GPU Power and Thermal Monitoring
Updated on 11 March, 2026Real-time GPU monitoring data collected via `rocm-smi` during Kimi-K2.5 benchmark runs on 8x AMD Instinct MI325X GPUs. Data was sampled at 1-second intervals across 3 independent runs.
Power Efficiency
- At peak throughput of 952 tok/s with 8 GPUs drawing an average of 389.8 W each (total system power: 3118 W), the approximate inference efficiency is 0.31 tok/s per watt. This reflects the measurement across 3 benchmark runs with 54,528 power samples collected.
Per-GPU Power Consumption
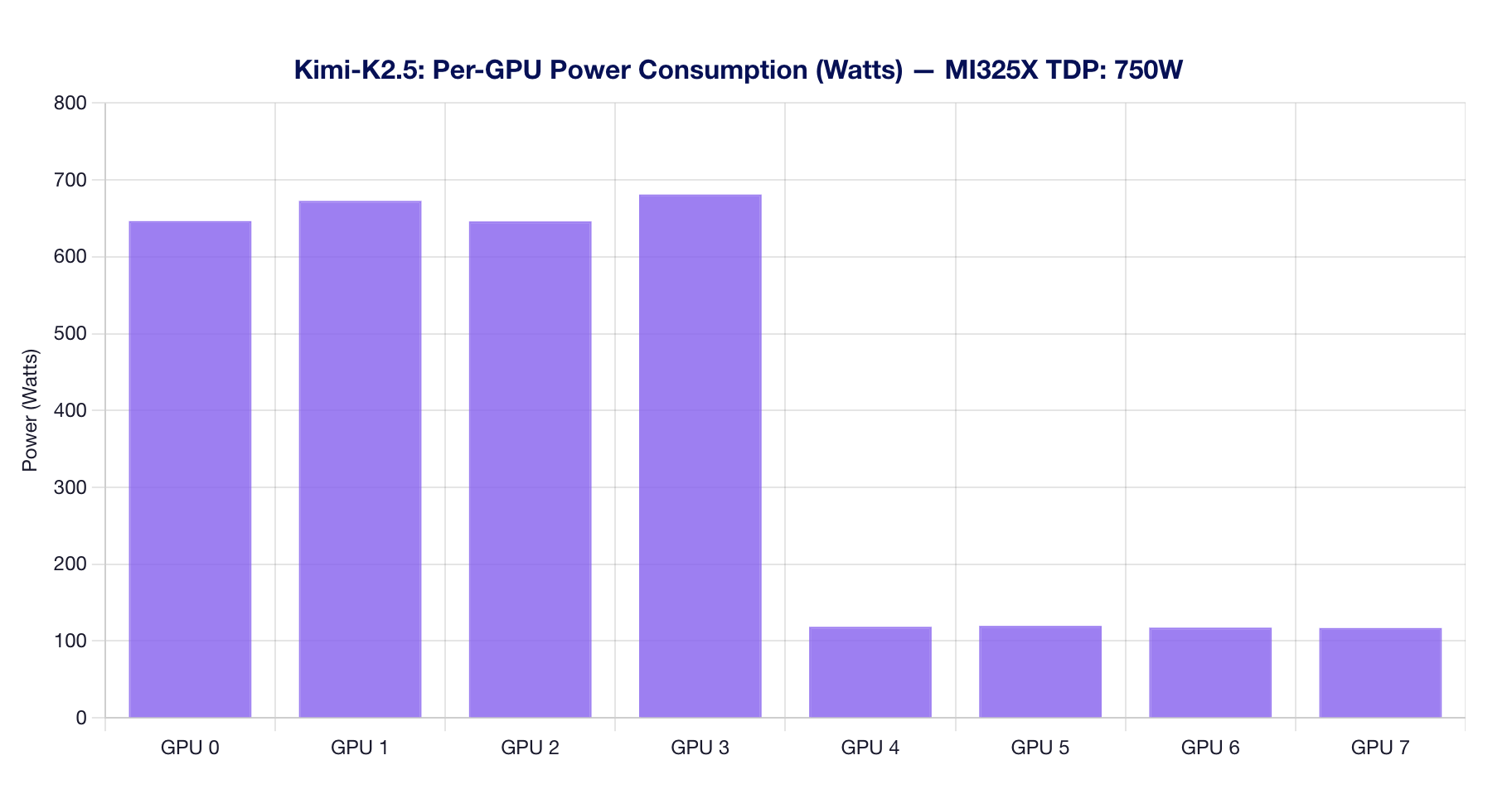
GPUs 0-3 (active for TP=4 inference) draw significantly more power than GPUs 4-7 (idle). The active GPUs average 640-680W each, well within the MI325X TDP of 750W.
