
How to Build Disaggregated Inference with NVIDIA Dynamo
NVIDIA Dynamo is an open-source inference framework for deploying large-scale generative AI models across multi-node, multi-GPU environments. Disaggregated serving architecture separates prompt processing (prefill) and token generation (decode) phases across different GPU workers, enabling independent scaling and optimization of each phase based on their distinct computational characteristics.
This guide covers building disaggregated inference deployments with NVIDIA Dynamo using AIConfigurator for optimal configuration discovery, deploying on Kubernetes with RDMA, and validating performance. Disaggregated architecture can achieve up to 1.7x throughput improvement over aggregated serving for large models (32B+) with long input contexts. For smaller models, AIConfigurator automatically determines when aggregated serving is more efficient.
Prerequisites
Before you begin, ensure you have one of the following environments:
For Kubernetes Deployment:
- Kubernetes cluster with NVIDIA GPU nodes and RDMA device plugin installed.
kubectlconfigured to access your cluster.- RDMA-capable network (InfiniBand or RoCE).
- NVIDIA Dynamo platform installed on your cluster.
For Standalone Instance Deployment:
- Linux server with NVIDIA GPUs and NVIDIA Container Toolkit configured.
- 2+ GPUs for disaggregated serving.
- Docker Engine and Docker Compose.
- Non-root user with sudo privileges.
Common Requirements:
- Python 3.10+ for running AIConfigurator.
- Hugging Face account with access token for gated models.
