
How to Automatically Back Up PostgreSQL Databases with Object Storage
Introduction
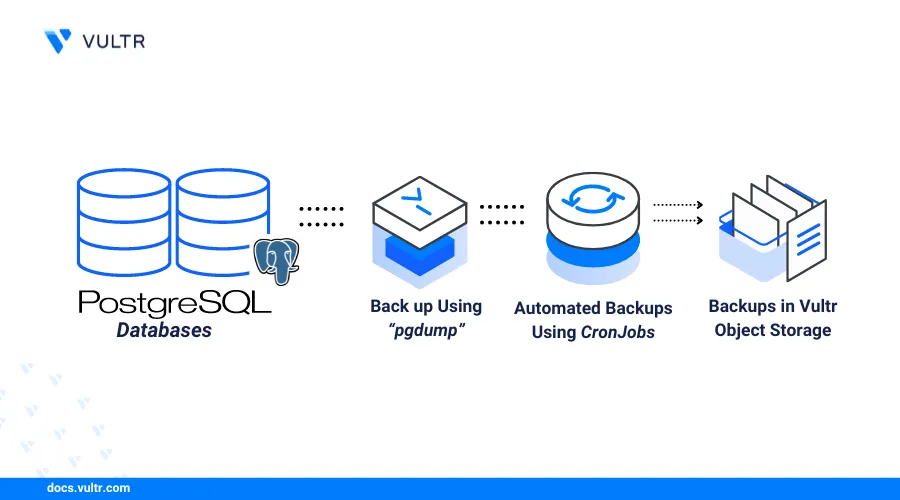
PostgreSQL databases require timely backups to recover data and secure records in case of database server failures. Cloud storage solutions such as object storage decentralize PostgreSQL database backups to enable smooth data recoveries in case the original database or server fails.
This article explains how to automatically back up PostgreSQL databases with object storage using the pg_dump and the Cron utilities. You will create and schedule weekly database backup operations to ensure that the latest backups are readily available for recovery and use in other tasks.
Prerequisites
Before you begin:
- Deploy Vultr Block Storage instance and copy your Hostname, Secret, and Access keys.
- Deploy a Vultr Debian instance to use as the automation workstation.
- Access the server using SSH and log in as a non-root user with sudo privileges.
- Update the server.
- Install the PostgreSQL server.
A Debian server is used as the automation system for testing purposes in this article. Ensure to use your existing PostgreSQL database server to automate the database backup operations with Vultr Object Storage.
Set Up Vultr Object Storage
Vultr Object Storage is an S3-compatible cloud storage service that supports data transfer tools such as Cyberduck, S3 Browser, and S3cmd to securely upload and store files. Follow the steps below to set up Vultr Object Storage, create a new bucket, and upload test data files using S3cmd.
Update the server's package index.
console$ sudo apt update
Install s3cmd.
console$ sudo apt install s3cmd
Run s3cmd with the
--configureoption to set up Vultr Object Storage as the default provider.console$ s3cmd --configure
Output:
Enter new values or accept defaults in brackets with Enter. Refer to user manual for detailed description of all options. Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables. Access Key:Paste your Vultr Object Storage access key and press Enter to save the new access key.
Paste your secret key and press Enter.
Secret Key:Press Enter to use the default S3 region
US.Default Region [US]:Enter your Vultr Object Storage hostname in the S3 Endpoint prompt. For example,
ew1.vultrobjects.com.S3 Endpoint [s3.amazonaws.com]:Enter the bucket DNS-style template to use with Vultr Object Storage. For example
%(bucket)s.ewr1.vultrobjects.com.DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]:Enter a strong encryption password to protect your Vultr Object Storage connection from unauthorized users on the server.
Encryption password is used to protect your files from reading by unauthorized persons while in transfer to S3 Encryption password:Press Enter to accept the default GPG program path
/usr/bin/gpgto encrypt objects during transfer to Vultr Object Storage.Path to GPG program [/usr/bin/gpg]:Press Enter to use the HTTPS protocol with Vultr Object Storage.
Use HTTPS protocol [Yes]:Press Enter to use Vultr Object Storage without an HTTP Proxy connection. If your network requires a proxy, enter the server URL to use with s3cmd.
HTTP Proxy server name:Review your object transfer configuration and enter
Yto test access to your Vultr Object Storage.New settings: Access Key: aaaaaa Secret Key: aaaaaasss Default Region: US S3 Endpoint: ewr1.vultrobjects.com DNS-style bucket+hostname:port template for accessing a bucket: %(bucket)s.ewr1.vultrobjects.com Encryption password: secure-password Path to GPG program: Use HTTPS protocol: True HTTP Proxy server name: HTTP Proxy server port: 0 Test access with supplied credentials? [Y/n]Press Y then Enter to save the s3cmd configuration when the test is successful.
