Llama 3.1 (405B) Validation Testing
Updated on 11 March, 2026Validation benchmarks for Llama 3.1 405B Instruct (dense architecture, 405B parameters) on 8x AMD Instinct MI325X GPUs.
Concurrency Scaling
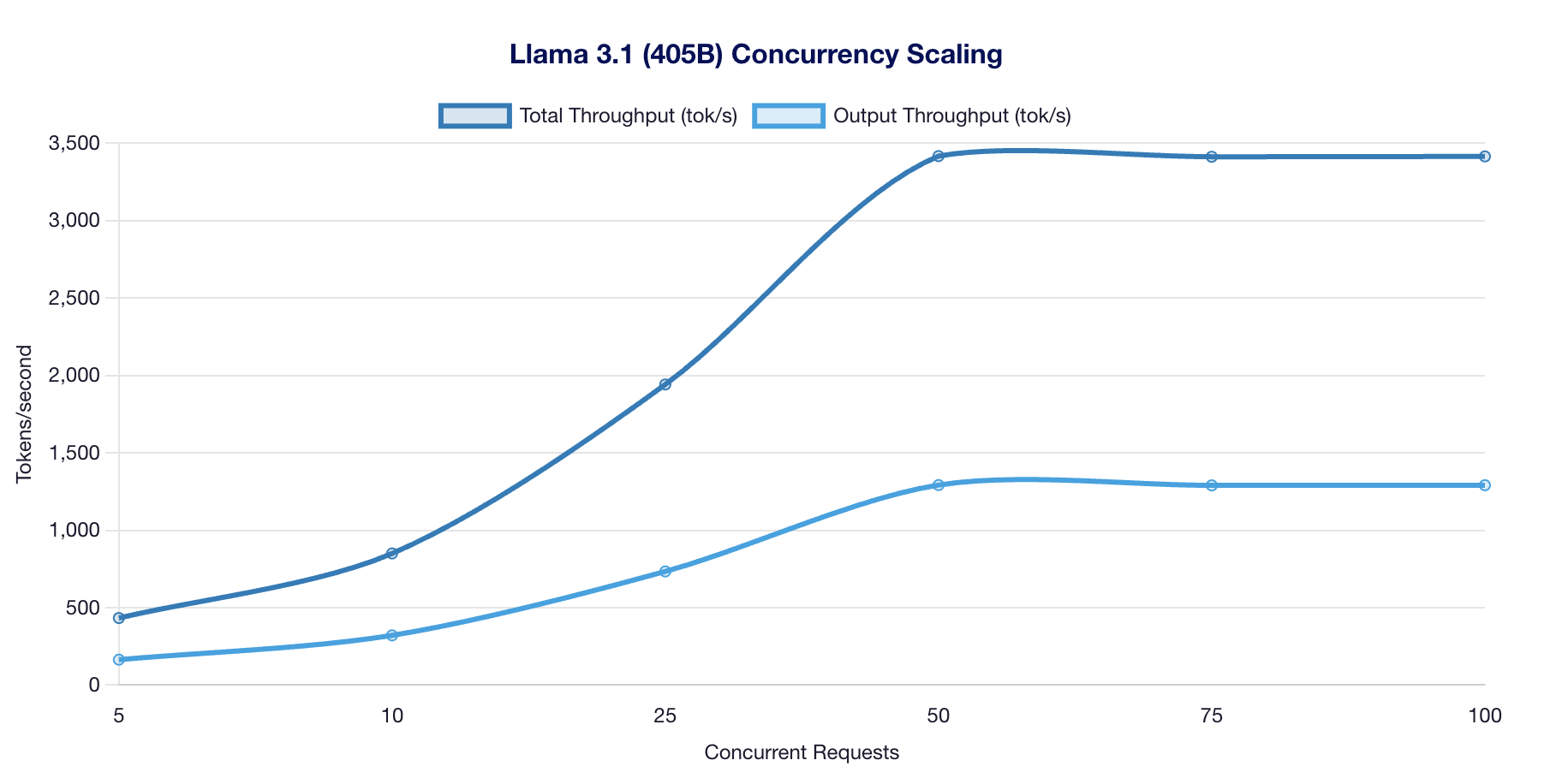
Scaling Results
| Concurrent | Throughput | Output tok/s | p99 Latency | Status |
|---|---|---|---|---|
| 5 | 433 tok/s | 164 | 6.11s | DEGRADED |
| 10 | 850 tok/s | 321 | 6.22s | DEGRADED |
| 25 | 1,942 tok/s | 734 | 6.79s | DEGRADED |
| 50 | 3,417 tok/s | 1,292 | 7.71s | DEGRADED |
| 75 | 3,413 tok/s | 1,290 | 7.72s | DEGRADED |
| 100 | 3,415 tok/s | 1,291 | 7.73s | DEGRADED |
Observations:
- Good scaling from 5 to 50 concurrent requests
- Peak scaling throughput of 3,417 tok/s at 50 concurrent
- Performance plateaus at 50-100 concurrent (dense model limitation)
- Dense architecture provides consistent, predictable performance
- DEGRADED status indicates p99 latency >2x baseline (expected under concurrent load)
Stress Tests
| Test | Throughput | Output tok/s | p99 Latency | Status |
|---|---|---|---|---|
| Long Output (1000 tokens) | 600 tok/s | 485 | 15.47s | OK |
| Long Context (4K) | 2,727 tok/s | 207 | 6.74s | OK |
Key findings:
- Long output generation (500 tokens): 600 tok/s with 15.5s p99 latency
- Long context (4K tokens): 2,727 tok/s with 6.7s p99 latency
Saturation Testing
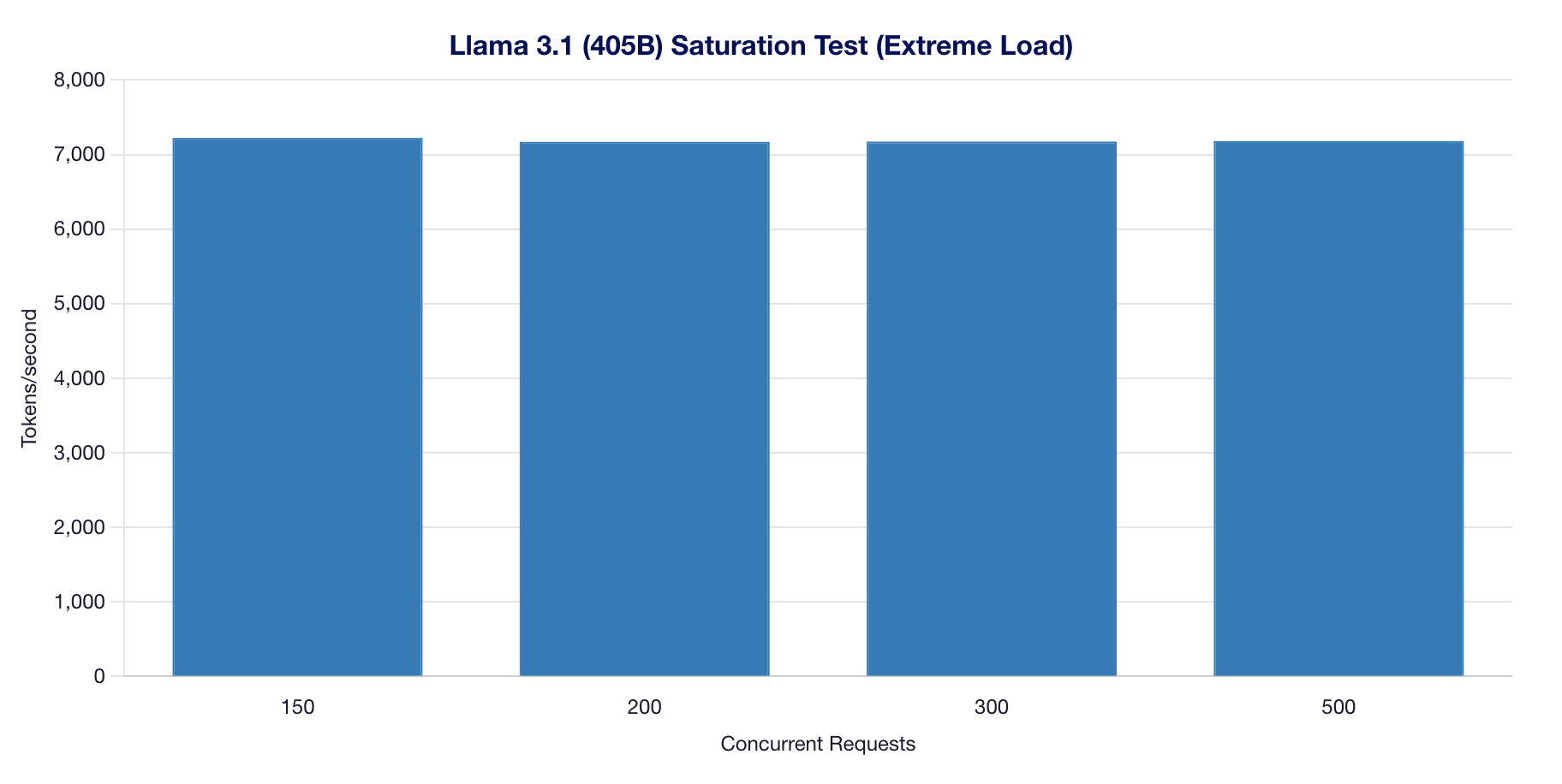
Extreme Load Results