Understanding Disaggregated Serving Architecture
Disaggregated serving splits LLM inference into two specialized phases, each optimized for different computational characteristics:
Prefill Phase vs Decode Phase
| Phase | Characteristics | Optimization Focus |
|---|---|---|
| Prefill | Processes entire input prompt in parallel | Memory-bound, benefits from high-bandwidth GPUs, uses low batch sizes (1-4) |
| Decode | Generates tokens sequentially, one at a time | Compute-bound, benefits from high concurrency, uses high batch sizes (256-1024) |
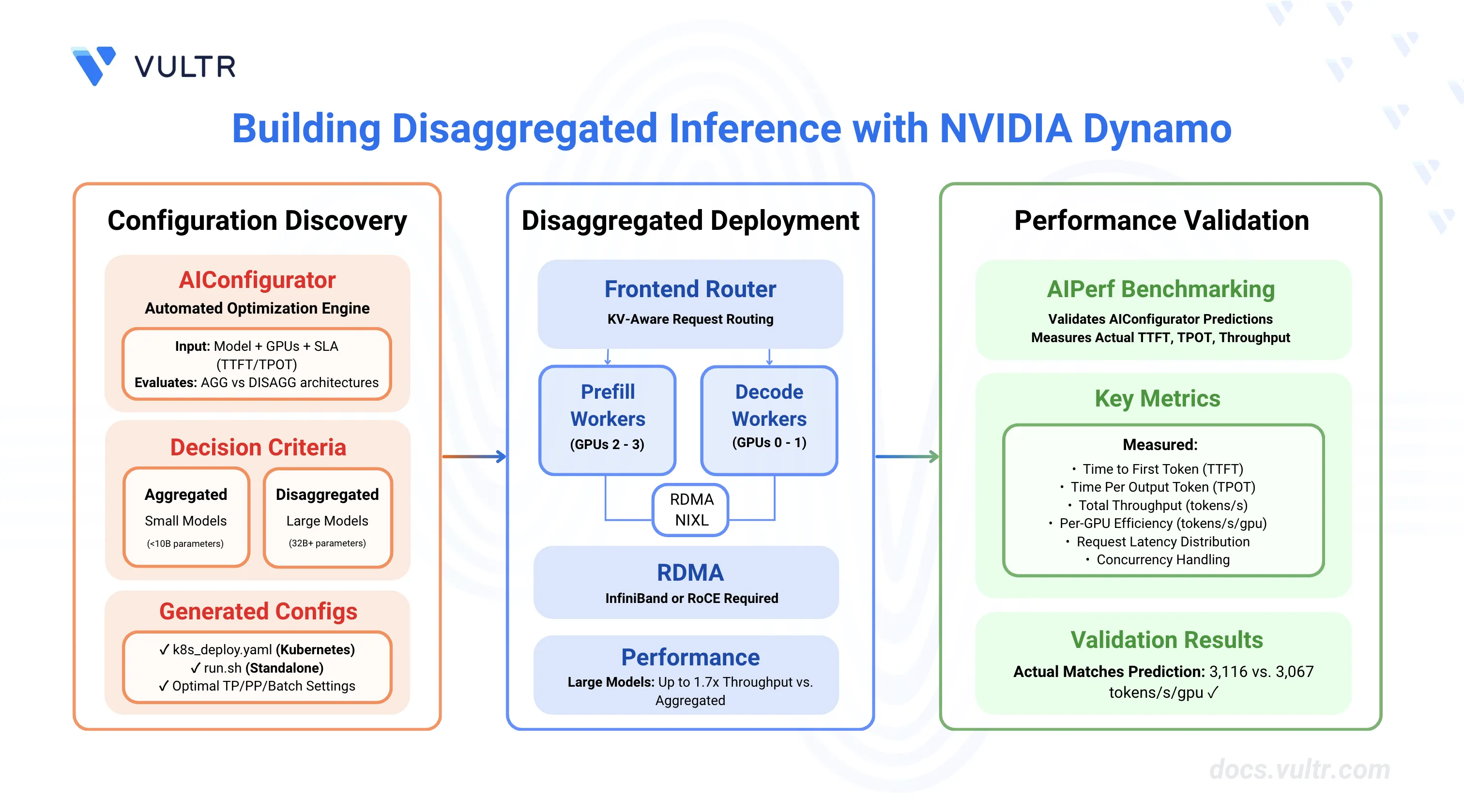
Architecture Components
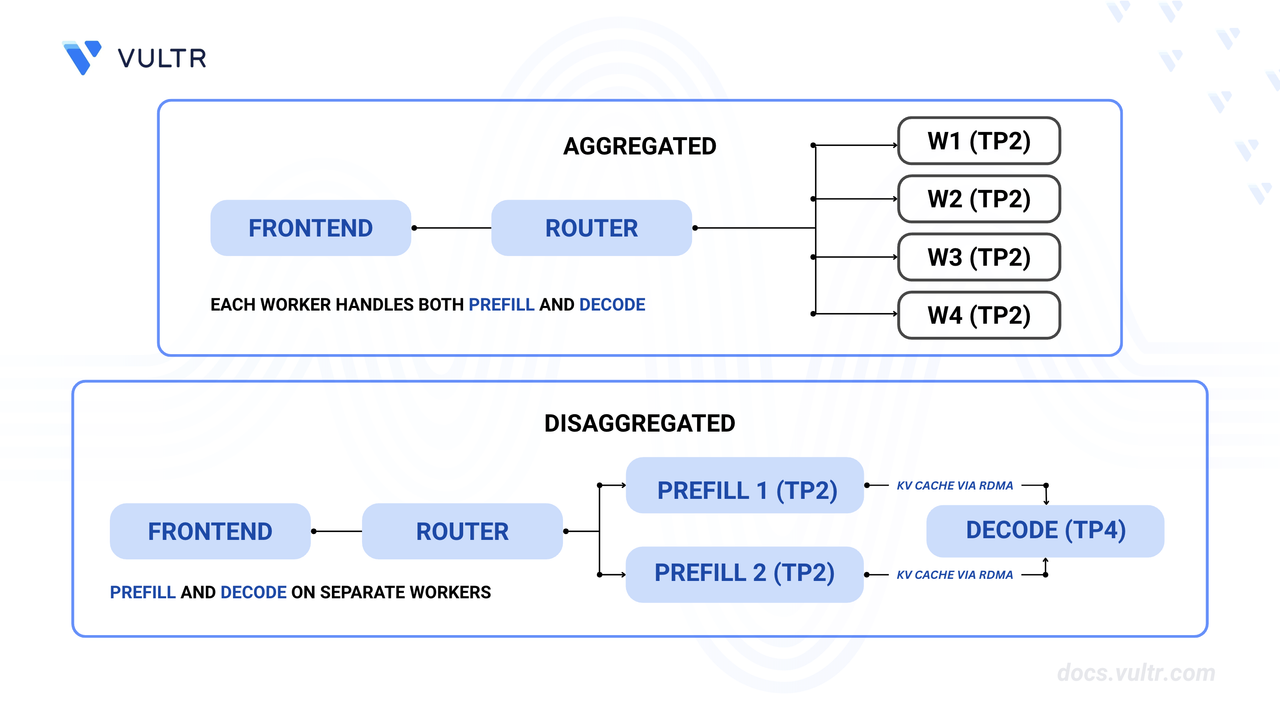
Prefill Workers:
- Process incoming prompts and generate KV cache.
- Run with low batch sizes for optimal TTFT.
- Can use different tensor parallelism (TP) than decode workers.
- Transfer KV cache to decode workers via NIXL.
Decode Workers:
- Receive KV cache from prefill workers.
- Generate output tokens sequentially.
- Handle high concurrency with large batch sizes.
- Optimized for sustained token throughput
Request Routing:
- Frontend routes requests to available prefill workers.
- PrefillRouter selects prefill workers based on KV cache affinity.
- After prefill, decode workers receive KV cache and continue generation.
- NIXL enables GPU-to-GPU KV cache transfer with RDMA.
When to Use Disaggregated Serving
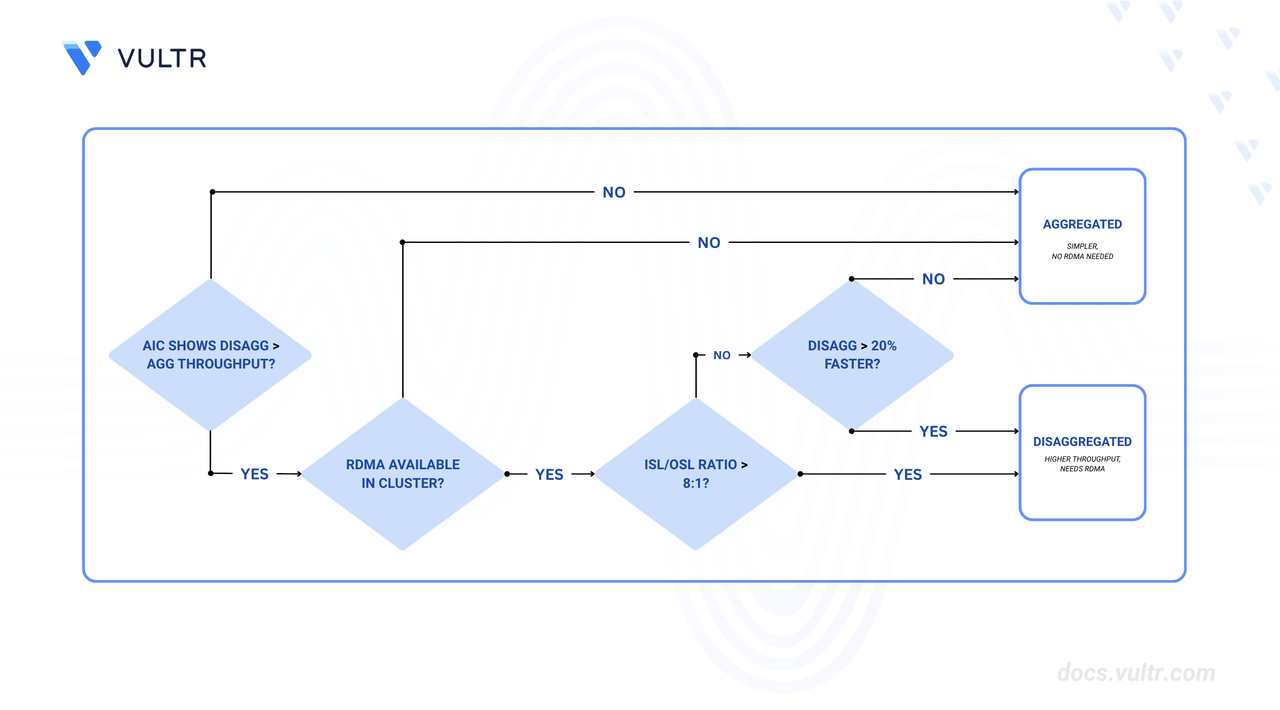
Use Disaggregated Serving When:
- Model size is large (32B+ parameters) - smaller models have lower KV cache transfer overhead that doesn't justify phase separation.
