AITER Ablation Study
Updated on 11 March, 2026AITER (AMD Inference and Training Engine for ROCm) provides optimized attention kernels for AMD GPUs. This study measures its impact on inference throughput across model architectures.
Background
AITER replaces standard attention kernels with ROCm-optimized implementations. Its effectiveness varies by architecture:
| Architecture | AITER Support | Notes |
|---|---|---|
| GQA (Llama-405B) | Toggle-able | Can enable/disable for A/B testing |
| MLA (DeepSeek V3.2) | Required | vLLM depends on AITER's sparse attention indexer |
| MLA (Kimi-K2.5) | Disabled | Head count incompatibility with TP=4 |
| GQA + Vision (Qwen3-VL) | Default | Uses standard attention path |
Llama 405B: AITER Enabled vs Disabled
Llama-3.1-405B is the only model where AITER can be cleanly toggled, making it ideal for an A/B comparison. Each configuration was tested across 5 independent runs with 100 requests per concurrency level.
Throughput Comparison
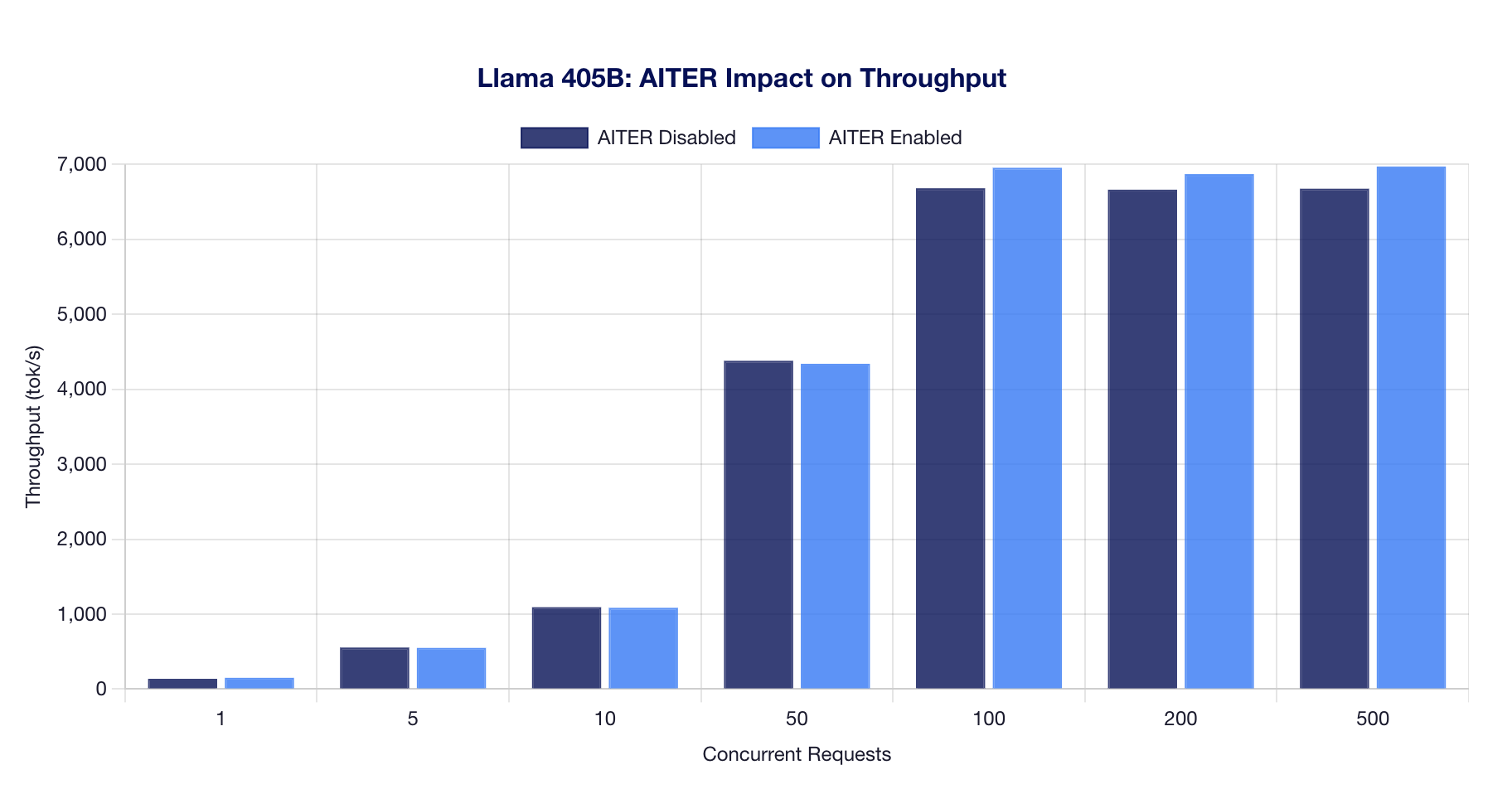
Detailed Results
| Concurrency | AITER Disabled (tok/s) | AITER Enabled (tok/s) | Difference (%) |
|---|---|---|---|
| 1 | 137 | 150 | +10.01% |
| 5 | 554 | 549 | -1.05% |
| 10 | 1,092 | 1,084 | -0.77% |
| 50 | 4,380 | 4,340 | -0.91% |
| 100 | 6,682 | 6,955 | +4.08% |
| 200 | 6,663 | 6,871 | +3.13% |
| 500 | 6,676 | 6,972 | +4.43% |
Findings:
- At low concurrency (1 request): AITER provides ~10% improvement, likely from kernel launch optimization.
- At medium concurrency (5-50): AITER shows a slight regression (~1%), within noise margin.
- At high concurrency (100-500): AITER provides a consistent 3-4% improvement, with the benefit growing as batch size increases.
- AITER-enabled runs show higher variance (CoV 1-5%) compared to disabled (CoV 0.1-0.3%), suggesting the optimized kernels have more variable scheduling behavior.
Recommendation: Enable AITER for production workloads at high concurrency. The 3-4% throughput gain is meaningful at scale, and the higher variance is acceptable for batch processing.
DeepSeek V3.2: AITER-Only Results
- AITER-disabled baseline impossible: vLLM requires AITER for MLA attention on ROCm (sparse attention indexer custom op dependency
Kimi-K2.5: AITER Incompatibility
Kimi-K2.5 runs with VLLM_ROCM_USE_AITER=0 because:
- The model has 64 MLA attention heads
- With TP=4, each GPU gets 16 heads (compatible count)
- However, AITER's MLA backend has additional requirements around the MXFP4 quantization format that are not available on MI325X (gfx942)
- First attempt with AITER enabled showed 145.27 GiB loaded before crashing at CUDA graph capture
Running without AITER, Kimi-K2.5 achieves stable inference at ~950 tok/s peak throughput.