
How to Set Up Guardrails on Large Language Models using NVIDIA NeMo
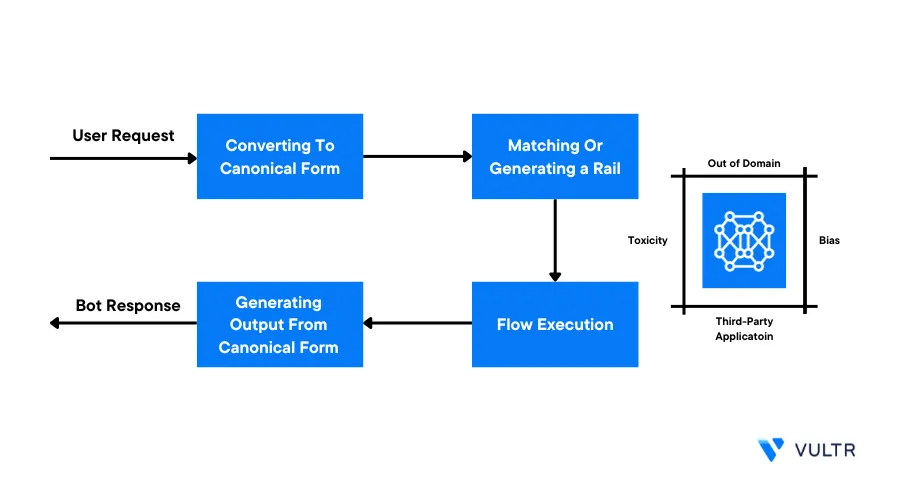
Introduction
Neural Modules (NeMo) Guardrails is an open-source toolkit developed by NVIDIA, to safeguard the development of LLMs by preventing harmful or offensive content. It provides features to control the LLMs and helps mitigate the risks of models by adding an essential layer of protection that assists organizations in building reliable systems without exposing the user to unwanted information.
This article explains how to set up the NeMo Guardrails for dolly-v2-3b LLM using the HuggingFace pipeline and control the response generation that matches the prompt provided.
Prerequisites
- Deploy a Ubuntu 22.04 A100 Vultr Cloud GPU server.
- Using SSH, access the server
- Create a non-root user with sudo rights and switch to the account.
- Install JupyterLab and PyTorch.
Install the Required Packages
To set up guardrails on your server, install the necessary dependency packages to infer the model.
Install the required packages
$ pip3 install nemoguardrails langchainBelow is what each package represents:
nemoguardrails: Provides the necessary modules to use NeMo Guardrails toolkit such asRailsConfig,register_llm_provider, andLLMRailslangchain: Import theHuggingFacePipelinethat initializes the model in use
Set Up Guardrails
To set up Guardrails, import the necessary modules. Then, set the guardrails policies, initialize the dolly-v2-3b model with the HuggingFace pipeline, and infer it as described in the steps below.
In your Jupyter Lab interface, create a new
Python3 KernelNotebookImport the necessary modules
from functools import lru_cache from langchain import HuggingFacePipeline from torch.cuda import device_count from nemoguardrails.llm.helpers import get_llm_instance_wrapper from nemoguardrails.llm.providers import register_llm_provider from nemoguardrails import LLMRails, RailsConfigBelow is what each module represents:
lru_cache: It's used for memorization which is an optimization technique to improve the efficiency of functionsHuggingFacePipeline: Creates pipelines for pre-trained LLMs and NLP tasksdevice_count: Determines the number of available CUDA devicesget_llm_instance_wrapper: Gets an instance for a specified LLMregister_llm_provider: Specifies the source for LLM modelsLLMRails: Generates a response from a prompt by creating railsRailsConfig: Initializes the custom configurations you defined for response generation
Click Run or press Ctrl + Enter to import the modules
In a new code cell, create the custom guardrails
yaml_content = """ models: - type: main engine: hf_pipeline_dolly """ colang_content = """ define user express greeting "hello" "hi" "what's up?" define bot express greeting "Hi there, I am your Library assistant what would you like to read ?" define bot ask how are you "I hope everything's going well with you" define flow greeting user express greeting bot express greeting bot ask how are you define user ask politics "what are your political beliefs?" "thoughts on the president?" "left wing" "right wing" define bot answer politics "I'm a library assistant, I don't like to talk of politics." define bot offer help "Is there anything else i can help you with?" define flow politics user ask politics bot answer politics bot offer help """The above code sets the YAML content used to define the model in use. It also defines the CoLang content where the guardrails for expected user prompts and model responses are listed. Then the conversation flow is defined to avoid misdirection and hallucination in the responses generated by the bot.
Edit the prompts in the above code and the response definitions along with flow definitions to match your use case. For the guardrails to work, be sure to follow the CoLang syntax.
Define the model function
@lru_cache def get_dolly_v2_3b_llm(): repo_id = "databricks/dolly-v2-3b" params = {"temperature": 0, "max_length": 1024} # Use the first CUDA-enabled GPU, if any device = 0 if device_count() else -1 llm = HuggingFacePipeline.from_model_id( model_id=repo_id, device=device, task="text-generation", model_kwargs=params ) return llmThe above command defines a function
get_dolly_v2_3b_llmthat configures the model, its temperatureandmax_lengthparameters. The model can either either run on a CUDA-enabled GPU or CPU. The function returns the initialized model withllm`.Initiate the pipeline
HFPipelineDolly = get_llm_instance_wrapper( llm_instance=get_dolly_v2_3b_llm(), llm_type="hf_pipeline_dolly" ) register_llm_provider("hf_pipeline_dolly", HFPipelineDolly)The above command creates an LLM instance using the specified model and parameters. Then, the instance is registered with the source of the model for text generation tasks.
Initialize the custom configurations
config = RailsConfig.from_content( yaml_content=yaml_content, colang_content=colang_content ) rails = LLMRails(config)The above command initializes the
yaml_contentandcolang_contentyou defined earlier, then it creates the LLM Rails by passingconfig.Generate response. Replace the prompt
What do you think of the presidentwith your desired text promptres = await rails.generate_async(prompt="what do you think of the president?") print(res)The above code asynchronously generates a response considering the guardrails you set up.
Output:
I'm a library assistant, I don't like to talk of politics. Is there anything else i can help you with?
Conclusion
You have inferred the dolly-v2-3b model using the HuggingFace pipeline and applied custom guardrails using the NeMo toolkit. The guardrails control the model's response so that it does not go off-topic or hallucinate. This protects the user from harmful information.
More Information
For more information and implementation samples, please visit the following resources: