Kimi-K2.5 (1T) Validation Testing
Updated on 11 March, 2026Validation benchmarks for Kimi-K2.5 (1 trillion parameters, 32B active) on 8x AMD Instinct MI325X GPUs.
Note
- This is a quick benchmark (0.5x multiplier) for initial validation. Full stress testing results will be added once the thorough benchmark is complete.
Concurrency Scaling
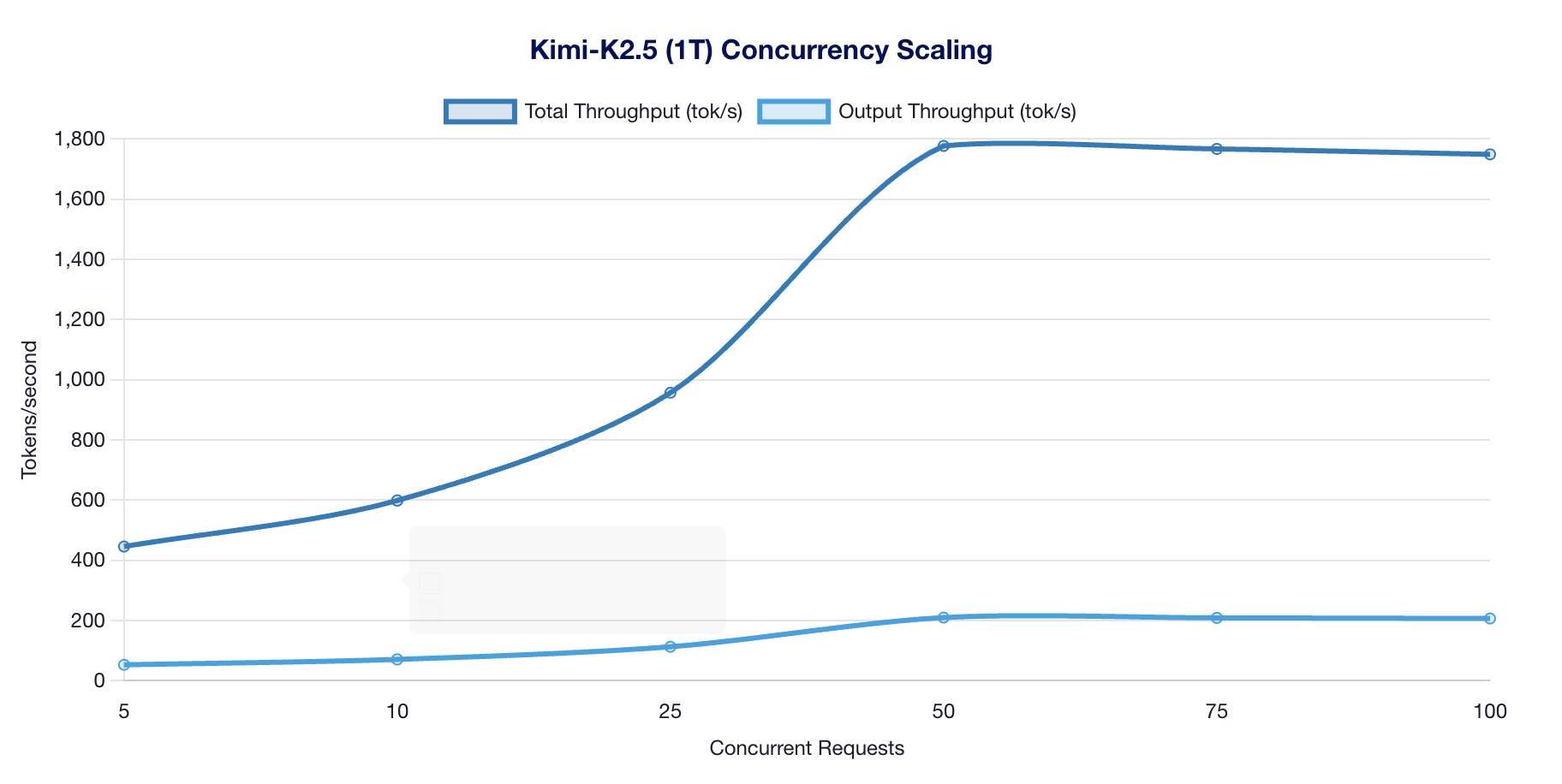
Scaling Results
| Concurrent | Throughput | Output tok/s | p99 Latency | Status |
|---|---|---|---|---|
| 5 | 446 tok/s | 53 | 18.94s | DEGRADED |
| 10 | 599 tok/s | 71 | 28.19s | DEGRADED |
| 25 | 957 tok/s | 113 | 44.15s | DEGRADED |
| 50 | 1,777 tok/s | 210 | 47.54s | DEGRADED |
| 75 | 1,767 tok/s | 209 | 47.79s | DEGRADED |
| 100 | 1,749 tok/s | 207 | 48.30s | DEGRADED |
Observations:
- Consistent scaling from 5 to 100 concurrent requests
- Peak scaling throughput of ~1,777 tok/s at 50 concurrent
- DEGRADED status indicates p99 latency >2x baseline (expected under concurrent load)
- 100% success rate maintained across all concurrency levels
Stress Tests
| Test Type | Mode | Throughput | Output tok/s | p99 Latency | Status |
|---|---|---|---|---|---|
| long_output | text | 107 tok/s | 90 | 83.26s | OK |
| long_context | text | 454 tok/s | 35 | 40.11s | OK |
| multi_image_3 | multi-image | 491 tok/s | 32 | 66.53s | OK |
| high_conc_vision | vision | 887 tok/s | 149 | 100.83s | OK |
Key findings:
- Long output generation (500 tokens): 107 tok/s total, 90 output tok/s
- Long context (4K tokens): 454 tok/s with 40.1s p99 latency
- Multi-image (3 images): 491 tok/s with 66.5s p99 latency
- High concurrency vision (100 concurrent): 887 tok/s, 149 output tok/s
Saturation Testing
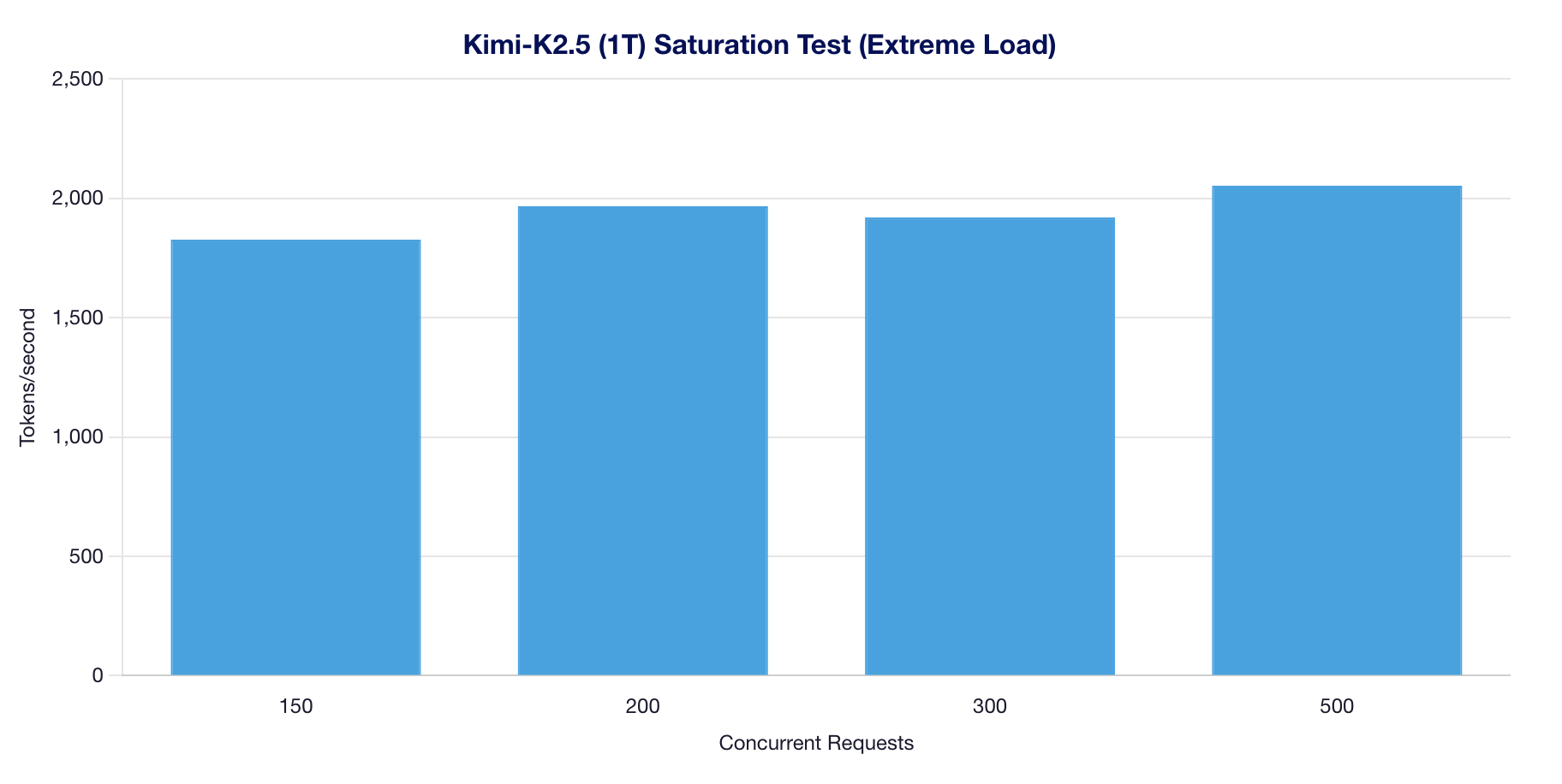
Extreme Load Results
| Concurrent | Throughput | Success Rate | p99 Latency | Status |
|---|---|---|---|---|
| 150 | 1,827 tok/s | 100% | 69.34s | OK |
| 200 | 1,967 tok/s | 100% | 64.36s | OK |
| 300 | 1,920 tok/s | 100% | 65.96s | SATURATED |
| 500 | 2,053 tok/s | 100% | 61.67s | OK |
Observations:
- Peak throughput of ~2,053 tok/s achieved at 500 concurrent
- Saturation begins at 300 concurrent requests
- 100% success rate maintained even under extreme load
- Consistent ~1,900-2,000 tok/s across 150-500 concurrent
Recommendations
| Use Case | Concurrency | Expected Throughput |
|---|---|---|
| Low latency | 1–5 | 450–600 tok/s |
| Balanced | 25–50 | 950–1,800 tok/s |
| High throughput | 100–200 | 1,750–2,000 tok/s |
Test Configuration
| Parameter | Value |
|---|---|
| Model | moonshotai/Kimi-K2.5 |
| Test Mode | quick (0.5x multiplier) |
| Timestamp | 20260203_153639 |
| Vision Model | Yes (MoonViT) |
Launch Command
bash
docker run --rm \
--name vllm-kimi-k25 \
--ipc=host \
--network=host \
--group-add video \
--group-add render \
--cap-add=SYS_PTRACE \
--cap-add=CAP_SYS_ADMIN \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "VLLM_ROCM_USE_AITER=0" \
--env "VLLM_USE_TRITON_FLASH_ATTN=0" \
rocm/vllm-dev:nightly \
vllm serve moonshotai/Kimi-K2.5 \
--tensor-parallel-size 4 \
--max-model-len 32768 \
--trust-remote-code \
--block-size 1 \
--mm-encoder-tp-mode data
Warning
- VLLM_ROCM_USE_AITER=0 - AITER disabled (MLA compatibility issues)
- TP=4 required - MLA attention head distribution (64/4=16 heads per GPU)
- --block-size 1 - Required for MLA architecture
- VLLM_USE_TRITON_FLASH_ATTN=0 - Required for MoonViT vision encoder
- --mm-encoder-tp-mode data - Vision encoder parallelism
Test Environment
| Specification | Value |
|---|---|
| GPU | 8x AMD Instinct MI325X |
| VRAM | 256 GB HBM3E per GPU (2 TB total) |
| Architecture | CDNA 3 (gfx942) |
| ROCm | 6.4.2-120 |
| vLLM | nightly (rocm/vllm-dev:nightly) |
| Tensor Parallel | 4 (required for AITER MLA) |