Multi-Run Statistical Analysis
Updated on 11 March, 2026All results below are aggregated from 5 independent benchmark runs per model on 8x AMD Instinct MI325X GPUs. Each run used 100 requests per concurrency level with 2,048 input tokens and 512 output tokens.
All results below are aggregated from 5 independent benchmark runs per model on 8x AMD Instinct MI325X GPUs. Each run used 100 requests per concurrency level with 2,048 input tokens and 512 output tokens.
Summary
| Model | Peak Throughput (mean ± CI95) | Peak Concurrency | p99 Latency (at peak) | Precision | Architecture |
|---|---|---|---|---|---|
| Qwen3-VL-235B-A22B | 11,218 ± 32 tok/s | 1000 | 15.43s | BF16 | MoE + GQA |
| Llama-3.1-405B | 6,808 ± 336 tok/s | 750 | 25.83s | FP8 | Dense + GQA |
| DeepSeek V3.2 | 5,786 ± 842 tok/s | 1000 | 23.01s | FP8 | MoE + MLA |
| Kimi-K2.5 | 952 ± 4 tok/s | 1000 | 182.52s | INT4 QAT | MoE + MLA |
Peak Throughput Comparison
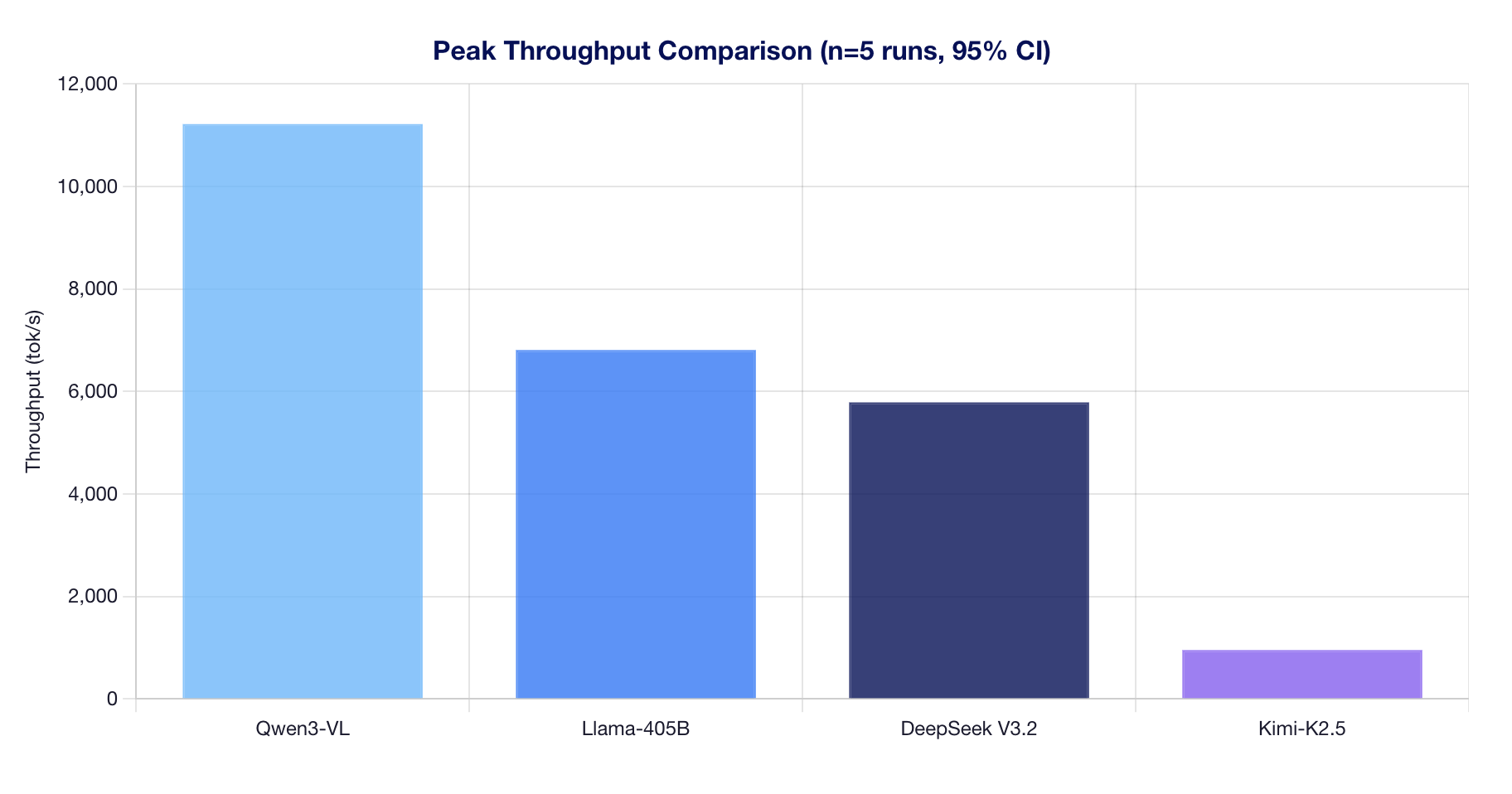
Methodology: Peak throughput is the highest mean throughput observed across all tested concurrency levels (10 to 1,000). Error bars represent 95% confidence intervals.
