GPU Memory Profiling
Updated on 11 March, 2026Detailed GPU memory measurements for all 4 models running on AMD Instinct MI325X GPUs (256 GB HBM3e per GPU). Measurements taken via `rocm-smi` after model loading and warmup completion.
Memory Usage Overview
Memory Breakdown
| Model | Precision | TP | Model Weights (GB) | Per-GPU VRAM (GB) | Total VRAM (GB) | GPUs Used |
|---|---|---|---|---|---|---|
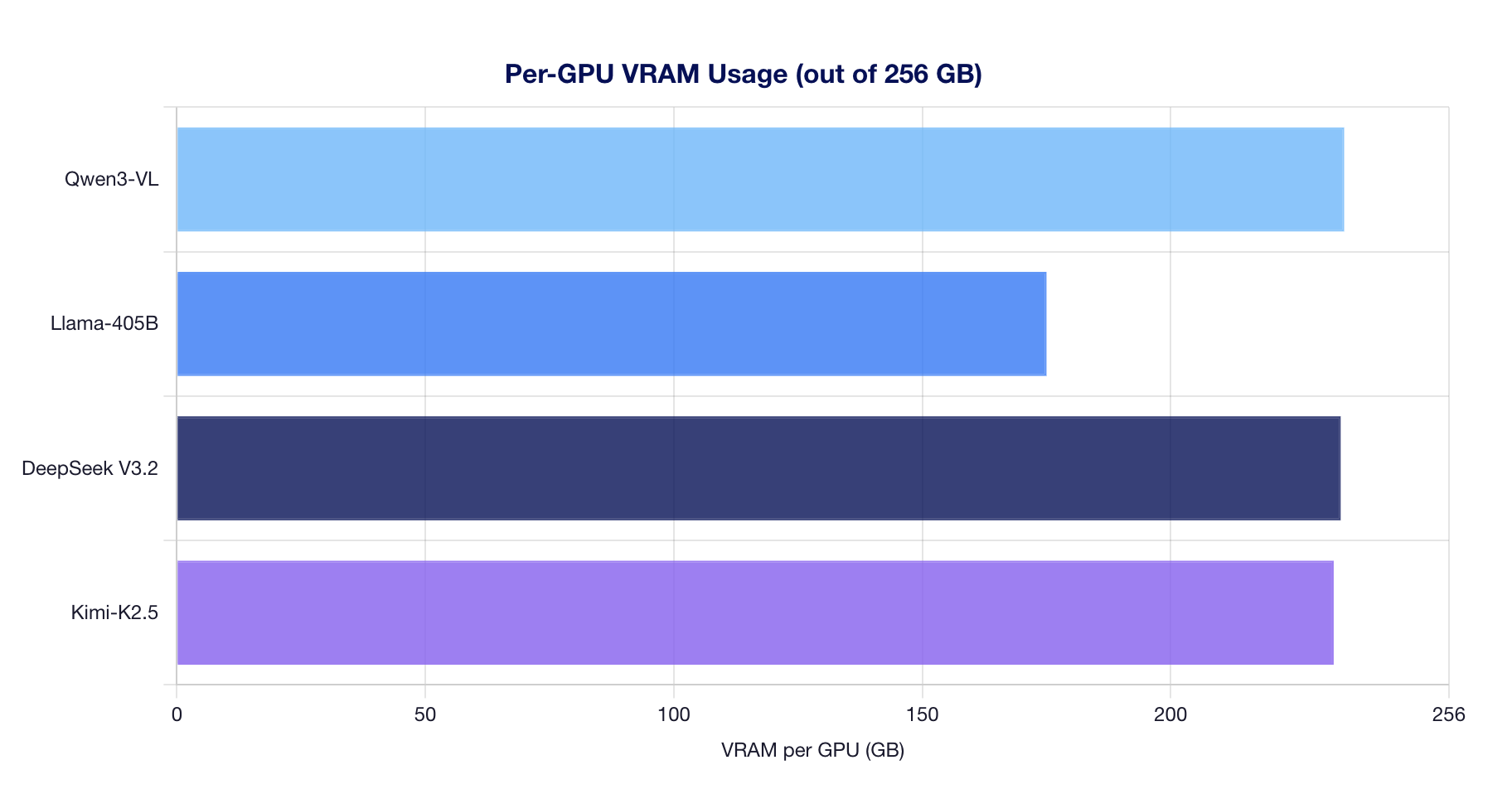
| Qwen3-VL-235B-A22B | BF16 | 8 | 163.3 | 234.9 | 1879.4 | 8 |
| Llama-3.1-405B | FP8 | 8 | 111.0 | 175.0 | 1399.8 | 8 |
| DeepSeek V3.2 | FP8 | 8 | 140.0 | 234.2 | 1873.8 | 8 |
| Kimi-K2.5 | INT4 QAT | 4 | 145.2 | 232.8 | NaN |
Notes:
- "Per-GPU VRAM" includes model weights + KV cache + CUDA graph buffers + runtime overhead
- Kimi-K2.5 uses TP=4 (only 4 GPUs), while all other models use TP=8
- Total VRAM much larger than model weights because vLLM pre-allocates KV cache to fill available memory
Key Observations
MI325X Memory Capacity Enables Large Models
With 256 GB per GPU, the MI325X provides substantial headroom:
| Model | Per-GPU Weights | Per-GPU Total | Headroom |
|---|---|---|---|
| Qwen3-VL-235B (BF16) | ~58 GB | ~235 GB | 21 GB |
| Llama-405B (FP8) | ~112 GB | ~175 GB | 81 GB |
| DeepSeek V3.2 (FP8) | ~83 GB | ~234 GB | 22 GB |
| Kimi-K2.5 (INT4 QAT) | ~145 GB | ~233 GB | 23 GB |
KV Cache Fills Available Memory
vLLM automatically allocates all remaining GPU memory to KV cache after model loading. This is optimal behavior -- more KV cache means more concurrent requests can be served without eviction.
FP8 Quantization Reduces Model Footprint
Llama-405B benefits significantly from FP8:
- FP8: ~112 GB weights (14 GB per GPU with TP=8)
- BF16 estimate: ~810 GB weights (would not fit on 8x MI325X without offloading)
DeepSeek V3.2 at FP8 uses ~83 GB for a 685B parameter model, demonstrating efficient MoE weight distribution.
Kimi-K2.5: Largest Per-GPU Weight Footprint
Despite INT4 QAT quantization, Kimi-K2.5 uses the most weight memory per GPU (~145 GB) because:
- 1T total parameters with 384 expert MLPs
- Only 4 GPUs (TP=4), so each GPU holds more weight shards
- Compressed-tensors format with mixed precision components