- Input sequence length (ISL) significantly exceeds output sequence length (OSL) - typically ISL > 4000 tokens.
- Workload requires independent scaling of prefill and decode capacity.
- RDMA-capable network infrastructure is available (critical requirement).
- Maximizing per-GPU throughput is the primary objective.
Use Aggregated Serving When:
- Model size is small (<10B parameters) - KV cache transfer overhead outweighs benefits.
- Balanced ISL/OSL ratios (between 2:1 and 10:1).
- Simpler deployment with lower operational complexity is preferred.
- RDMA infrastructure is not available.
- Strict latency SLAs require minimal inter-worker communication overhead.
Performance Benefits (for Large Models):
- Up to 1.7x higher throughput compared to aggregated serving for large models with long-context workloads.
- Better GPU utilization through phase-specific optimization.
- Independent scaling of prefill and decode resources based on workload patterns.
Install and Configure AIConfigurator
AIConfigurator is a performance optimization tool that automatically determines the optimal configuration for deploying LLMs with Dynamo by evaluating both aggregated and disaggregated architectures.
Create a Python 3 virtual environment.
console$ python3 -m venv aiconfigurator_env
Activate the virtual environment.
console$ source aiconfigurator_env/bin/activate
Install AIConfigurator using pip.
console$ pip3 install aiconfigurator
Verify the installation.
console$ aiconfigurator version
The output displays the installed version.
View available parameters and help documentation.
console$ aiconfigurator cli default --help
Understanding AIConfigurator Parameters
AIConfigurator requires the following key parameters:
| Parameter | Description | Example |
|---|---|---|
--hf_id |
HuggingFace model ID or local path | nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1 |
--system |
GPU system type | h200_sxm, h100_sxm, a100_sxm |
--total_gpus |
Number of GPUs available for deployment | 4 |
--isl / --osl |
Input/Output sequence lengths in tokens | 4000 / 500 |
--ttft / --tpot |
SLA targets - Time To First Token (ms) and Time Per Output Token (ms) | 600 / 16.67 |
--backend |
Inference backend | vllm, trtllm, sglang |
--backend_version |
Backend version | 0.12.0 (for vLLM) |
--save_dir |
Directory to save generated configs | ./results_vllm |
How AIConfigurator Works:
- Evaluates all possible configurations (tensor/pipeline parallelism combinations)
- Simulates performance for both aggregated and disaggregated architectures
- Filters configurations that meet SLA targets (TTFT, TPOT)
- Ranks results by per-GPU throughput (tokens/s/gpu)
- Automatically selects the best architecture (agg or disagg) based on actual performance
- Generates deployment manifests for top-ranked configurations
AIConfigurator considers factors like model size, KV cache transfer overhead, and GPU utilization to determine whether disaggregated serving will outperform aggregated for your specific workload.
Find Optimal Disaggregated Configuration
Use AIConfigurator to discover the best configuration for your model and hardware.
Run AIConfigurator with your model and system specifications.
console$ aiconfigurator cli default \ --hf_id nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1 \ --system h200_sxm \ --total_gpus 4 \ --isl 4000 \ --osl 500 \ --ttft 600 \ --tpot 16.67 \ --backend vllm \ --backend_version 0.12.0 \ --save_dir ./results_vllm
The command evaluates all possible configurations for 4× H200 GPUs with the specified model and SLA targets, generating deployment manifests in the
./results_vllmdirectory.Review the AIConfigurator output summary.
******************************************************************************** * Dynamo aiconfigurator Final Results * ******************************************************************************** ---------------------------------------------------------------------------- Input Configuration & SLA Target: Model: nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1 (is_moe: False) Total GPUs: 4 Best Experiment Chosen: agg at 3785.20 tokens/s/gpu (disagg 0.81x better) ---------------------------------------------------------------------------- Overall Best Configuration: - Best Throughput: 15,140.82 tokens/s - Per-GPU Throughput: 3785.20 tokens/s/gpu - Per-User Throughput: 61.41 tokens/s/user - TTFT: 395.88ms - TPOT: 16.28ms - Request Latency: 8521.26ms ----------------------------------------------------------------------------The summary shows that for this 4B model, aggregated serving performs better than disaggregated (3785.20 vs 3067.51 tokens/s/gpu). This is expected for smaller models where the overhead of KV cache transfer outweighs the benefits of phase separation. Disaggregated serving becomes advantageous with larger models (32B+) and longer context lengths.