Please wait, attempting to list all buckets... Success. Your access key and secret key worked fine :-) Now verifying that encryption works... Success. Encryption and decryption worked fine :-) Save settings? [y/N]View the s3cmd configuration file
.s3cfgin your user home directory to verify your Vultr Object Storage connection information.console$ cat /home/user/.s3cfg
Create a new Vultr Object Storage bucket to store your PostgreSQL backup files using s3cmd. For example
postgreSQL-backups.console$ s3cmd mb s3://postgreSQL-backups
Output:
Bucket 's3://postgreSQL-backups/' createdFollow the Vultr Object Storage naming requirements when creating new buckets to avoid any errors. Use lowercase, unique and only allowed characters to successfully create a new bucket.
Create a new sample text file
PostgreSQL-test.txt.console$ touch PostgreSQL-test.txt
Transfer the text file to your Vultr Object Storage bucket.
console$ s3cmd put PostgreSQL-test.txt s3://PostgreSQL-backups/
List all objects in the bucket and verify that s3cmd correctly uploads files to your Vultr Object Storage.
console$ s3cmd ls s3://PostgreSQL-backups
Output:
2024-08-07 16:45 0 s3://PostgreSQL-backups/PostgreSQL-test.txt
Backup PostgreSQL Databases Using pg_dump
pg_dump is pre-installed with the PostgreSQL database server package and enables the backup of PostgreSQL databases on your server. It works by creating a set of reproducable SQL statements that store the original database contents and state. Follow the steps below to back up your PostgreSQL databases using the pg_dump utility.
Create a new directory to store the PostgreSQL backup files. For example,
PostgreSQL-backups.console$ mkdir PostgreSQL-backups
Switch to the directory.
console$ cd PostgreSQL-backups
Create a new sample PostgreSQL database to backup. For example,
exampledb.console$ sudo -u postgres createdb exampledb
Back up a single
exampledbdatabase to a file such asexampledb.sql.console$ pg_dump -U postgres -d exampledb -F p -f exampledb.sql
Long list the directory files and verify that a new
exampledb.sqlfile is created.console$ ls -l
Output:
total 4 -rw-r--r-- 1 user user 1294 Apr 7 19:39 exampledb.sqlBack up all PostgreSQL databases on the server.
console$ pg_dumpall -U postgres -f fullPostgreSQLbackup.sql
Back up all PostgreSQL users, roles and database permissions on the server.
$ pg_dumpall -U postgres --globals-only -f db-server-users.sqlList all files to verify all backup files available in your working directory.
console$ ls -l
Output:
total 2472 -rw-r--r-- 1 user user 34567 Apr 7 19:41 db-server-users.sql -rw-r--r-- 1 user user 1294 Apr 7 19:39 exampledb.sql -rw-r--r-- 1 user user 2486007 Apr 7 19:40 fullPostgreSQLbackup.sql
Upload PostgreSQL Database Backups to Vultr Object Storage
Create a new directory to organize and store your database backup files. For example,
test-backups.console$ mkdir test-backups
Move all
.sqlPostgreSQL backup files to the directory for upload to your Vultr Object Storage bucket.console$ mv *.sql test-backups/
Upload all files in the backup files directory to your object storage bucket.
console$ s3cmd put -r test-backups/ s3://PostgreSQL-backups/test-backups/
Output:
upload: 'test-backups/db-server-users.sql' -> 's3://PostgreSQL-backups/test-backups/db-server-users.sql' [1 of 4] 34567 of 34567 100% in 1s 24.85 KB/s done upload: 'test-backups/exampledb.sql' -> 's3://PostgreSQL-backups/test-backups/exampledb.sql' [2 of 4] 1294 of 1294 100% in 0s 5.71 KB/s done upload: 'test-backups/fullPostgreSQLbackup.sql' -> 's3://PostgreSQL-backups/test-backups/fullPostgreSQLbackup.sql' [3 of 4] 2486007 of 2486007 100% in 1s 1693.74 KB/s doneList your Vultr Object Storage bucket contents and verify that the database backup files are available.
console$ s3cmd ls s3://PostgreSQL-backups/test-backups/
Output:
2024-08-07 19:52 34567 s3://PostgreSQL-backups/test-backups/db-server-users.sql 2024-08-07 19:52 1294 s3://PostgreSQL-backups/test-backups/exampledb.sql 2024-08-07 19:52 2486007 s3://PostgreSQL-backups/test-backups/fullPostgreSQLbackup.sqlCreate a new data directory such as
w1-08-2024to organize your backups by date.console$ mkdir w1-08-2024
Copy all existing PostgreSQL backup files from
test-backupsto the new directory.console$ mv test-backups/*.sql w1-08-2024
Upload the backup directory to your object storage bucket.
