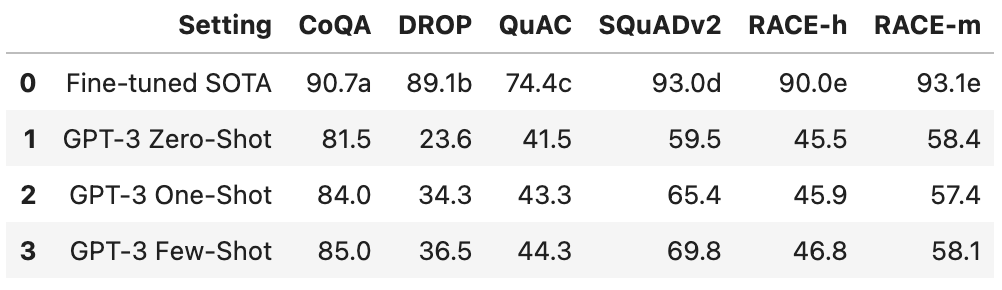
Right-click the generated
.csvfiles on your Jupyter Notebook navigation bar and select download to save a copy of the file.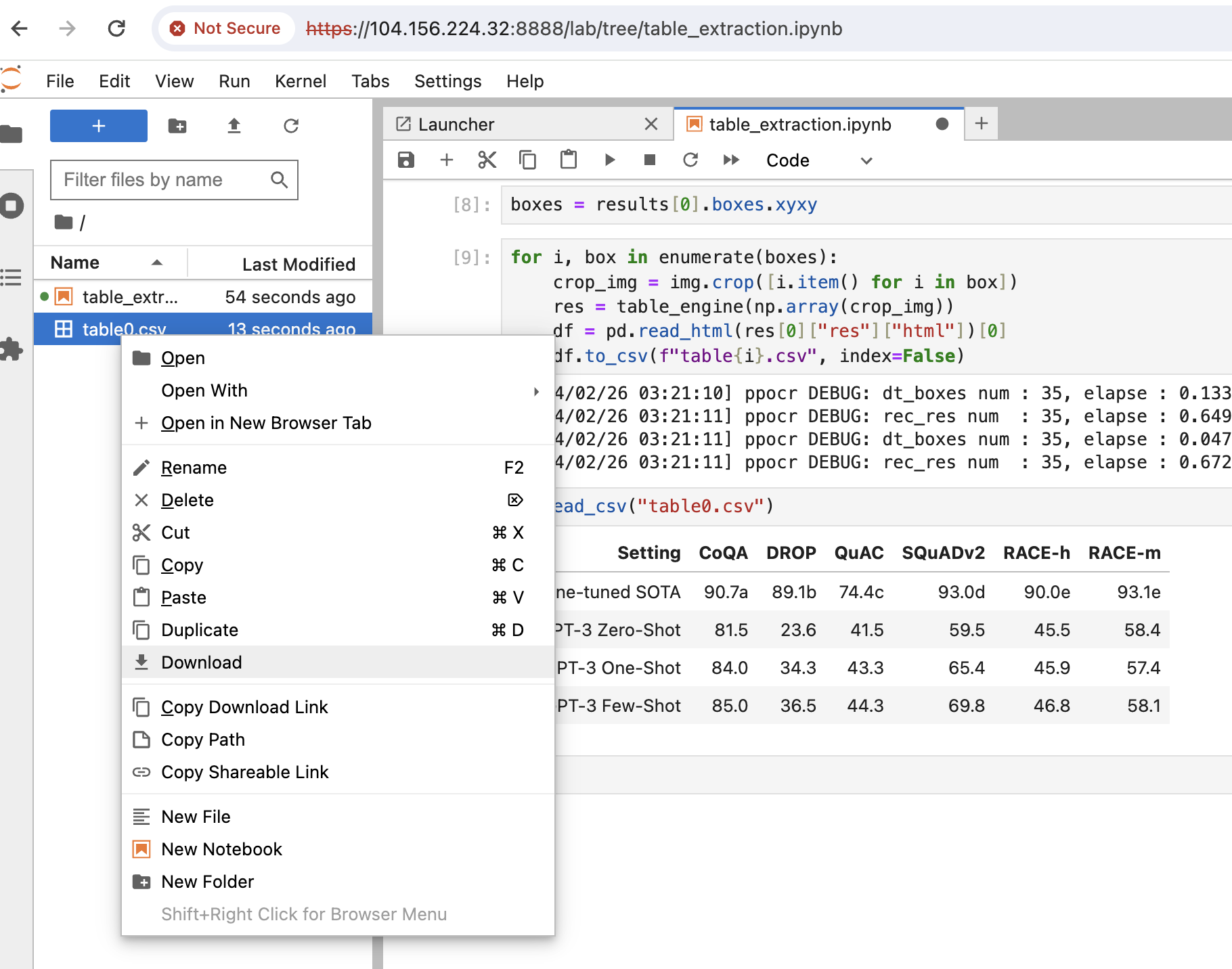
Conclusion
You have extracted table data from images using the YOLO and PPOCR computer vision models on a Vultr Cloud GPU server. When integrated with the latest model data, the application can extract tables from large data files, scanned documents, and image-based documents. For more information about the model parameters, visit the PaddleOCR documentation.