Client Overhead Validation
Before attributing throughput bottlenecks to model inference, we validated that the benchmark client itself is not the limiting factor.
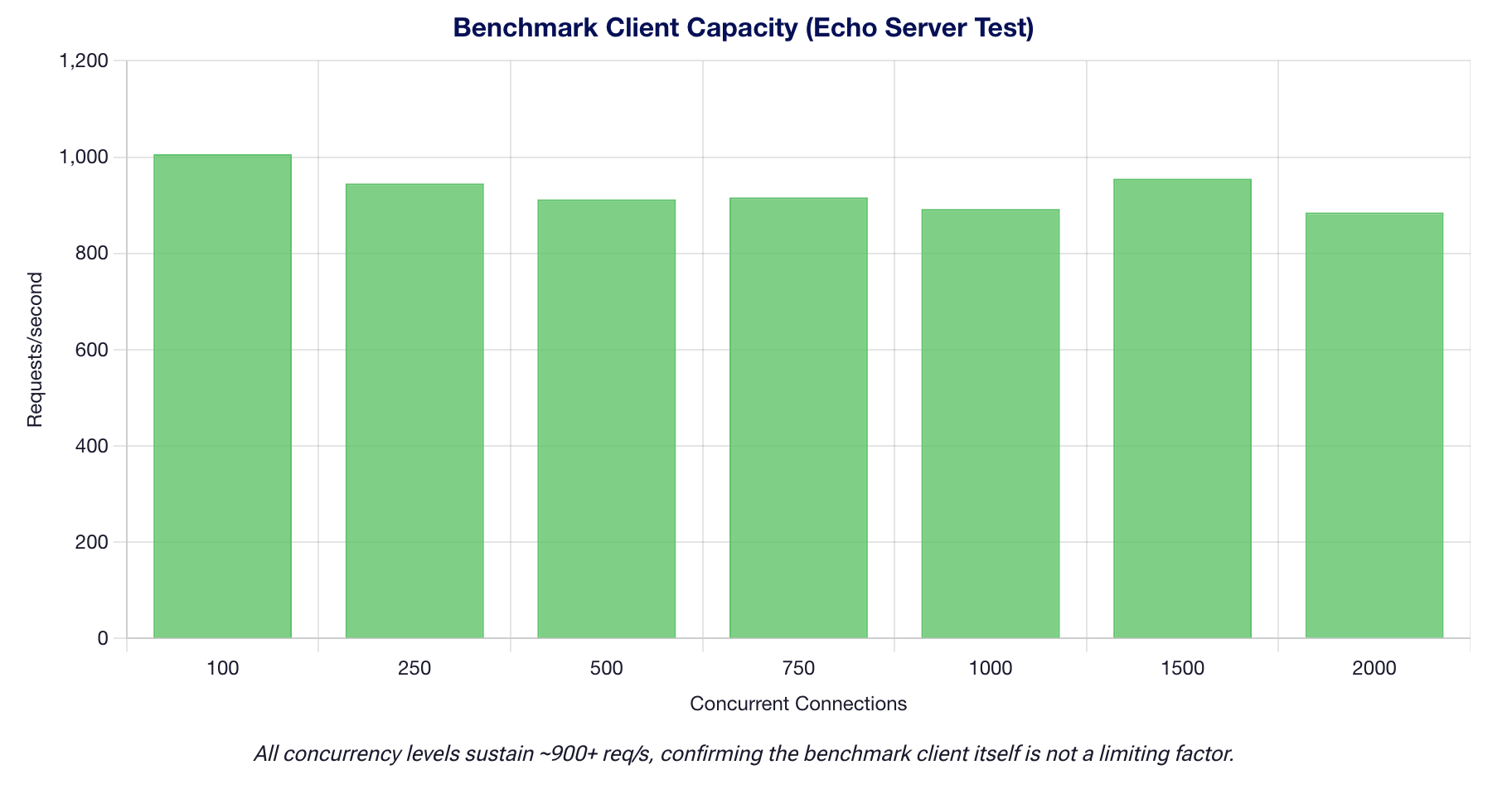
Benchmark Client Is Not The Bottleneck
- Client peak: 1,006 req/s against an echo server (concurrency 100, 1,000 requests per level).
- This exceeds all model throughputs by orders of magnitude. The highest model throughput is Qwen3-VL at ~11,218 tok/s, which at ~2,048 input tokens corresponds to roughly 5.5 effective req/s.
- Conclusion: The benchmark client is NOT the bottleneck. All observed throughput limits are attributable to the vLLM inference engine and GPU hardware, not to client-side HTTP overhead.