Throughput vs Concurrency
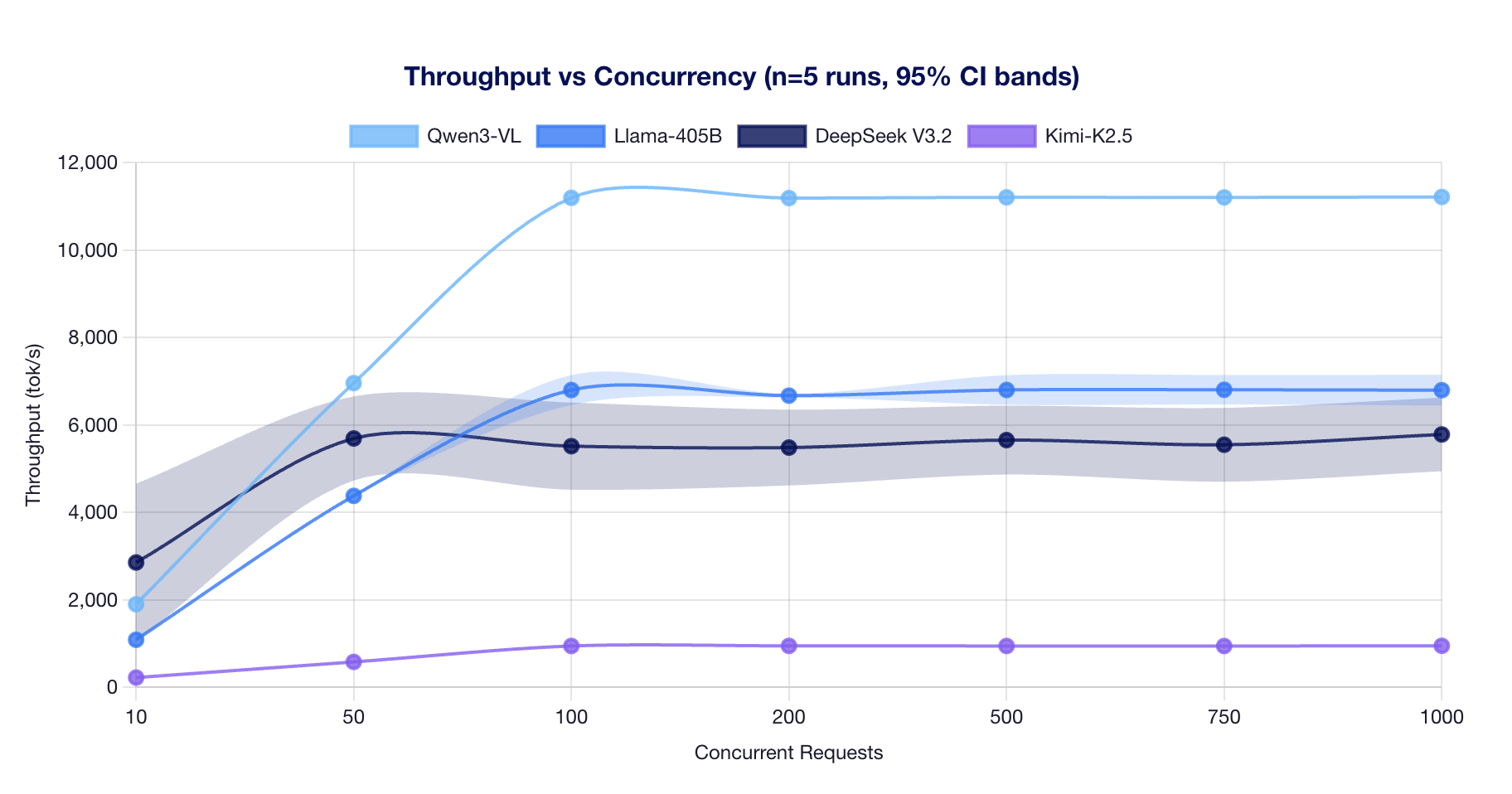
Observations:
- Qwen3-VL-235B saturates at ~100 concurrent and plateaus at ~11,200 tok/s. Its MoE architecture (22B active params) enables efficient batching.
- Llama-3.1-405B saturates at ~100 concurrent and holds steady at ~6,800 tok/s. Dense GQA architecture provides consistent performance.
- DeepSeek V3.2 reaches ~5,700 tok/s at 50 concurrent with high variance (CoV ~14%). MLA attention creates scheduling variability.