Per-GPU Temperature
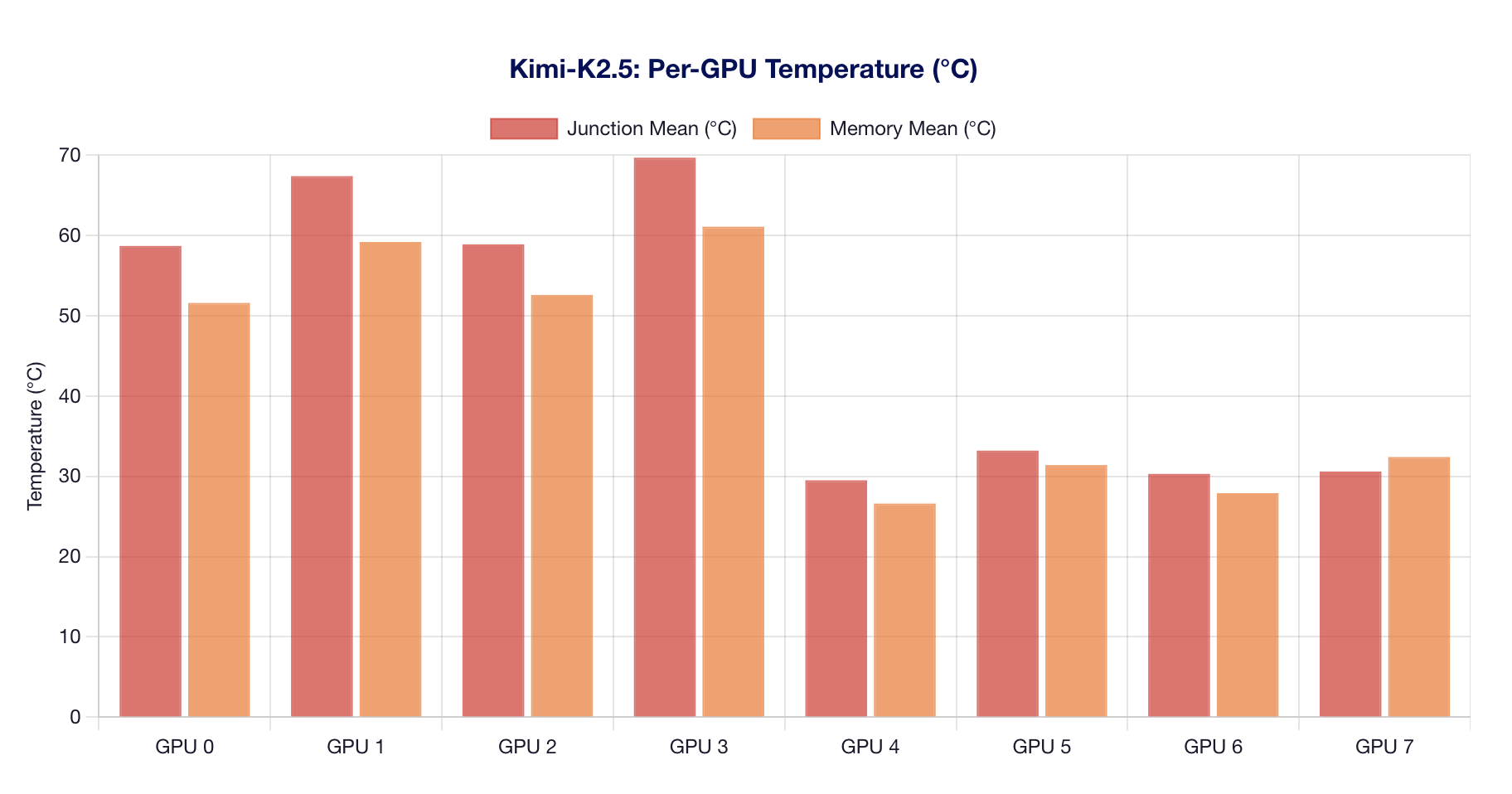
Junction and HBM3e memory temperatures track closely. Active GPUs (0-3) reach 60-80°C junction, while idle GPUs stay below 40°C.