Review the detailed configuration comparison.
agg Top Configurations: (Sorted by tokens/s/gpu) +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+----------+----+ | Rank | tokens/s/gpu | tokens/s/user | TTFT | request_latency | concurrency | total_gpus (used) | replicas | parallel | bs | +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+----------+----+ | 1 | 3785.20 | 61.41 | 395.88 | 8521.26 | 256 (=64x4) | 4 (4=4x1) | 4 | tp1pp1 | 64 | | 2 | 3036.90 | 65.06 | 331.10 | 8000.51 | 192 (=96x2) | 4 (4=2x2) | 2 | tp2pp1 | 96 | | 3 | 2305.76 | 65.36 | 249.55 | 7883.93 | 144 (=144x1) | 4 (4=1x4) | 1 | tp4pp1 | 144| +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+----------+----+ disagg Top Configurations: (Sorted by tokens/s/gpu) +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+-------------+-------------+ | Rank | tokens/s/gpu | tokens/s/user | TTFT | request_latency | concurrency | total_gpus (used) | replicas | (p)parallel | (d)parallel | +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+-------------+-------------+ | 1 | 3067.51 | 63.99 | 111.33 | 7909.20 | 208 (=104x2) | 4 (4=2x2) | 2 | tp1pp1 | tp1pp1 | | 2 | 3011.39 | 62.82 | 111.33 | 8054.41 | 208 (=208x1) | 4 (4=1x4) | 1 | tp1pp1 | tp2pp1 | +------+--------------+---------------+--------+-----------------+--------------+-------------------+----------+-------------+-------------+Understanding the Output:
- tokens/s/gpu: Overall throughput efficiency - higher is better (agg: 3785.20 vs disagg: 3067.51 = agg is 23% faster)
- tokens/s/user: Per-request generation speed (inverse of TPOT)
- TTFT: Predicted time to first token (395.88ms for agg, 111.33ms for disagg prefill)
- concurrency: Total concurrent requests (e.g.,
256 (=64x4)= batch size 64 × 4 replicas) - parallel: Tensor/pipeline parallelism (tp=tensor parallel, pp=pipeline parallel)
- Result: For this 4B model, aggregated serving is more efficient due to lower overhead
Model Size Matters: Disaggregated serving becomes advantageous with larger models (32B+) where the benefits of phase-specific optimization outweigh KV cache transfer overhead. For smaller models like this 4B example, aggregated serving is more efficient.NoteExamine the generated directory structure.
console$ tree results_vllm/
results_vllm/ └── nvidia/ └── Llama-3.1-Nemotron-Nano-4B-v1.1_isl4000_osl500_ttft600_tpot16_472853/ ├── agg/ │ ├── best_config_topn.csv │ ├── config.yaml │ ├── pareto.csv │ ├── top1/ │ │ ├── generator_config.yaml │ │ ├── k8s_deploy.yaml │ │ └── run_0.sh │ ├── top2/ │ │ └── ... │ └── top3/ │ └── ... ├── disagg/ │ ├── best_config_topn.csv │ ├── config.yaml │ ├── pareto.csv │ ├── top1/ │ │ ├── generator_config.yaml │ │ ├── k8s_deploy.yaml │ │ └── run_0.sh │ └── top2/ │ └── ... └── pareto_frontier.pngThe results are organized by model name and experiment parameters. While aggregated serving is optimal for this 4B model, the following sections demonstrate disaggregated deployment for learning purposes and larger model scenarios.
Deploy on Kubernetes
Kubernetes deployment provides the infrastructure for disaggregated serving with RDMA-accelerated KV cache transfer.
Install NVIDIA Dynamo Platform
Before deploying disaggregated workloads, install the NVIDIA Dynamo platform on your Kubernetes cluster. Follow the How to Optimize GPU Resource Planning with NVIDIA Dynamo guide to:
- Install the Dynamo Operator
- Configure GPU resource management
- Set up the DynamoGraphDeployment CRD
- Verify cluster readiness for Dynamo workloads
Prepare Kubernetes Environment
Set your Kubernetes namespace as an environment variable.
console$ export LLM_NAMESPACE=YOUR_NAMESPACE
Replace
YOUR_NAMESPACEwith the namespace where you want to deploy Dynamo workloads.Create the namespace.
console$ kubectl create namespace $LLM_NAMESPACE
Export your Hugging Face token.
console$ export HF_TOKEN=YOUR_HF_TOKEN
Replace
YOUR_HF_TOKENwith your Hugging Face access token.Create a Hugging Face token secret for accessing gated models.
console$ kubectl create secret generic hf-token-secret \ --namespace $LLM_NAMESPACE \ --from-literal=HF_TOKEN="$HF_TOKEN"
Create a persistent volume claim for caching model weights.
console$ cat << EOF > model-cache-pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-cache namespace: $LLM_NAMESPACE spec: accessModes: - ReadWriteMany resources: requests: storage: 100Gi EOF
This PVC usesNoteReadWriteMany(RWX) access mode, which allows multiple pods to mount the volume simultaneously for shared model caching. Ensure your cluster has a StorageClass that supports RWX access mode (such as NFS, CephFS, or cloud-provider RWX storage). Verify available StorageClasses:console$ kubectl get storageclass
Apply the PVC configuration.
console$ kubectl apply -f model-cache-pvc.yaml
Verify the RDMA device plugin is running.
console$ kubectl get pods -n kube-system | grep rdma
The output should show RDMA device plugin pods running on GPU nodes. If not installed, follow the Mellanox RDMA device plugin installation guide.