console$ s3cmd put -r w1-08-2024/ s3://PostgreSQL-backups/w1-08-2024/
View the object storage bucket data and verify that the new directory files are available.
console$ s3cmd ls s3://PostgreSQL-backups/w1-08-2024/
Output:
2024-08-07 19:56 34567 s3://PostgreSQL-backups/w1-08-2024/db-server-users.sql 2024-08-07 19:56 1294 s3://PostgreSQL-backups/w1-08-2024/exampledb.sql 2024-08-07 19:56 2486007 s3://PostgreSQL-backups/w1-08-2024/fullPostgreSQLbackup.sql
Automate the PostgreSQL Database Backup and File Transfer Processes Using Cron
Follow the steps below to create a Bash script to automate the PostgreSQL database backup operations you performed earlier and use the Cron utility to run the script on a schedule.
Create a new bash script
PostgreSQL-backup-script.shusing a text editor such as Nano.console$ nano PostgreSQL-backup-script.sh
Add the following contents to the file.
bash#!/bin/bash backup_date=$(date +'%U-%m') backup_directory="database_backup_$backup_date" mkdir -p "$backup_directory" pg_dumpall -U postgres -f fullPostgreSQLbackup.sql > "$backup_directory/full_backup_$backup_date.sql" s3cmd put --recursive "$backup_directory/" s3://PostgreSQL-backups/"$backup_directory/" rm -rf "$backup_directory" echo "Transfer Complete!!! The Full PostgreSQL database backup is now available in the Vultr Object Storage bucket."
Save and close the file.
The above Bash script backs up the full PostgreSQL database and stores the resultant file to a dedicated backup directory and uses s3cmd to upload the latest backup file to the target Vultr Object Storage bucket.
Run the database backup script using Bash.
console$ bash PostgreSQL-backup-script.sh
Monitor the script process and verify that the file upload completes successfully with the following output:
2486007 of 2486007 100% in 1s 1357.94 KB/s done Transfer Complete!!! The latest PostgreSQL database backup is available in your Vultr Object Storage bucket.List your Vultr Object Storage bucket contents and verify that a new backups directory is available.
console$ s3cmd ls s3://postgreSQL-backups/
Output:
DIR s3://postgreSQL-backups/database_backup_14_08/Open the Crontab editor to create a new Cron job to automate the back up script.
console$ crontab -e
Add the following directive at the end of the file to run the PostgreSQL backup script once every week at
4:00 AM.sh0 4 * * 0 /home/user/PostgreSQL-backups/PostgreSQL-backup-script.sh >> /home/user/PostgreSQL-backups/automatic-backups.log 2>&1
Save and close the file.
The above Cron job runs the PostgreSQL database backup script once every 7 days on Sunday at 4:00 AM based on the expression
0 4 * * 0:0: Represents the minute (0 to 59).4: Represents the hour (0 to 23).*: Sets the day of the month (1-31). The value*runs the command every day or week.*: Sets the month in a calendar year (1 to 12). The value*runs the command every month.0: Sets the day of the week (0-6). The value0represents Sunday.
Cron also logs all command outputs to the file
automatic-backups.logusing>> /home/user/PostgreSQLbackups/automatic-backups.log 2>&1.Create the PostgreSQL database backup log file referenced in Cron.
console$ touch automatic-backups.log
Long list your PostgreSQL backup directory contents and verify that your non-root user owns all directory files.
console$ ls -l
Output:
total 12 -rw-r--r-- 1 user user 0 Apr 7 20:19 automatic-backups.log -rw-r--r-- 1 user user 458 Apr 7 20:09 PostgreSQL-backup-script.sh drwxr-xr-x 2 user user 4096 Apr 7 19:55 test-backups drwxr-xr-x 2 user user 4096 Apr 7 19:55 w1-08-2024Run the full Cron job command to verify if it works correctly.
console$ bash /home/user/PostgreSQL-backups/PostgreSQL-backup-script.sh >> /home/user/PostgreSQL-backups/automatic-backups.log 2>&1
View the log file to verify the available script logging information.
console$ cat /home/user/PostgreSQL-backups/automatic-backups.log
Output:
upload: 'database_backup_14_08/full_backup_14_08.sql' -> 's3://PostgreSQL-backups/database_backup_14_08/full_backup_14_08.sql' [1 of 1] 2486007 of 2486007 100% in 34s 71.11 KB/s done Transfer Complete!!! The latest PostgreSQL database backup is now available in the Vultr Object Storage bucket.
Conclusion
You have enabled automatic PostgreSQL database backups with Vultr Object Storage. You can continuously back up your PostgreSQL databases to ensure that you can recover specific contents in case the database server fails. In addition, you can use automatic backups with high-traffic web applications or large databases that require consistent monitoring to recover your PostgreSQL database or migrate it to a new server.