Client Throughput Capacity
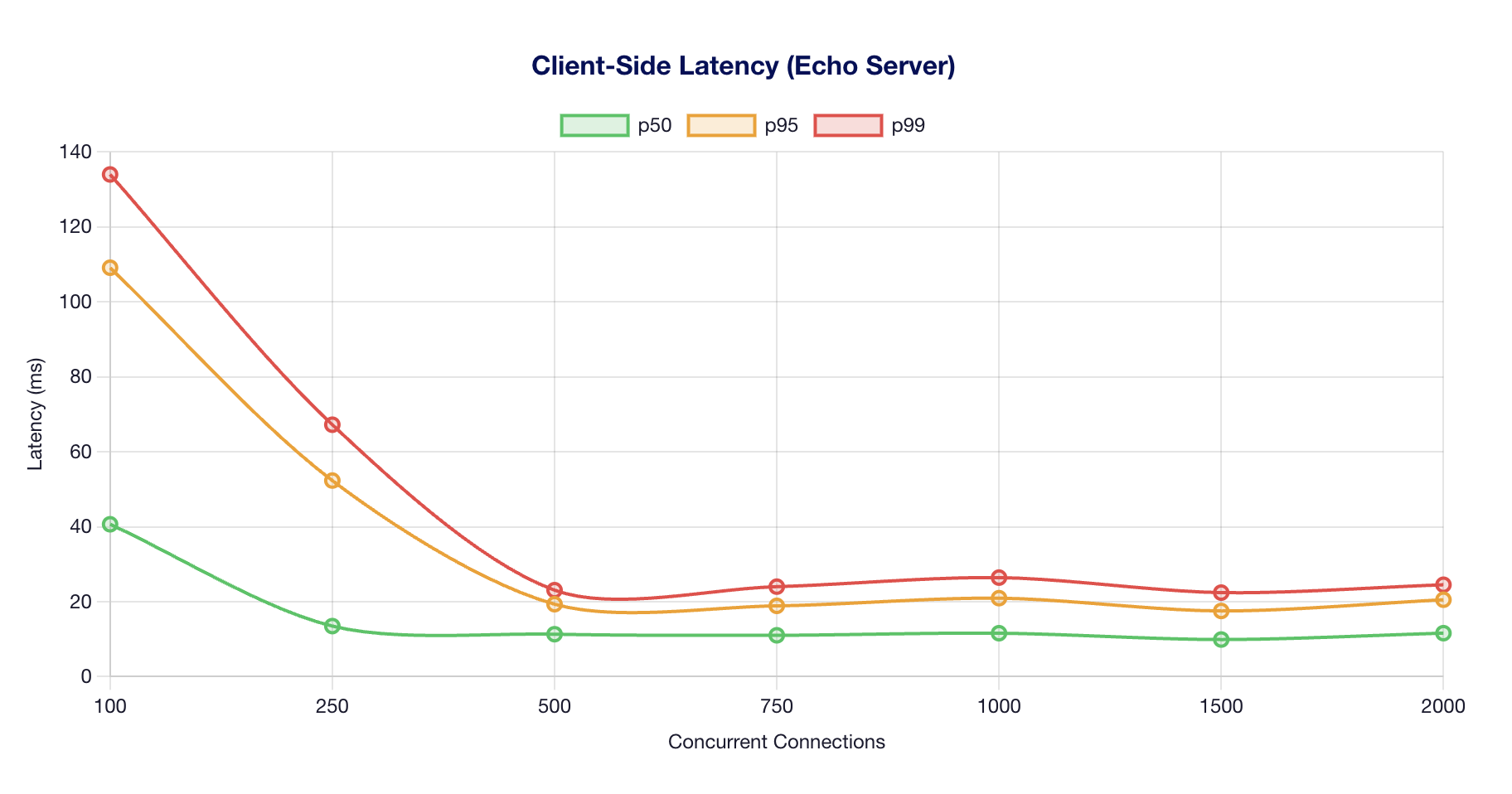
Client Latency Profile
Detailed Results
| Concurrency |
Requests/sec |
Tokens/sec |
p50 (ms) |
p95 (ms) |
p99 (ms) |
Success Rate |
| 100 |
1,006 |
1,00,635 |
40.66 |
109.12 |
134.01 |
100.0% |
| 250 |
945 |
94,545 |
13.49 |
52.32 |
67.23 |
100.0% |
| 500 |
912 |
91,168 |
11.33 |
19.33 |
23.08 |
100.0% |
| 750 |
916 |
91,590 |
11.03 |
18.89 |
24.01 |
100.0% |
| 1000 |
892 |
89,222 |
11.59 |
20.94 |
26.43 |
100.0% |
| 1500 |
955 |
95,542 |
9.90 |
17.53 |
22.42 |
100.0% |
| 2000 |
885 |
88,541 |
11.60 |
20.52 |
24.52 |
100.0% |
The echo server test confirms the Python asyncio benchmark client can sustain 1,006 requests/second at concurrency 100, with sub-millisecond overhead scaling well to 2,000 concurrent connections. Since the highest model throughput observed is ~11,218 tok/s for Qwen3-VL (effective ~5.5 req/s at 2048 input tokens), the client is never the bottleneck.