- Kimi-K2.5 saturates early at ~100 concurrent (~950 tok/s). Running on TP=4 with AITER disabled limits throughput.
p99 Latency vs Concurrency
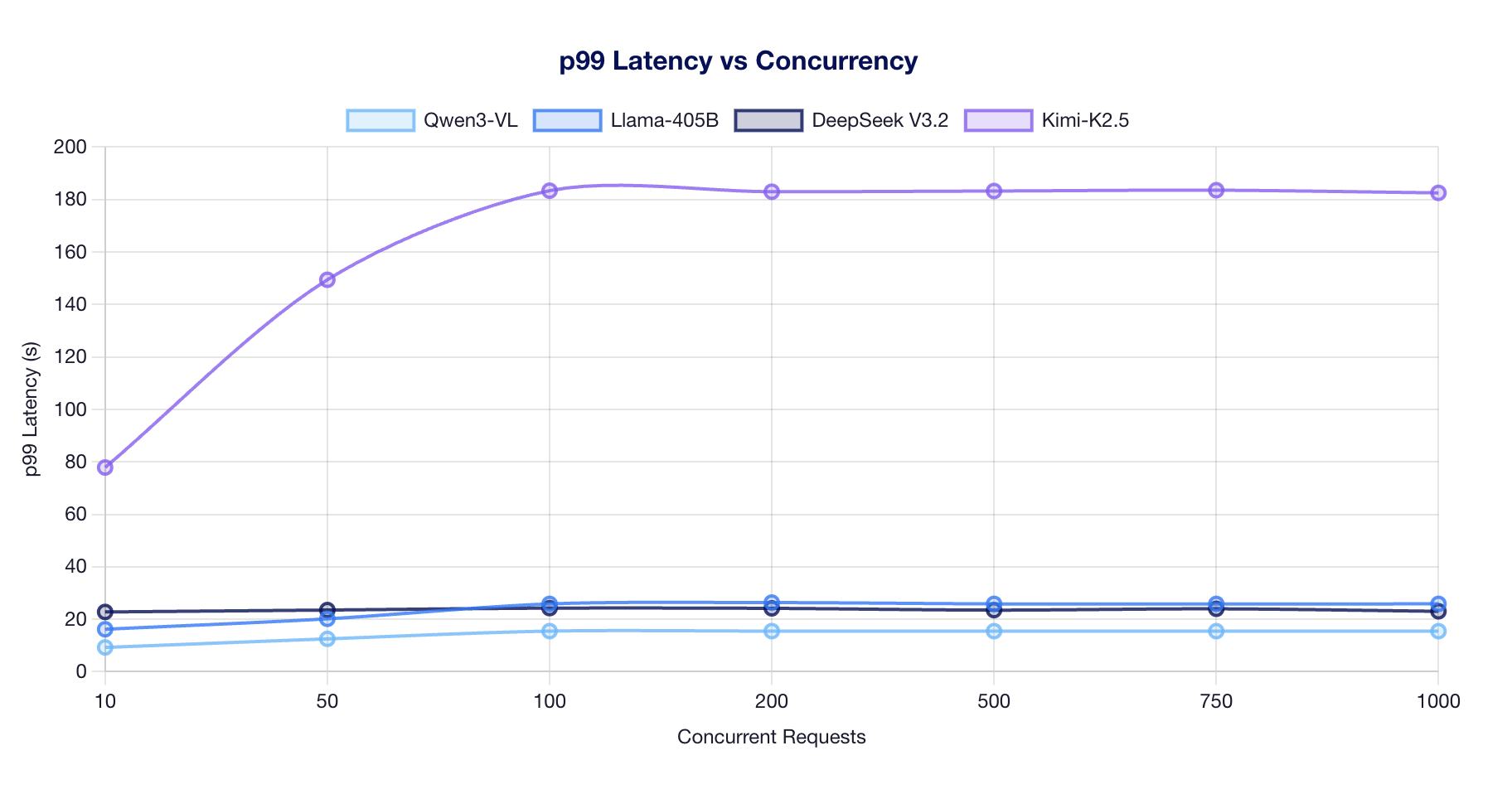
Observations:
- Qwen3-VL maintains the lowest latency (~15s) across all concurrency levels, benefiting from small active parameter count (22B).
- Llama-405B and DeepSeek V3.2 cluster around 20-26s p99, reflecting their larger active parameter footprints.
- Kimi-K2.5 shows the highest latency (77-183s) due to running on only 4 GPUs (TP=4) with AITER disabled.
Key Takeaways
- Active parameters predict throughput better than total parameters. Qwen3-VL (22B active) outperforms Llama-405B (405B active) by ~1.6x despite being nominally smaller.
- All models saturate by ~100-200 concurrent requests on 8x MI325X, with throughput plateauing beyond that point.
- MLA models show higher variance (DeepSeek CoV ~14% vs Llama CoV ~0.2%) due to sparse attention scheduling complexity.
- MoE with GQA (Qwen3-VL) is the optimal combination for throughput on MI325X, achieving 11,218 tok/s at 1,000 concurrent.