Power Draw Over Time
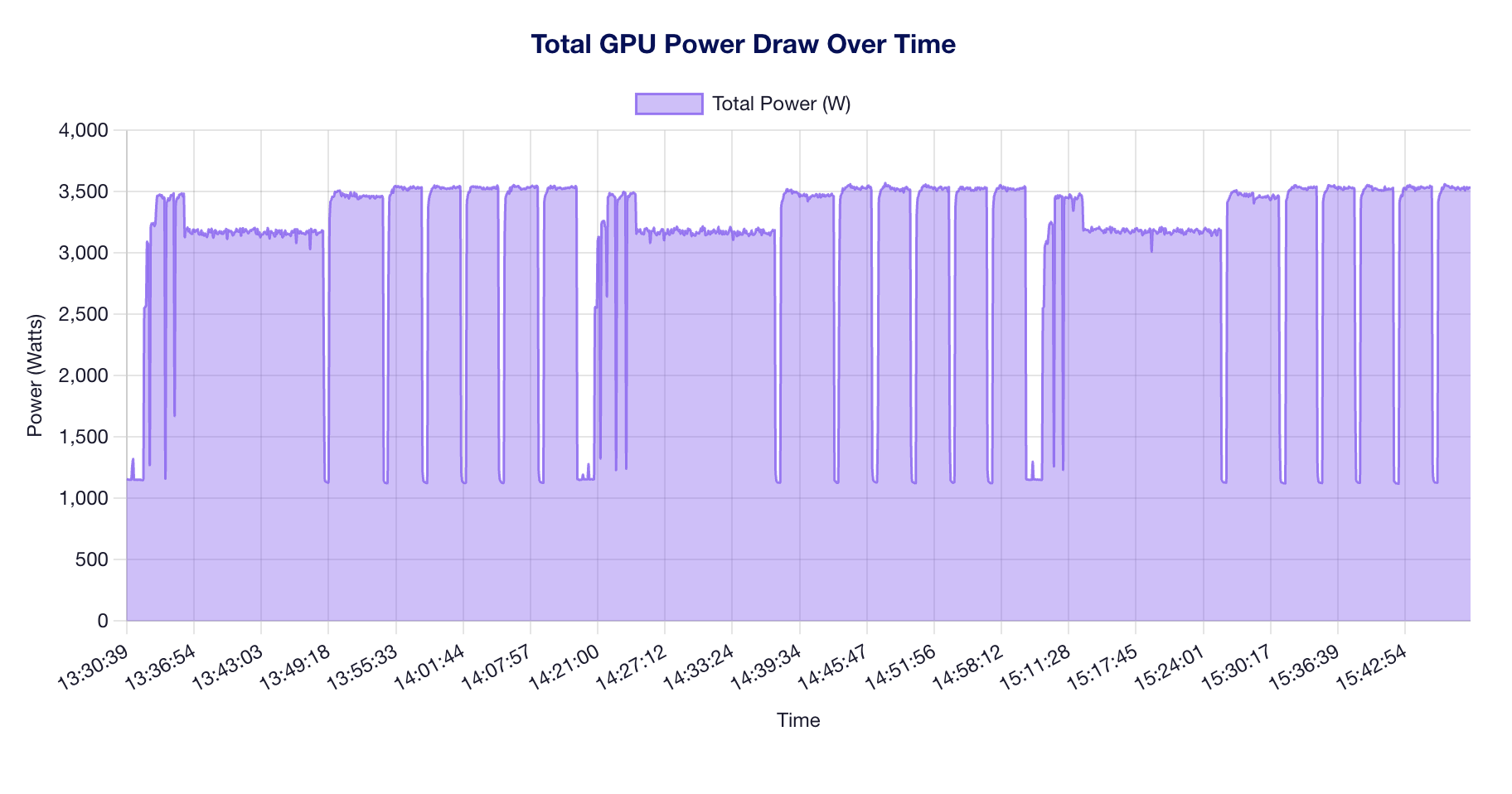
Total system power fluctuates as benchmark phases transition between concurrency levels. Peaks correspond to high-concurrency stress phases.