Test Environment
Hardware
| Component |
Specification |
| GPU |
8x AMD Instinct MI325X |
| Architecture |
CDNA 3 (gfx942) |
| VRAM per GPU |
256 GB HBM3e |
| Total VRAM |
2 TB (2,048 GB) |
| Memory Bandwidth (per GPU) |
6.0 TB/s |
| Aggregate Bandwidth |
48 TB/s |
| FP16 Compute (per GPU) |
1,307 TFLOPS |
Software Stack
| Component |
Version |
| ROCm |
6.4.2-120 |
| RCCL |
2.26.6 |
| Docker |
29.1.5 |
Container Images
| Image |
Used For |
vLLM Version |
vllm/vllm-openai-rocm:latest |
DeepSeek V3.2, Llama-3.1-405B, Qwen3-VL-235B |
0.14.1 |
rocm/vllm-dev:nightly |
Kimi-K2.5 |
0.16.0rc1 (nightly) |
Container digests (pinned for reproducibility):
| Image |
Digest |
vllm/vllm-openai-rocm:latest |
sha256:236900d573... |
rocm/vllm-dev:nightly |
sha256:e8ce7f6d74... |
Model Checkpoint Revisions
| Model |
HuggingFace Revision |
deepseek-ai/DeepSeek-V3-0324 |
e9b33add76883f293d6bf61f6bd89b497e80e335 |
meta-llama/Llama-3.1-405B-Instruct |
be673f326cab4cd22ccfef76109faf68e41aa5f1 |
Qwen/Qwen3-VL-235B-A22B-Instruct |
710c13861be6c466e66de3f484069440b8f31389 |
moonshotai/Kimi-K2-Instruct |
1cbe779b5c9d45782861647236f67e2e1aab55f0 |
Benchmark Protocol
Multi-Run Statistical Testing (n=5)
Each model was tested across 5 independent runs (container restarts between runs) to capture variance:
| Parameter |
Value |
| Independent runs per model |
5 |
| Cooldown between runs |
60 seconds |
| Warmup requests |
10 (discarded) |
| Input tokens |
2,048 |
| Output tokens |
512 |
| Prompts per concurrency level |
100 |
| Concurrency levels |
10, 50, 100, 200, 500, 750, 1,000 |
Fine-Grained Saturation Sweep (n=3)
A separate high-resolution sweep around the saturation knee:
| Parameter |
Value |
| Independent runs |
3 |
| Concurrency levels |
500, 550, 600, 650, 700, 750, 800, 850, 900, 950, 1,000 |
| Input tokens |
2,048 |
| Output tokens |
100 |
| Prompts per level |
200 |
Statistical Analysis
- Mean and standard deviation computed across runs at each concurrency level
- 95% confidence intervals computed using the t-distribution at 95% with df = n − 1, appropriate for small sample sizes
- Coefficient of variation (CoV) reported for variance characterization
- All throughput values are total throughput (input + output tokens per second)
Per-Model Configuration
DeepSeek V3.2
| Setting |
Value |
| Precision |
FP8 |
| Tensor Parallelism |
8 |
VLLM_ROCM_USE_AITER |
1 (required) |
--block-size |
1 (required for MLA) |
Llama-3.1-405B
| Setting |
Value |
| Precision |
FP8 |
| Tensor Parallelism |
8 |
| AITER |
Toggle-able (used for ablation) |
Qwen3-VL-235B
| Setting |
Value |
| Precision |
BF16 (FP8 incompatible with ViT) |
| Tensor Parallelism |
8 |
| KV Offloading |
64 GB to system RAM |
Kimi-K2.5
| Setting |
Value |
| Precision |
INT4 QAT (compressed-tensors) |
| Tensor Parallelism |
4 (not 8) |
VLLM_ROCM_USE_AITER |
0 (MXFP4 unavailable on MI325X) |
--block-size |
1 (required for MLA) |
| Container |
rocm/vllm-dev:nightly |