| Concurrent | Throughput | Success Rate | p99 Latency | Status |
|---|---|---|---|---|
| 150 | 7,222 tok/s | 100% | 4.42s | OK |
| 200 | 7,169 tok/s | 100% | 4.44s | SATURATED |
| 300 | 7,173 tok/s | 100% | 4.42s | SATURATED |
| 500 | 7,180 tok/s | 100% | 4.43s | SATURATED |
Observations:
- Peak throughput of 7,222 tok/s achieved at 150 concurrent
- Saturation begins at 200 concurrent requests
- 100% success rate maintained even under extreme load
- Consistent ~7,170 tok/s across 150-500 concurrent
Recommendations
| Use Case | Concurrency | Expected Throughput |
|---|---|---|
| Low latency | 5–10 | 430–850 tok/s |
| Balanced | 25–50 | 1,900–3,400 tok/s |
| High throughput | 150 | 7,222 tok/s |
Test Configuration
| Parameter | Value |
|---|---|
| Model | meta-llama/Llama-3.1-405B-Instruct |
| Test Mode | quick |
| Timestamp | 20260128_195526 |
| Vision Model | No |
Launch Command
bash
docker run --rm \
--group-add=video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HF_TOKEN=$HF_TOKEN" \
--env "VLLM_USE_TRITON_FLASH_ATTN=0" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai-rocm:latest \
--model meta-llama/Llama-3.1-405B-Instruct \
--tensor-parallel-size 8 \
--max-model-len 32768 \
--quantization fp8
Test Environment
| Specification | Value |
|---|---|
| GPU | 8x AMD Instinct MI325X |
| VRAM | 256 GB HBM3E per GPU (2 TB total) |
| Architecture | CDNA 3 (gfx942) |
| ROCm | 6.4.2-120 |
| vLLM | 0.14.1 |