
How to Use Meta Llama 3 Large Language Model on Vultr Cloud GPU
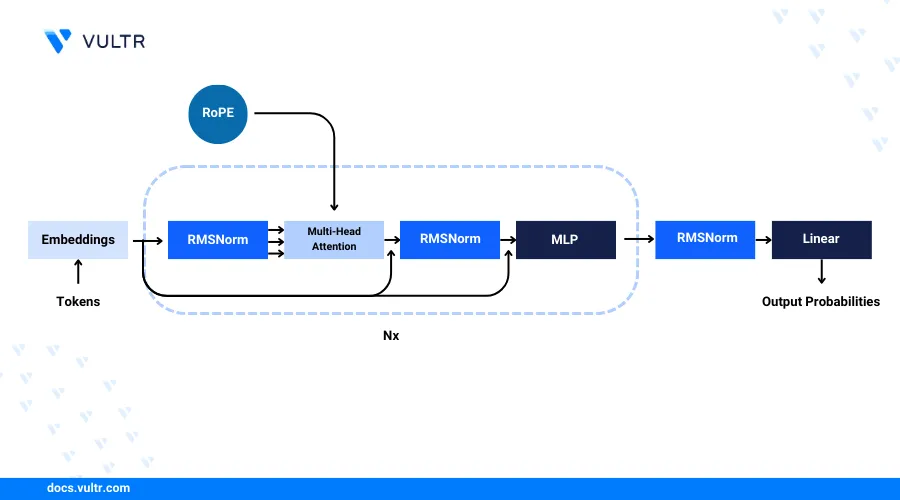
Introduction
Llama 3 is a family of Large Language Models released by Meta, It is a collection of pre-trained and instruction-tuned generative text models. Llama 3 is pre-trained over 15T tokens collected from publically available sources, it is an auto-regressive family of models that uses an optimized transformer architecture. The instruction-tuned models use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). The Llama 3 models have a custom limited commercial license which means models can used for commercial and research purposes.
In this article, you are to run inference workloads on the Llama3 8B and Llama 3 8B Instruct models. You also going to be exploring the model benchmarks to evaluate the model performance.
Prerequisites
- Deploy a Vultr Cloud GPU instance.
- Access the Jupyter Lab environment from the Instance Page.
- Have access to Meta Llama 3 model weights on HuggingFace
Infer Meta Llama 3 8B
In this section, you are to run inference workloads on the Llama 3 8B base model with 8 billion parameters.
Install the required dependencies.
python!pip install pytorch transformer huggingface-hub
Log in to the HuggingFace Hub.
pythonhuggingfacehub-cli --login
On the execution of this command, you will be prompted for an access token. Where you have to provide the token to access the Llama 3 Models.
Import necessary modules.
pythonimport transformers import torch
Declare the Model.
pythonmodel_id = "meta-llama/Meta-Llama-3-8B"
Declare the model pipeline.
pythonpipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
In the above code, you declared the model pipeline with the
task-generationtask. By default, Llama 3 8B is set to 16-bit precision.Provide a prompt.
pythonpipeline("Hey how are you doing today?")
Infer Meta Llama 3 8B Instruct
In this section, you are to run inference workloads on the Llama 3 8B Instruct model with 8 billion parameters. This model is fine-tuned for dialogue-based use cases.
Import necessary modules.
pythonimport transformers import torch
Declare the model.
pythonmodel_id = "meta-llama/Meta-Llama-3-8B-Instruct"
Declare the model pipeline.
pythonpipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device="auto", )
Set roles for the model.
pythonmessages = [ {"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"}, {"role": "user", "content": "Who are you?"}, ]
In the above code, you are setting the roles informing the chatbot that it is a pirate chatbot.
Make a prompt template.
pythonprompt = pipeline.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True )
Set the terminators for text generation.
pythonterminators = [ pipeline.tokenizer.eos_token_id, pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>") ]
Set the model parameters.
pythonoutputs = pipeline( prompt, max_new_tokens=256, eos_token_id=terminators, do_sample=True, temperature=0.6, top_p=0.9, )
In the above code, you are setting up the model parameters that can be adjusted to improve the response generated by the model.
Print the generated output.
pythonprint(outputs[0]["generated_text"][len(prompt):])
Conclusion
In this article, you used Meta Llama 3 models on a Vultr Cloud GPU Server. And ran inference workloads with the latest Llama 3 80B in 16-bit mode with its fine-tuned Instruct version also in the 16-bit mode.