Verify RDMA resources are available on your nodes.
console$ kubectl get node NODE-NAME -o json | jq '.status.allocatable'
Replace
NODE-NAMEwith your GPU node name. The output should showrdma/hca_shared_devicesresources:{ ...... "rdma/hca_shared_devices": "1k", ...... }The
rdma/hca_shared_devices: "1k"entry confirms RDMA resources are available. If this resource is missing, verify the RDMA device plugin DaemonSet configuration and node labels.
Deploy Using Generated Manifests
Review the generated disaggregated deployment manifest.
console$ cat results_vllm/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1_isl4000_osl500_ttft600_tpot16_*/disagg/top1/k8s_deploy.yaml
The file contains a
DynamoGraphDeploymentcustom resource with frontend, prefill workers, and decode workers configured according to AIConfigurator's recommendations.Create the complete deployment manifest with RDMA configuration.
console$ cat << EOF > dynamo-disagg-deployment.yaml apiVersion: nvidia.com/v1alpha1 kind: DynamoGraphDeployment metadata: name: dynamo-disagg namespace: $LLM_NAMESPACE spec: backendFramework: vllm pvcs: - name: model-cache create: false services: Frontend: componentType: frontend replicas: 1 volumeMounts: - name: model-cache mountPoint: /opt/models envs: - name: HF_HOME value: /opt/models extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13 imagePullPolicy: IfNotPresent VLLMPrefillWorker: envFromSecret: hf-token-secret componentType: worker subComponentType: prefill replicas: 2 resources: limits: gpu: "1" sharedMemory: size: 16Gi volumeMounts: - name: model-cache mountPoint: /opt/models envs: - name: HF_HOME value: /opt/models - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uid - name: UCX_TLS value: "rc_x,rc,dc_x,dc,cuda_copy,cuda_ipc" - name: UCX_RNDV_SCHEME value: "get_zcopy" - name: UCX_RNDV_THRESH value: "0" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13 workingDir: /workspace imagePullPolicy: IfNotPresent securityContext: capabilities: add: ["IPC_LOCK"] resources: limits: rdma/hca_shared_devices: "1" requests: rdma/hca_shared_devices: "1" command: ["python3", "-m", "dynamo.vllm"] args: - --model - "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1" - "--tensor-parallel-size" - "1" - "--kv-cache-dtype" - "fp8" - "--max-num-seqs" - "1" - --trust-remote-code - --is-prefill-worker VLLMDecodeWorker: envFromSecret: hf-token-secret componentType: worker subComponentType: decode replicas: 2 resources: limits: gpu: "1" sharedMemory: size: 16Gi volumeMounts: - name: model-cache mountPoint: /opt/models envs: - name: HF_HOME value: /opt/models - name: POD_UID valueFrom: fieldRef: fieldPath: metadata.uid - name: UCX_TLS value: "rc_x,rc,dc_x,dc,cuda_copy,cuda_ipc" - name: UCX_RNDV_SCHEME value: "get_zcopy" - name: UCX_RNDV_THRESH value: "0" extraPodSpec: mainContainer: image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13 workingDir: /workspace imagePullPolicy: IfNotPresent securityContext: capabilities: add: ["IPC_LOCK"] resources: limits: rdma/hca_shared_devices: "1" requests: rdma/hca_shared_devices: "1" command: ["python3", "-m", "dynamo.vllm"] args: - --model - "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1" - "--tensor-parallel-size" - "1" - "--kv-cache-dtype" - "fp8" - "--max-num-seqs" - "1024" - --trust-remote-code - --is-decode-worker EOF
Critical RDMA Configuration:
rdma/hca_shared_devicesresources: Request RDMA resources matching tensor parallelism size (1 for both prefill and decode with TP1)IPC_LOCKcapability: Required for RDMA memory registrationPOD_UIDenvironment variable: Retrieves pod UID from metadata for worker identificationUCX_TLSenvironment variable: Enables RDMA transports (rc_x,dc_xfor InfiniBand)UCX_RNDV_SCHEME=get_zcopy: Enables zero-copy RDMA transfers for maximum performanceUCX_RNDV_THRESH=0: Forces RDMA usage for all message sizes--trust-remote-codeflag: Allows execution of custom model code from Hugging Face- CUDA 13 runtime: Uses
nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0-cuda13for GPU compatibility
Deploy the configuration to Kubernetes.
console$ kubectl apply -f dynamo-disagg-deployment.yaml
Monitor the deployment progress.
console$ kubectl get pods -n $LLM_NAMESPACE -w
Wait for all pods to reach
Runningstatus. This may take several minutes as models are downloaded and loaded.
Verify Kubernetes Deployment
Check pod status and resource allocation.
console$ kubectl get pods -n $LLM_NAMESPACE
The output shows all pods running successfully:
NAME READY STATUS RESTARTS AGE dynamo-disagg-0-frontend-77bn5 1/1 Running 0 2m42s dynamo-disagg-0-vllmdecodeworker-gzgbw 1/1 Running 0 2m42s dynamo-disagg-0-vllmdecodeworker-kn8xz 1/1 Running 0 2m42s dynamo-disagg-0-vllmprefillworker-2b7hm 1/1 Running 0 2m42s dynamo-disagg-0-vllmprefillworker-7p4mq 1/1 Running 0 2m42sVerify RDMA is active by checking worker logs.
console$ kubectl logs -n $LLM_NAMESPACE PREFILL-WORKER-POD | grep -i "UCX\|NIXL"
Replace
PREFILL-WORKER-PODwith your prefill worker pod name from the previous step. The output shows NIXL initialization logs:2026-03-03T22:52:23.152441Z INFO nixl_connector: NIXL is available 2026-03-03T22:52:23.154049Z INFO factory.create_connector: Creating v1 connector with name: NixlConnector and engine_id: e0dc9d5a-80b5-4b06-aeb9-05958f83d6ea (Worker pid=1241) 2026-03-03 22:52:25 NIXL INFO _api.py:363 Backend UCX was instantiated (Worker pid=1241) 2026-03-03 22:52:25 NIXL INFO _api.py:253 Initialized NIXL agent: 93612abb-847f-435f-bd56-73bfc8d5f3d6 2026-03-03T22:52:25.487423Z INFO nixl_connector.register_kv_caches: Registering KV_Caches. use_mla: False, kv_buffer_device: cuda, use_host_buffer: FalseThe key indicators confirm RDMA is working:
- "NIXL is available": NIXL connector initialized successfully
- "Backend UCX was instantiated": UCX backend (RDMA transport) is active
- "Initialized NIXL agent": NIXL agent ready for KV cache transfer
- "Registering KV_Caches": KV cache buffers registered for GPU-to-GPU transfer
Test inference through the frontend service.
console$ kubectl port-forward -n $LLM_NAMESPACE service/dynamo-disagg-frontend 8000:8000
In a separate terminal, send a test request:
console$ curl -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1", "messages": [{"role": "user", "content": "Explain the importance of tensor parallelism in LLM inference."}], "max_tokens": 100 }'
The output displays the model's response in JSON format.
Monitor worker metrics to verify disaggregated flow.
console$ curl -s localhost:8000/metrics | grep dynamo_frontend_requests_total
The output displays the metrics showing successful request processing:
# HELP dynamo_frontend_requests_total Total number of LLM requests processed # TYPE dynamo_frontend_requests_total counter dynamo_frontend_requests_total{endpoint="chat_completions",model="nvidia/llama-3.1-nemotron-nano-4b-v1.1",request_type="unary",status="success"} 1
Deploy on Standalone Instances
For standalone instance deployments (non-Kubernetes), refer to the backend-specific deployment guides that cover disaggregated serving:
- Deploy vLLM Disaggregated Serving: 2 prefill workers + 2 decode workers with NIXL-based KV cache transfer
- Deploy TensorRT-LLM Disaggregated Serving: TRT-LLM disaggregated configuration with KV cache optimization
- Deploy SGLang Disaggregated Serving: SGLang disaggregated setup with bootstrap_info transfer
These guides provide:
- Complete deployment scripts with environment variable configuration
- Container runtime setup with GPU allocation
- NIXL configuration for inter-worker KV cache transfer
- Verification steps and troubleshooting guidance
Validate Performance with AIPerf
After deployment, validate AIConfigurator's predictions against actual performance using AIPerf.
Install AIPerf benchmarking tool.
console$ pip3 install aiperf
Derive AIPerf parameters from AIConfigurator output.
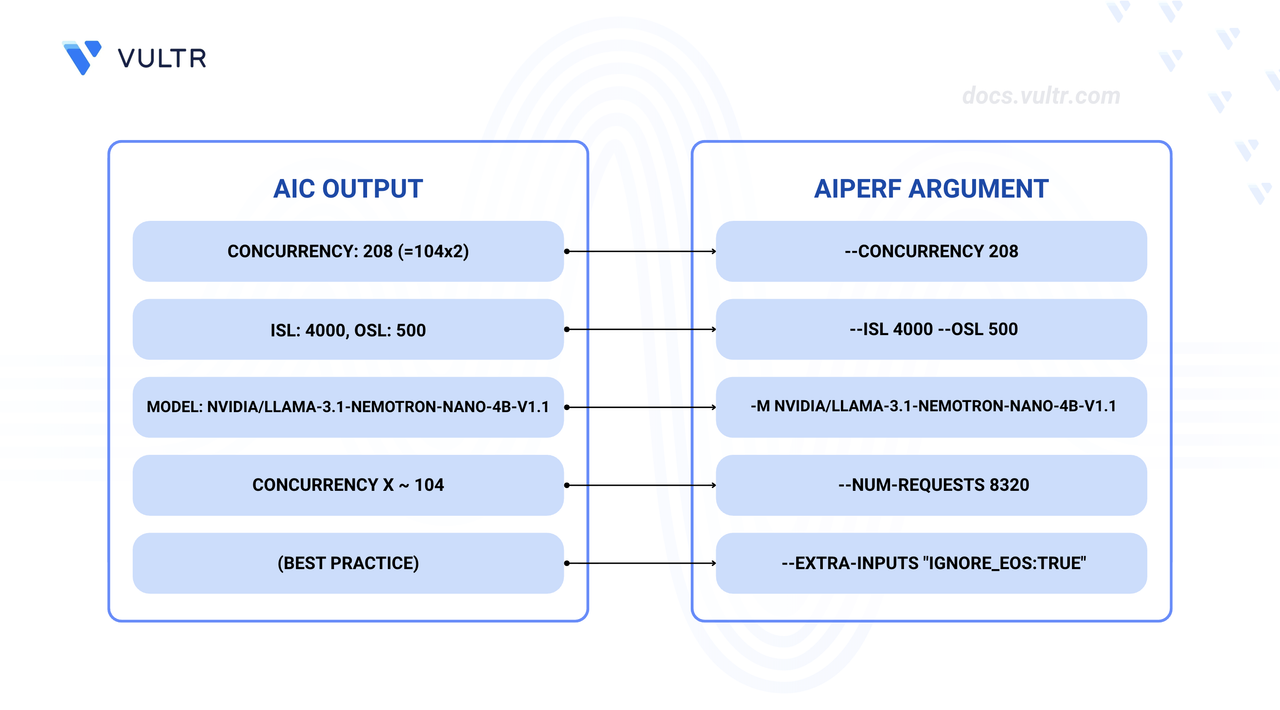
Values used for testing:
--concurrency 30(AIConfigurator recommends208for max throughput)--num-requests 800(Recommended:8320= concurrency × 40 for statistical stability)--isl 4000 --osl 500(Match your AIConfigurator inputs)--extra-inputs "ignore_eos:true"(Ensures exact OSL tokens generated)
Run AIPerf benchmark against the deployment.