Temperature Over Time
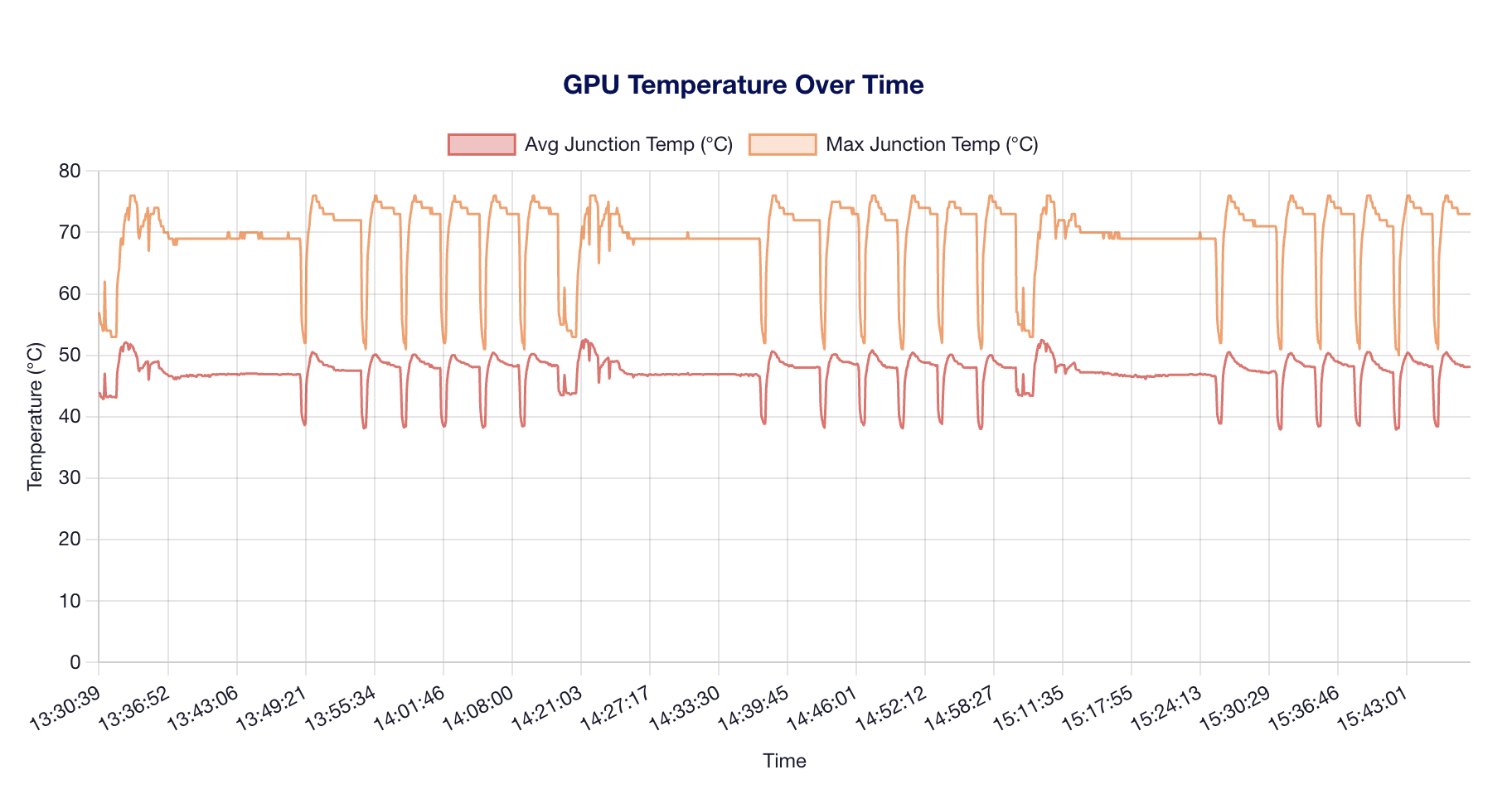
Temperature ramps correlate with sustained compute phases. The MI325X's cooling solution keeps junction temperatures well below throttling thresholds (100°C+).
Monitoring Summary
| Metric | Value |
|---|---|
| Overall Mean Power (W) | 389.8 |
| Overall Max Power (W) | 798.0 |
| Overall Mean Junction Temp (°C) | 47.3 |
| Overall Max Junction Temp (°C) | 76.0 |
| Mean Memory Temp (°C) | 42.8 |
| Max Memory Temp (°C) | 66.0 |
| Total Samples | 54,528 |
| Runs | 3, 4, 5 |
Key Observations
MI325X Thermal Headroom
- Peak junction temperature: ~76°C (well below throttle point)
- Active GPU mean power: ~660W (88% of 750W TDP)
- Idle GPU baseline: ~120W per GPU
Power Efficiency
With Kimi-K2.5 achieving ~952 tok/s peak throughput using 4 active GPUs at ~660W each, the effective power efficiency is approximately 0.36 tok/s per watt for the active GPUs. The remaining 4 idle GPUs draw baseline power but provide no inference throughput, which is a consideration for TP=4 models on 8-GPU systems.
Monitoring Methodology
All monitoring data was collected using:
rocm-smi --showpower --showtemp --showuse
at 1-second intervals as a background process during benchmark execution. This introduces negligible overhead (<0.1% CPU).