console$ aiperf profile \ -m nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1 \ --endpoint-type chat \ -u http://localhost:8000 \ --isl 4000 --isl-stddev 0 \ --osl 500 --osl-stddev 0 \ --num-requests 800 \ --concurrency 30 \ --streaming \ --extra-inputs "ignore_eos:true" \ --num-warmup-requests 40 \ --ui-type simple
The command above usesNote--concurrency 30and--num-requests 800for early success and faster testing. For best throughput validation, use the recommended values:--concurrency 208and--num-requests 8320(concurrency × 40 for statistical stability).The benchmark runs 800 requests with 30 concurrent connections. The output displays performance metrics:
NVIDIA AIPerf | LLM Metrics ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┓ ┃ Metric ┃ avg ┃ min ┃ max ┃ p99 ┃ p90 ┃ p50 ┃ std ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━┩ │ Time to First Token (ms) │ 496.77 │ 55.53 │ 8,411.38 │ 6,972.51 │ 64.59 │ 59.78 │ 1,606.66 │ │ Time to Second Token (ms) │ 0.24 │ 0.00 │ 4.72 │ 3.55 │ 0.00 │ 0.00 │ 0.81 │ │ Time to First Output Token (ms) │ 496.77 │ 55.53 │ 8,411.38 │ 6,972.51 │ 64.59 │ 59.78 │ 1,606.66 │ │ Request Latency (ms) │ 2,367.45 │ 1,505.01 │ 9,807.65 │ 8,869.04 │ 1,996.11 │ 1,972.56 │ 1,528.95 │ │ Inter Token Latency (ms) │ 3.75 │ 2.74 │ 3.90 │ 3.89 │ 3.85 │ 3.83 │ 0.25 │ │ Output Token Throughput Per User │ 268.03 │ 256.55 │ 365.49 │ 357.48 │ 279.88 │ 260.84 │ 22.84 │ │ (tokens/sec/user) │ │ │ │ │ │ │ │ │ Output Sequence Length (tokens) │ 499.53 │ 487.00 │ 510.00 │ 502.00 │ 500.10 │ 500.00 │ 1.30 │ │ Input Sequence Length (tokens) │ 4,000.00 │ 4,000.00 │ 4,000.00 │ 4,000.00 │ 4,000.00 │ 4,000.00 │ 0.00 │ │ Output Token Throughput (tokens/sec) │ 6,232.31 │ N/A │ N/A │ N/A │ N/A │ N/A │ N/A │ │ Request Throughput (requests/sec) │ 12.48 │ N/A │ N/A │ N/A │ N/A │ N/A │ N/A │ │ Request Count (requests) │ 800.00 │ N/A │ N/A │ N/A │ N/A │ N/A │ N/A │ └──────────────────────────────────────┴──────────┴──────────┴──────────┴──────────┴──────────┴──────────┴──────────┘ Benchmark Duration: 64.12 secCompare actual vs predicted performance.
| Metric | AIConfigurator Prediction (2 GPUs) | AIPerf Actual (2 GPUs) | Status | |--------|--------------------------|---------------|--------| | TTFT (ms) | 111.33 | 59.78 (p50) / 496.77 (avg) | p50 close to prediction | | ITL/TPOT (ms) | 15.62 (1000/63.99) | 3.75 | 4x better than predicted | | Throughput (tokens/s) | 6,135.02 (3,067.51 × 2) | 6,232.31 | 101.6% - exceeds prediction | | Per-GPU Throughput | 3,067.51 tokens/s/gpu | 3,116 tokens/s/gpu | Matches prediction |
The per-GPU throughput (6,232.31 ÷ 2 GPUs = 3,116 tokens/s/gpu) closely matches AIConfigurator's prediction of 3,067.51 tokens/s/gpu. The total throughput (6,232.31 tokens/s) actually exceeds the prediction for 2 GPUs (6,135.02 tokens/s). This benchmark was run with 2 GPUs (1 prefill + 1 decode worker); scaling to 4 GPUs (2 prefill + 2 decode workers as shown in the deployment manifest) would double the throughput to approximately 12,464 tokens/s. The lower throughput compared to maximum capacity is due to using concurrency 30 instead of the recommended 208. The Inter Token Latency (3.75ms) significantly outperforms predictions, demonstrating efficient token generation.
Understanding Request Flow in Disaggregated Mode
Understanding the request flow helps troubleshoot issues and optimize configuration.
Request Routing to Prefill Worker
- Frontend receives inference request.
- PrefillRouter selects prefill worker based on KV cache affinity and availability.
- Request is forwarded to selected prefill worker.
KV Cache Generation (Prefill Phase)
- Prefill worker loads model weights (shared via tensor parallelism).
- Processes entire input prompt in parallel.
- Generates KV cache for all input tokens.
- Generates first output token.
NIXL-Based KV Cache Transfer
- Prefill worker prepares KV cache for transfer.
- NIXL uses RDMA (InfiniBand
rc_xordc_xtransport) for GPU-to-GPU transfer. - Transfer metadata includes backend-specific information:
- vLLM:
kv_transfer_paramswith block IDs and GPU memory addresses. - SGLang:
bootstrap_infowith KV cache layout and tensor locations. - TRT-LLM:
opaque_statewith serialized KV cache metadata.
- vLLM:
Decode Worker Receiving KV Cache
- Decode worker receives KV cache via NIXL/RDMA.
- Registers received KV cache blocks in local memory manager.
- Verifies KV cache integrity (checksum validation).
- Prepares for token generation.
Token Generation on Decode Worker
- Decode worker generates subsequent tokens using received KV cache.
- Each token generation step is fast (compute-bound, not memory-bound).
- High batch size (256-1024) enables efficient GPU utilization.
- Continues until max_tokens or EOS token is reached.
Performance Characteristics:
- With RDMA: KV cache transfer takes 10-50ms for typical prompt sizes.
- Without RDMA: KV cache transfer takes 400-2000ms (40x slower), making disaggregated serving impractical.
- Prefill TTFT: ~350-450ms for 4000 token prompts.
- Decode TPOT: ~12-15ms per token with high concurrency.
Configuration Best Practices
GPU Allocation Strategies
Prefill Workers:
- Allocate fewer GPUs with higher memory bandwidth (memory-bound workload).
- Use lower tensor parallelism (TP1 or TP2) to minimize communication overhead.
- Deploy multiple replicas for higher prefill throughput.
Decode Workers:
- Allocate more GPUs for parallel token generation (compute-bound workload).
- Use higher tensor parallelism (TP4 or TP8) to distribute computation.
- Single replica with high batch size often performs best.
Example Configuration (4 GPUs):
- 2× Prefill workers with TP1 (2 GPUs total, 1 GPU each).
- 2× Decode workers with TP1 (2 GPUs total, 1 GPU each).
- Achieves balanced prefill and decode capacity with minimal tensor parallelism overhead.
Tensor Parallelism Considerations
Different TP settings for prefill and decode workers enable independent optimization.
| Worker Type | Recommended TP | Reasoning |
|---|---|---|
| Prefill | TP1 or TP2 | Minimizes all-reduce communication overhead, prefill is memory-bound |
| Decode | TP4 or TP8 | Distributes compute load, decode is compute-bound |
Example: 4× H200 GPUs, 4B model
- For this small model, AIConfigurator recommends aggregated serving.
- Best agg config: TP1 with 4 replicas achieves 3785 tokens/s/gpu.
- Best disagg config: TP1 prefill + TP1 decode achieves 3067 tokens/s/gpu.
- Result: Aggregated is 23% faster due to lower overhead with small KV cache.
Batch Size Tuning
Prefill Workers:
- Use low batch size (1-4) for optimal TTFT.
- Higher batch sizes increase memory pressure and TTFT latency.
- Prefill throughput comes from multiple workers, not high batch size.
Decode Workers:
- Use high batch size (256-1024) for optimal throughput.
- Decode operations are compute-bound and benefit from high concurrency.
- Adjust based on available GPU memory and model KV cache requirements.
RDMA Requirements
Network Requirements:
- InfiniBand (preferred) or RoCE network with RDMA support.
- Sufficient bandwidth: 200 Gbps+ recommended for optimal performance.
- Low latency: <10μs for RDMA operations.
Configuration Requirements:
- RDMA device plugin installed on Kubernetes nodes.
rdma/hca_shared_devicesresources requested matching tensor parallelism size.IPC_LOCKcapability for memory registration.- UCX environment variables configured (see Kubernetes deployment section).
Verification:
- Check worker logs for "NIXL is available" and "Backend UCX was instantiated" messages.
- Monitor RDMA device utilization:
rdma resource show. - Measure RDMA bandwidth:
ib_write_bworrdma_bwtools.
When Disaggregated Serving Outperforms Aggregated
Disaggregated serving provides the greatest benefit in these scenarios:
Large Model Deployments (32B+ parameters):
- KV cache size is large enough that transfer benefits outweigh overhead.
- Phase-specific optimization yields significant throughput gains.
- Example: For a 32B model on 8 GPUs, disaggregated can achieve 1.31x better throughput.
Long Context Workloads (ISL > 4000):
- Prefill phase dominates overall latency.
- Specialized prefill workers optimize memory bandwidth.
- Decode workers can serve multiple requests concurrently.
High Throughput Requirements:
- Per-GPU throughput maximization is critical.
- Independent scaling of prefill and decode capacity.
- Workload patterns allow decode worker reuse across multiple requests.
Production Deployments with Variable Load:
- Scale prefill and decode workers independently based on demand.
- Optimize resource allocation per phase characteristics.
- Better handling of traffic spikes and batch processing scenarios.
When Aggregated Is Better:
- Small models (<10B parameters) - like the 4B example where agg is 1.23x faster.
- Balanced ISL/OSL ratios (2:1 to 10:1).
- Simpler operational model preferred.
- RDMA infrastructure not available.
- Strict latency SLAs with minimal overhead tolerance.
Conclusion
You have successfully used AIConfigurator to discover optimal configurations and deploy disaggregated inference with NVIDIA Dynamo. For this 4B model, aggregated serving performed 23% better, while larger models (32B+) benefit from disaggregated architecture with up to 1.7x throughput improvement. Disaggregated serving requires RDMA infrastructure for efficient KV cache transfer but enables superior per-GPU efficiency and independent scaling. Always follow AIConfigurator's recommendations and validate with AIPerf benchmarking for production deployments. For advanced configurations, refer to the official NVIDIA Dynamo documentation.